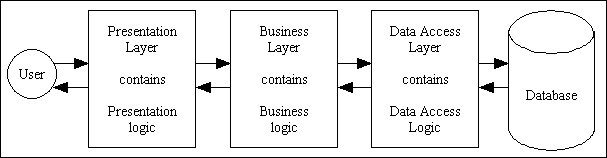
Figure 1 - The 3-Tier Architecture
I have been a computer programmer for several decades during which I have worked with many companies, many teams, more than a few programming languages, a variety of hardware (mainframes, mini-computers and micro-computers), several file systems (flat files, indexed files, hierarchical databases, network databases and relational databases), many projects, many development standards, and several programming paradigms (procedural (COBOL), component based (UNIFACE) and object oriented (PHP). I have worked with punched card, paper tape, teletypes, dumb terminals (green screens) working in both character mode and block mode, and Personal Computers. I have written applications which run on the desktop as well as the internet. I have progressed from writing programs from other people's designs and specifications to designing and building entire applications which I either build myself or as the lead developer in a small team. I have also designed and built 3 frameworks in 3 different languages to aid in the development process.
Ever since I started programming with the Object Oriented paradigm I have noticed a disturbing trend in the amount of code which is supposed to be written in order to achieve a result. This is, in my humble opinion, a direct result of the purely dogmatic approach where a small group of self-styled "experts" try to enforce their personal programming style and artificial rules on everybody else in a totally dictatorial manner. In this article I will attempt to explain why I much prefer a more pragmatic approach in which the aim is to produce a satisfactory result with as little effort as possible.
It is my feeling that too many of today's programmers have forgotten the original and fundamental principles of computer programming and spend too much time in dreaming up new levels of complexity in order to make themselves appear more clever, more cool, and more acceptable to those whom they regard as their peers. It is my humble opinion that these extra levels of complexity are introduced by people who are trying to mask their underlying lack of programming skill. By making something appear to be more complex than it really is they are demonstrating a complete lack of understanding of both the problem and the solution.
In this article I will show why I choose to ignore all these unnecessary complexities yet am still able to produce effective results. I prefer to stick to old school principles and I don't embrace any new ideas unless I can see the benefit of doing so. My starting point is a simple fact which a lot of people seem to be unaware:
The primary function of a software developer is to develop cost-effective software for the benefit of the end user, not to impress other developers with the supposed cleverness of their code.
I am not alone in this opinion. In his blog post The narrow path between best practices and over-engineering Juri Strumpflohner writes:
What many software engineers often forget, is what we are here for after all: to serve the customer's need; to automate complex operations and to facilitate, not complicate, his life. Obviously we are the technicians and we therefore need to do our best to avoid technical deadlocks, cost explosions etc. But we are not here to create the architectures of our dreams. Too often I have the feeling that we would be better served to invest our time in more intuitive, damn simple user interfaces rather than complex back end architectures.
Writing software that does not solve the customer's problem in a cost-effective manner, and which cannot be understood and therefore maintained by developers of lesser ability, is a big mistake, and it does not matter that you and your fellow developers wax lyrical over the brilliant architecture, the number of classes, the number of design patterns, the number of layers of indirection, or the number of clever, fancy or esoteric features and functions that you have crammed into your design or your code.
Another simple fact which I learnt early on in my career and which I strive to follow at every possible opportunity is:
The best solution is almost always the simplest solution.
A truly skilled engineer will always strive to produce a solution which is simple and elegant while others can do no more than produce eccentric machines in the style of Heath Robinson or Rube Goldberg. Too many people look at a task which is well-established yet manual (simple) and assume that it needs to be updated into something more modern and automated (complex) with all the latest go-faster-stripes with bells-and-whistles. They become so obsessed with making it "modern" they lose sight of the fact that their "improvements" make their solution more complicated than the original problem. A prime example of this is the automatic light bulb changer which is an ugly monstrosity with over 200 parts. Hands up those who would prefer to stick to the "old fashioned" way of changing a light bulb? (1) Unscrew old bulb, (2) Screw in replacement bulb.
Many wise people had said many things about the idea that "simple is best", some of which are documented in Quotations in support of Simplicity.
The approach which I have learned to follow throughout my long career is based on the idea that the best solution is the simplest solution as well as the smallest solution. This philosophy is known as "minimalism" as it fits this description from wikipedia:
Minimalism is any design or style wherein the simplest and fewest elements are used to create the maximum effect.
In his book "Minimum" John Pawson describes it thus:
The minimum could be defined as the perfection that an artefact achieves when it is no longer possible to improve it by subtraction. This is the quality that an object has when every component, every detail, and every junction has been reduced or condensed to the essentials. It is the result of the omission of the inessentials.
Russ Miles, in his talk Without Simplicity, There Is no Agility, provided the following description:
Simplicity is reduction to the point that any further reduction will remove important value.
Minimalism is not a concept which is confined to just art and architecture, it can be applied to any area which involves design, whether it be buildings, cars or software. Anything which can be designed can be over-designed into something which is over-complicated. The trick is to spot those complications which are not actually necessary, and remove them. Unfortunately it seems that few people have the ability to look at an area of complexity and decide that it is more complex than it could be. They are told by others that it has to be that complex because there is no other way.
So there it is is a nutshell - include what is necessary and exclude what is unnecessary. If you can remove something and your program still works, then what you removed was effectively useless and redundant. In the remainder of this document I will highlight those specific areas where I cut out the crap excess fat and produce code which is lean and mean.
Which is best - simplicity or complexity? How much code should write - little or lots? Here are some quotations from various famous or not-so-famous people:
Simplicity is the soul of efficiency.
All that is complex is not useful. All that is useful is simple.
Everything should be made as simple as possible, but not simpler.
Some people seem to have difficulty understanding what the phrase "but not simpler" actually means. If something is too simple then it won't actually work, so you should only add complexity in small increments until you have something that works, and then you stop adding.
Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius - and a lot of courage - to move in the opposite direction.
To arrive at the simple is difficult.
The unavoidable price of reliability is simplicity.
Simplicity is prerequisite for reliability.
Simplicity does not precede complexity, but follows it.
Technical skill is mastery of complexity, while creativity is mastery of simplicity.
Complexity means distracted effort. Simplicity means focused effort.
A complex system that works is invariably found to have evolved from a simple system that works.
There are two ways of constructing a software design. One way is to make it so simple that there are obviously no deficiencies. And the other way is to make it so complicated that there are no obvious deficiencies.
...Simplifications have had a much greater long-range scientific impact than individual feats of ingenuity. The opportunity for simplification is very encouraging, because in all examples that come to mind the simple and elegant systems tend to be easier and faster to design and get right, more efficient in execution, and much more reliable than the more contrived contraptions that have to be debugged into some degree of acceptability.... Simplicity and elegance are unpopular because they require hard work and discipline to achieve and education to be appreciated.
Less is more.
Remember that there is no code faster than no code.
The cheapest, fastest, and most reliable components of a computer system are those that aren't there.
The ability to simplify means to eliminate the unnecessary so that the necessary may speak.
Perfection (in design) is achieved not when there is nothing more to add, but rather when there is nothing more to take away.
I have yet to see any problem, however complicated, which, when you looked at it in the right way, did not become still more complicated.
Smart data structures and dumb code works a lot better than the other way around.
[...] the purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.
... the cost of adding a feature isn't just the time it takes to code it. The cost also includes the addition of an obstacle to future expansion. ... The trick is to pick the features that don't fight each other.
One of the most dangerous (and evil) things ever injected into the project world is the notion of process maturity. Process maturity is for replicable manufacturing contexts. Projects are one-time shots. Replicability is never the primary issue on one-time shots. More evil than good has come from the notion that we should "stick to the methodology." This is a recipe for non-adaptive death. I'd rather die by commission.
Fools ignore complexity; pragmatists suffer it; experts avoid it; geniuses remove it.
Controlling complexity is the essence of computer programming.
Complexity is a sign of technical immaturity. Simplicity of use is the real sign of a well design product whether it is an ATM or a Patriot missile.
Complexity kills. It sucks the life out of developers, it makes products difficult to plan, build and test, it introduces security challenges and it causes end-user and administrator frustration. ...[we should] explore and embrace techniques to reduce complexity.
The inherent complexity of a software system is related to the problem it is trying to solve. The actual complexity is related to the size and structure of the software system as actually built. The difference is a measure of the inability to match the solution to the problem.
Increasingly, people seem to misinterpret complexity as sophistication, which is baffling --- the incomprehensible should cause suspicion rather than admiration. Possibly this trend results from a mistaken belief that using a somewhat mysterious device confers an aura of power on the user.
That simplicity is the ultimate sophistication. What we meant by that was when you start looking at a problem and it seems really simple with all these simple solutions, you don't really understand the complexity of the problem. And your solutions are way too oversimplified, and they don't work. Then you get into the problem, and you see it's really complicated. And you come up with all these convoluted solutions. That's sort of the middle, and that's where most people stop, and the solutions tend to work for a while. But the really great person will keep on going and find, sort of, the key, underlying principle of the problem. And come up with a beautiful elegant solution that works.
If you cannot grok the overall structure of a program while taking a shower, you are not ready to code it.
Beauty is more important in computing than anywhere else in technology because software is so complicated. Beauty is the ultimate defense against complexity.
When I am working on a problem, I never think about beauty. I think only of how to solve the problem. But when I have finished, if the solution is not beautiful, I know it is wrong.
So the general consensus here is that if you have a choice between a complex solution and a simple solution the wisest person will always go for the simplest solution. The unwise will go for the complex solution in the belief that it will impress others in positions of influence. They think it makes them look "clever", when in reality it is "too clever by half". This is called over-engineering and if often caused by feature creep. The other choice is to go for only enough code that will actually do the job and not to dress it up with unnecessary frills, frivolities or flamboyancies. This also means using as few classes and design patterns as is necessary and not as many as is possible.
If you do not like the idea that "less is better" then consider the fact that more than a few programmers have noticed that OO code runs slower than non-OO code. This is not because the use of classes and objects is slower per se, the actual culprit is the sheer volume of extra and unnecessary code. If you try using just enough classes and just enough code to get the job done then you will see timings that aren't so bloated.
The journey from novice to experienced programmer is not something which can be achieved overnight. It is not just a simple matter of learning a list of principles, it is how you put those principles into practice which really counts. Someone may be able to learn the wording of these principles and repeat them back to you parrot fashion, but without the ability to put those words into action the results will always be unsatisfactory. This journey can be simplified into the following stages:
To work or be Effective is defined as:
adequate to accomplish a purpose; producing the intended or expected result.
Clearly a program that produces the wrong result, or produces a result that nobody wants, or takes too long to produce its result is going to have very little value.
Efficient is defined as:
The accomplishment of or ability to accomplish a job with a minimum expenditure of time and effort.
There are actually several areas where efficiency can be measured in a computer program:
Maintainable is defined as:
The ease with which a software system or component can be modified to correct faults, improve performance or other attributes, or adapt to a changed environment.
It is extremely rare for a program to be written, then be run for a long period of time without someone, who may or may not be the original author, examining the code in order to see how it does what it does so that either a bug can be fixed or a change can be made. Code which cannot be maintained is a liability, not an asset. If it cannot easily be fixed or enhanced then it can only be replaced, and code which has to be replaced has no value, regardless of how well it was supposedly written.
It is therefore vitally important that those who have proven their skill in the art of software development can pass on their knowledge to the next generation. However, there are too many out there who think they are skilled for no other reason than they know all the latest buzzwords and fashionable techniques. These people can "talk the talk", but they cannot "walk the walk". They may know lots of words and lots of theories, but they lack the ability to translate those words into simple, effective architectures and simple, effective and maintainable code.
Some people equate "maintainable" as adhering to a particular set of detailed standards or "best practices". Unfortunately a large percentage of these standards go beyond what is absolutely necessary and are filled with too much trivial detail and waste time on nit-picking irrelevances. This theme is explored further in Best Practices, not Excess Practices.
An apprentice cannot become a master simply by being taught, he has to learn. Learning comes from experience, from trial and error. Here is a good description of experience:
Experience helps to prevent you from making mistakes. You gain experience by making mistakes.
In his article Write code that is easy to delete, not easy to extend the author describes experience as follows:
Becoming a professional software developer is accumulating a back-catalogue of regrets and mistakes. You learn nothing from success. It is not that you know what good code looks like, but the scars of bad code are fresh in your mind.
Despite what people say it is impossible to produce "perfect" software, the primary reason being that nobody can define exactly what "perfect" actually means. However, if you ask a group of developers to define "imperfect" software the only consistent phrase you will hear is "software not written by me" or possibly "software not written to standards approved by me".
All software is a compromise between several factors - what the user wants, when they want it, and how much they are prepared to pay for it. The quality of a solution often depends on how many resources you throw at it, so if the resources are limited then you have no choice but to do the best you can within those limitations.
Another factor that should be taken into consideration when calculating the cost of a piece of software is the cost of the hardware on which it will run. A piece of software which is 10% cheaper than its nearest rival may not actually be that attractive if it requires hardware which is 200% more expensive.
All these factors - cost of development, speed of development, hardware costs, effectiveness of the solution - must be weighed in the balance and be the subject of a Cost-Benefit Analysis in order to determine how to get the most bang for your buck. Spending 1 penny to save £1 would be a good investment, but spending £1 to save a penny would not. If the cost of a mathematical program doubles for each decimal place of precision then instead of asking "How many decimal places do I want?" the customer should ask the question "How many decimal places can I afford?" as well as "How many decimal places do I need?" If a GPS system which can pinpoint your position to within 25 feet of accuracy costs £100, but one which gives 1 foot of accuracy costs £1,000 then the level of precision which you can expect is limited by your budget and not the skill of the person who built the device.
The cost of a piece of software should be gauged against its value or how much money it will save over a period of time. This is sometimes known as Return On Investment (ROI). If a piece of software can reduce costs to the extent that it can pay for itself in a short space of time, then after that time has elapsed you will be in profit and this will be considered to be a good investment. However, if this time period stretches into decades then the ROI will be less attractive. The savings which a piece of software may produce may be classified as follows:
Another point to keep in mind about being cost effective is to do enough work to complete the task and then stop. Clayton Neff pointed out in his article When is Enough, Enough? that there are some programmers out there who always think that what they have produced is not quite perfect, and all they need to do is tidy it up a bit here, refactor it a bit there, add in another design pattern here, tweak it a bit there, and only then will it be perfect. Unfortunately perfection is difficult to achieve because it means different things to different people, so what seems perfect to one programmer may seem putrid to another. What seems perfect today may seem putrid tomorrow. Refactoring the code may not actually make it better, just different, and unless you are actually fixing a bug or adding in a new feature you should not be working on the code at all. It is not unknown for a simple piece of unwarranted refactoring to actually introduce bugs instead of improvements, so if it ain't broke don't fix it.
In my long career I have encountered numerous people whose basic understanding of the art of software development is simply wrong, and if you can't get the basics right then you are building on shaky foundations and creating a disaster that is waiting to happen. Some of these misunderstandings are described in the following sections.
Although computer programmers like to call themselves "software engineers" nowadays, a lot of them are nothing more than "fitters" or "apprentice engineers". So what's the difference?
A fitter is to an engineer as a monkey is to an organ grinder. Someone who assembles flat-pack furniture cannot call himself a cabinet-maker or a carpenter.
If a programmer is incapable of writing a program without the aid of someone else's framework, then he's not an engineer, he's a fitter.
If a programmer is incapable of building his own framework, then he's not an engineer, he's a fitter.
If a programmer is incapable of writing software without the use of a collection of third-party libraries, then he's not an engineer, he's a fitter.
If a programmer finds a fault in a third-party library, but is unable to find the fault and fix it himself, then he's not an engineer, he's a fitter.
If a programmer can only work from other people's designs, then he's not an master engineer, he's an apprentice.
If a programmer can only design small parts of an application and not an entire application, then he's not an engineer, he's an apprentice.
The term dogmatic is defined as follows:
Asserting opinions in a doctrinaire or arrogant manner; opinionated - dictionary.com
Characterized by an authoritative, arrogant assertion of unproved or unprovable principles - thefreedictionary.com
(of a statement, opinion, etc) forcibly asserted as if authoritative and unchallengeable - collinsdictionary.com
The term pragmatic is defined as follows:
Action or policy dictated by consideration of the immediate practical consequences rather than by theory or dogma - dictionary.com
The term heretic is defined as follows:
anyone who does not conform to an established attitude, doctrine, or principle - dictionary.com
In any sphere of human endeavour you will find that someone identifies a target or goal to be reached (such as developing better software through OOP) and then identifies a set of guidelines to help others reach the same goal. Unfortunately other people come along and interpret these "guidelines" as being "rules" which must be followed at all times and without question. Yet more people come along and offer different interpretations of these rules, and some go as far as inventing completely new rules which other people then reinterpret into something else entirely. And so on ad nauseam ad infinitum. You end up with the situation where you cannot see the target because it is buried under mountains of rules. The dogmatist will follow the rules blindly and assume that he will hit the target eventually. The pragmatist will identify the target, and ignore all those rules which he sees as nothing but obstructions or impediments. The pragmatist will therefore reach the target sooner and with less effort.
Working with programmers of different skill levels but who are willing to learn is one thing, but trying to deal with those whose ideas run contrary to your own personal (and in my case, extensive) experience can sometimes be exasperating, especially when they try to enforce those ideas onto you in a purely dogmatic and dictatorial fashion. They seem to think that their rules, methodologies and "best practices" are absolutely sacrosanct and must be followed by the masses to the letter without question and without dissension. They criticise severely anyone who dares to challenge their beliefs, and anyone who dares to try anything different, or deviate from the authorised path, is branded as a heretic. As a pragmatic programmer I don't follow rules blindly and assume that the results must be acceptable, I concentrate on achieving the best result possible with the resources available to me, and I will adopt, adapt or discard any methodologies, practices or artificial/personal rules as I see fit. This may upset the dogmatists, but I'm afraid that their opinions are less relevant than those of the end user, the paying customer.
This attitude that everyone must follow a single set of rules, regardless of the consequences, just to conform to someone's idea of "purity" is not, in my humble opinion, having the effect of increasing the pool of quality programmers. Instead it is achieving the opposite - by stifling dissent, by stifling experimentation with anything other then the "approved" way, it is leading an entire generation of programmers down the wrong path.
Progress comes from innovation, not stagnation. Innovation comes from trying something different. If you are not allowed to try anything different then how can it be possible to make progress?
This means that the pragmatic programmer, by not following the rules laid down by the dogmatists, is automatically branded a heretic.
This also means that the dogmatic programmer, by disallowing experimentation and innovation, is impeding progress by perpetuating the current state of affairs.
There are two types of person in this world:
Dogmatists and pedants fall into the first category. They only know what they have been taught and never bother trying to learn anything for themselves. They never investigate if there are any alternative methods which may produce better or even comparable results. They have closed minds and do not like their beliefs being questioned. They are taught one method and blindly believe that it is the only method that should be followed. They automatically consider different methods as wrong even though they may achieve the exact same result - that of effective software. They refuse to consider or even discuss the merits of alternative methodologies and dismiss these alternative thinkers as either non-believers who should be ignored, or heretics who should be burned at the stake. They are taught a method or technique which may have benefits under certain circumstances and blindly use that method or technique under all circumstances without checking that they actually have the problem for which the solution was designed to solve. The indiscriminate use of a method or technique shows a distinct lack of thought regarding the problem, and if the problem has not been thought out thoroughly then how can you be confident that the solution actually solves the problem in the most effective manner, or even solves it at all? If you ask a dogmatist why a particular rule, methodology or technique should be followed he will simply say "Because it is the way it is done!" but he will not be able to explain why it is better than any of the alternatives.
Pragmatists do not accept anything at face value. They have open minds and will want to question everything. They listen to what they have been taught and use this as the first step, not the only step, in the journey for knowledge. If they hear about a new technique, approach or methodology they will examine it and perhaps play with it to see if the hype is actually justified. If they come across anything which has merit, even in limited circumstances, then they will use that new technique in preference to something older and more established. A pragmatist has the experience to know whether a new technique offers a better solution or merely a more complicated solution, and will always favor the simple over the complex even when others around him proclaim "this is the way of the future". He is prepared to experiment, adapt to changing circumstances and adopt new techniques while others stick to their "one true way". He will not jump on the bandwagon and adopt a technique just because it is the buzzword of the day - he will consider the merits, and if they fall short he will ignore it even in the face of criticism from others. A pragmatist has the ability to see through the hype and get to the heart of the matter.
Here are some differences between being taught and learning:
Remember that software development is a fast-changing world, so today's best practice may be tomorrow's impediment. Someone who is not prepared to try or even discuss alternative techniques may find themselves clinging to the old ways long after everyone else has moved on and left them far behind.
A great number of people fail to realise the fact that computer programming is an art, not a science. So what is the difference?
For example, take a battery, two wires and a container of water. Connect one end of each wire to the battery and place the other end in the water. Bubbles of hydrogen gas will appear on the negative wire (cathode) while bubbles of oxygen will appear on the positive wire (anode). This scientific experiment can be duplicated by any child in any school laboratory with exactly the same result. Guaranteed. Every time.
Art, on the other hand, is all about talent. It cannot be taught - you either have it or you don't. You may have a little talent, or you may have lots of talent. The more talent the artist has then the larger the audience who will likely appreciate his work, and the more value his work will be perceived to have. Those with little or no talent will produce work of little or no value. An artist can take a lump of clay and mould it into something beautiful. A non-artist can take a lump of clay and mould it into - another lump of clay. A skilled sculptor can take a hammer and chisel to a piece of stone and produce a beautiful statue. An unskilled novice can take a hammer and chisel to a large piece of stone and produce a pile of little pieces of stone. It is not possible to teach an art to someone who does not have the basic talent to begin with. You cannot give a book on how to play the piano to a non-talented individual and expect them to become a concert pianist. You cannot give a book on how to write novels to a non-talented individual and expect them to become a novelist.
There are some disciplines which require a combination of art and science. Take the construction of bridges or buildings, for example: scientific principles are required to ensure the structure will be able to bear the necessary loads without falling down, but artistic talent is required to make it look good. An ugly structure will not win many admirers, and will not enhance the architect's reputation and win repeat business. Nor will a beautiful structure which collapses shortly after being built. A beautiful structure may be maintained for centuries, whereas an ugly one may be demolished within a few years.
Computer programming requires talent - the more talent the better the programmer. Writing a program is about taking an instruction manual that a human being can understand and translating it into an instruction manual that a computer can understand. It does not involve the simple conversion of the syntax of one language into the syntax of another. A computer can only understand binary where each instruction is a collection of bits which are either ON or OFF, either 0 (zero) or 1 (one). Nobody writes binary code any more, they use an intermediate programming language which converts human-readable instructions into binary. The number of programming languages is immense, with their syntax being as different as Greek is to Chinese or to Egyptian hieroglyphs. There are different languages for different purposes, such as COBOL (COmmon Business-Oriented Language) for writing business applications, and FORTRAN (FORmula TRANslation) for mathematicians. While most of these languages provide features which aid in the production of software which is efficient and secure they are still unable to prevent bad programmers from writing bad code. This lead to the observation that You Can Write FORTRAN in any Language.
Writing a program is like writing a book - it is a work of authorship. Writing a book that people will pay to read is not a simple matter of throwing thousands of words together which obey the rules of grammar. A book must either entertain, inform or educate, it must be either fact or fiction. Writing a program means taking high-level instructions written in a natural language and converting them into a low-level instructions in a computer language. If you take the instructions given to an office worker on how to produce an invoice from a sales order and then compare them with the equivalent instructions given to a computer you will see a huge difference. A computer may be significantly faster than a human, but it is still an idiot in that it can only do what is was programmed to do. It follows its instructions to the letter, and if there is anything wrong or missing in those instructions then the results will probably be unexpected. While a human being will probably stop after realising that a mistake has been made, a computer will carry on repeating that mistake thousands of times a second until it is told to stop. This has led to the saying To err is human, but to really screw things up you need a computer
.
A successful programmer does not have to be a member of Mensa or even have a Computer Science degree, but neither should he be a candidate for the laughing academy or funny farm. A programmer must have a logical mind and must be able to think like a computer. Although the programmer has to work within the limitations of the underlying hardware and the associated software (operating system, programming language, tool sets, database, et cetera), the biggest limitation by far is his/her own intellect, talent and skill. Writing software can be described as taking an instruction manual that was written for a human being to understand and translating it into an instruction manual that a computer can understand. Computers can only understand machine code, which is binary, so they require the use of an intermediate programming language, of which there are many.
A computer does not have any intelligence of its own, it is simply a very fast idiot that does exactly what it is told to do, literally, without question and without deviation. If there is something wrong, missing or vague in those instructions then the eventual outcome may not be as expected. The successful programmer must therefore have a logical and structured mind, with an eye for the finest of details, and understand how the computer will attempt to follow the instructions which it has been given. The problem of trying to teach people how to be effective programmers is just like trying to write an instruction manual for humans on how to write instruction manuals for machines. Remember that only one of those two is supposed to be the idiot.
Although there are experienced developers who can describe certain "principles" or techniques which they follow in order to achieve certain results, these principles cannot be implemented effectively by unskilled workers in a robotic fashion. Although a principle may be followed in spirit, the effectiveness of the actual implementation is down to the skill of the individual developer. In the blog post When are design patterns the problem instead of the solution? T. E. D. wrote the following regarding the (over) use of design patterns:
My problem with patterns is that there seems to be a central lie at the core of the concept: The idea that if you can somehow categorize the code experts write, then anyone can write expert code by just recognizing and mechanically applying the categories. That sounds great to managers, as expert software designers are relatively rare. The problem is that it isn't true.
The truth is that you can't write expert-quality code with "design patterns" any more than you can design your own professional fashion designer-quality clothing using only sewing patterns.
The problem with copying what experts do without understanding what exactly it is they are doing and why leads to a condition known as Cargo Cult Programming or Cargo Cult Software Engineering. Just because you mimic the same procedures, processes and design patterns that the experts use does not guarantee that your results will be just as good as theirs.
It is also rare for even a relatively simple computer program to rely on the implementation of a single principle as there are usually several different steps that a program has to perform, and each step may involve a different principle. Writing a computer program involves identifying what steps need to be taken and in what sequence, then writing the code to implement each of those steps in that incredible level of detail required by those idiotic machines. There is no routine to be called or piece of code which can be copied in order to implement a programming principle. You cannot tell the computer to "implement the Single Responsibility Principle" as each implementation has to be written by hand using a different set of variables, and anything which has to be written by hand is down to the skill of the person doing the writing. Different programmers can attempt to follow the same set of principles, but because these principles are open to a great deal of interpretation, and sometimes too much interpretation (and therefore mis-interpretation) they are not guaranteed to produce identical results, so where is the science in that?
Among these principles which are vaguely defined and therefore open to misinterpretation, thereby making them of questionable value, I would put the not-so-SOLID principles:
What is a "single responsibility"? How do you know when a component has too many responsibilities and needs to be split into smaller components? How do you know when to stop splitting? Despite Robert C. Martin clearly stating that the three areas of "responsibility" or "concern" which should be separated are GUI logic, business logic and database logic, there are far too many programmers who continue the separation process to ridiculous extremes. My framework is split into 3 separate layers, and that provides all the separation I need, so I see no justification in splitting it further.
This principle does not properly identify what problem(s) it is trying to solve, and as far as I can see all it does is introduce new problems. It is therefore less problematic to ignore this principle completely.
This entire principle is only relevant if you inherit from a concrete class, but in my framework I only inherit from an abstract class.
This principle is only relevant if you use the keywords "interface" and "implements". These keywords are both optional and unnecessary in the PHP language, and as I choose not to use them in my framework this principle is consequently completely irrelevant.
In the first place the common description of this principle, which is "High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions."
is, in my humble opinion, total garbage. I do not understand what it means. I have never seen any meaningful explanations. I have never seen any code samples which prove that this idea has any worth, so I don't know how to write code which follows this principle or what benefits it will produce. I'm not going to waste my time doing something that has no benefits.
In the second place the author of this principle gives an example in the "Copy" program where its application would be appropriate and provide genuine benefits, but far too many programmers insist on applying this principle in all circumstances whether they are appropriate or not. Eventually I realised that this principle is supposed to be a mechanism to take advantage of polymorphism, where multiple objects share the same method signature. This then allows for the dependent object to be switched at run time in order to produce a different result. If there is no polymorphism this means that there are no alternative objects which then means that providing code to switch to an alternative which does not exist would be a complete waste of time and a violation if YAGNI.
Because every one of my concrete table (Model) classes inherits from the same abstract class it means that they all share the same method signatures. This means that any component which calls one of these signatures (such as a Controller) can access any one of those concrete table classes. There are places in my framework where I do use Dependency Injection, but there are also places where I do not use DI at all.
Although not in SOLID, here is another common principle which I choose to ignore:
This is often stated as "favour composition over inheritance" and is intended to deal with those situations where the over use of inheritance causes problems. As I do not have deep hierarchies, only ever inheriting from a single abstract class, I do not have this problem which means that I don't need this solution.
Some great artists find it difficult to describe their skill in such a way as to allow someone else to produce comparative works. Someone once asked a famous sculptor how it was possible for him to carve such beautiful statues out of a piece of stone. He replied: The statue is already inside the stone. All I have to do is remove the pieces that don't belong.
The great sculptor may describe the tools that he uses and how he holds them to chip away at the stone, but how many of you could follow those "instructions" and produce a work of art instead of a pile of rubble?
If you give the same specification to 10 different programmers and ask them to write the code to implement that specification you will never get results which are absolutely identical, so to expect otherwise would be unrealistic, if not totally foolish. Ask 10 different painters for a picture containing a valley, a tree, a stream, mountains in the background and a cottage in the middle and you will get 10 different paintings, but you could never say that only one of them was "right" while all the others were "wrong". The only way to get identical results would be to use a paint-by-numbers kit, but even though the tasks of the painters would be reduced to that of a robot, all the artistic skill would move to the person designing the kit, and all you you end up with would be multiple copies of the same picture. There is no such thing as a paint-by-numbers kit for software developers, so the quality of the finished work will still rely on the artistic skill of the individual. Besides, multiple copies of the same program is not what you want from your developers.
Some managers seem to think that they can treat their developers as unskilled workers. They seem to think that the analysts and designers do all the creative work, and all you have to do is throw the program specifications at the developers and they will be able to churn out code like unskilled workers on an assembly line.
In his article The Developer/Non-Developer Impedance Mismatch Dustin Marx makes this observation:
Good software development managers recognize that software development can be a highly creative and challenging effort and requires skilled people who take pride in their work. Other not-so-good software managers consider software development to be a technician's job. To them, the software developer is not much more than a typist who speaks a programming language. To these managers, a good enough set of requirements and high-level design should and can be implemented by the lowest paid software developers.
In her article The Art of Programming Erika Heidi says the following:
I see programming as a form of art, but you know: not all artists are the same. As with painters, there are many programmers who only replicate things, never coming up with something original.
Genuine artists are different. They come up with new things, they set new standards for the future, they change the current environment for the better. They are not afraid of critique. The "replicators" will try to let them down, by saying "why creating something new if you can use X or Y"?
Because they are not satisfied with X or Y. Because they want to experiment and try by themselves as a learning tool. Because they want to create, they want to express themselves in code. Because they are just free to do it, even if it's not something big that will change the world.
In his article Mr. Teflon and the Failed Dream of Meritocracy the author Zed Shaw says this:
You can either write software or you can't. [....] Anyone can learn to code, but if you haven't learned to code then it's really not something you can fake. I can find you out by sitting you down and having your write some code while I watch. A faker wouldn't know how to use a text editor, run code, what to type, and other simple basic things. Whether you can do it well is a whole other difficult complex evaluation for an entirely different topic, but the difference between "can code" and "cannot" is easy to spot.
He is saying that being able to write code on it's own does not necessarily turn someone into a programmer. It is the ability to do it well when compared with other programmers that really counts. Anybody can daub coloured oils onto a canvass, but that does not automatically qualify them to be called an artist.
Bruce Eckel makes a profound observation is his article Writing Software is Like ... Writing.
See also "Computer Science" is Not Science and "Software Engineering" is Not Engineering by Findy Services and B. Jacobs.
There is no single community of software developers who use the same language, the same methodologies, the same tool sets, the same standards, who think alike and produce identical works of identical quality. There is instead a mass of individuals with their own levels of artistic and technical skill who, from time to time, may become part of a team, either small or large, within an organisation. The team may strive to work together as a cohesive unit, but each member is still an artist and not a robot who can be pre-programmed to think or function in a standard way. The output of each individual will still be based on his/her individual level of skill and not that of the most skilled member of the team, or even the average level of everyone in the team. A chain is only as strong as its weakest link, and a team is only as strong as its weakest member, so if there are any juniors in the team then it is the responsibility of the seniors to provide training and guidance.
In order for any team to be productive they have to cooperate with each other, and that cooperation can best be achieved by proper discussion and democratic decision making. The wrong way would be for someone to sidestep the democratic process and start imposing rules, disciplines, tool sets or methodologies on the team in a dictatorial or autocratic manner without discussion or agreement. This situation may arise in any of the the following ways:
Technical decisions made by non-technicians should be avoided at all costs as they are invariably the wrong decisions made for the wrong reasons. Every rule should be subject to scrutiny by the team who are expected to follow it, and if found wanting should be rejected. As Petri Kainulainen says in his article We should not enforce decisions that we cannot justify. No developer worth his salt will want to implement an idea that he knows in his heart is wrong. It has been known for developers to quit rather than work in a team that is unable to function effectively due to management interference. All technical decisions, which includes what tools, methodologies and standards to use, should only be made by the technicians within the team who will actually use those tools, methodologies and standards, and only with mutual consent. A group of individuals will find it difficult to work together as a team if they are constantly fighting restrictions and artificial rules imposed on them by bad managers instead of using their skills as software developers.
Enough is just right. More than enough is too much. Too much is not better, it is excessive and wasteful. Those who expend just enough effort to get the job done can be classed as "craftsmen" while those who don't know when to stop can be classed as "cowboys". In software development these cowboys can be so commonplace that they go unnoticed and may even be considered to be the norm.
Are there any professions where cowboys are rare simply because their excesses are deemed to be not only inefficient and unprofessional but even dangerous? One profession that comes to mind is the world of the demolition contractor. These are people who don't blow things up but instead blow them down. They don't make structures explode, they make them implode. They use just enough of the right explosive in the right place to bring the structure down into a neat pile, often with most of the debris falling within the structure's original footprint and the remainder falling within spitting distance. This produces little or no collateral damage to the surrounding area, and leaves a nice pile of debris in one place which can be easily cleaned up. This takes planning, preparation and skill. These men are masters of their craft, they are craftsmen.
A cowboy, on the other hand, is sadly lacking in the planning, preparation and skills department. He doesn't know which explosive is best, or how much to use, or where to put it, so he opts for more than enough (the "brute force" approach) in all the places he can reach. When too much explosive is used, or the wrong explosive is used, or if it's put in the wrong place, the results are always less than optimum. The wrong explosive can sometimes result in the structure being rattled instead of razed. Too much explosive can result in debris being blown large distances and damaging other structures, or perhaps even endangering human life. The cost of the clean-up operation can sometimes be astronomical. The cowboy demolitionist is very quickly spotted and shown the door.
It is easy to spot a cowboy demolitionist as the results of their efforts are clearly visible to everyone. It is less easy to spot a cowboy coder as the results of their efforts come in two parts - how well the code is executed by the computer, and how well the code is understood by the next person who reads it. If that person complains that the code is difficult to understand the author will simply say that the person is not clever enough to understand it. This is wrong - if the average reader cannot understand what has been written then the fault lies with the writer.
In the real world various societies have their own code of conduct which people follow in order to be considered as "good citizens" by their neighbours. While the overall message can be summarised as "do unto others as you would have them do unto you" it goes into finer detail with rules such as "thou shalt not kill" and "thou shalt not steal". Some of these rules may be enshrined in law so that by breaking the law you are treated as a criminal and taken out of civilised society by being sent to prison. Other aspects of personal behaviour may not be criminal offences, but they will not endear you to your fellow citizens and they will seek either to avoid being in your company or to exclude you from theirs.
The trouble is that the simple code of conduct is not good enough for some people, and they have to expand it into something much larger and much more complex. They invent something called "religion" with a particular deity or deities which must be worshipped, with particular methods, places and particular times of worship. They develop special rituals, ceremonies, incantations, festivals, prayers and music. They develop a mythology in order to explain how we came to be, our place in the universe, et cetera, and what happens in the after-life. Lastly they create a class of people (with themselves as members, of course), known as priests or clergy, who are the controllers of this religion, and they expect everyone to worship through them and pay them for the privilege of doing so. These people do not contribute to society by producing anything of value, unlike the working classes, they simply feed off people's fear of the unknown. They claim that it is only by following their particular brand of religion will you have a pleasant after-life. They take some of the original teachings and rephrase them, sometimes with different or even perverse interpretations, which results in the meaning being twisted into something which the original author would not recognise. They try to outdo each other with their adherence to these extreme interpretations to such an extent that they become More Catholic than the Pope. This is how the original idea that "women should dress modestly" is twisted into "women must cover their whole bodies so that only their eyes are visible". Extremists take this further by inflicting cruel tortures and hideous deaths on non-believers so that they can experience maximum unpleasantness before they reach the after-life. They believe that their teachings are sacrosanct and must not be questioned, so if they believe that geocentrism then woe betide anyone who believes that heliocentrism. If they believe in creationism then woe betide anyone who believes in evolutionism/Darwinism.
Following a particular religion does not automatically make you a good citizen:
Similarly in the world of software there is a definition of a "good programmer" with starts with a simple code of conduct - write code that another human being can read and understand. Similarly there are specific rules to help you reach this objective - "use meaningful function names", "use meaningful variable names", "use a logical structure".
The trouble is that the simple code of conduct is not good enough for some people, and they have to expand it into something much larger and much more complex. They produce various documents known as "standards" or "best practices" which go into more and more levels of detail. They decide whether the names should be in snake_case or camelCase, whether to use tabs or spaces for indentation, the placement of braces, which design patterns to use, how they should be implemented, which framework to use, et cetera. They consider themselves to be experts, the "paradigm police", who have the right to tell others what to do. Their approach is "if you want to be one of us then do what you are told, don't question anything, keep your head down, keep your mouth shut, and don't rock the boat". They delight in using more and more complex structures in order to make it seem that you need special powers or skills in order to be a programmer. They are the high priests of OO and everyone else is expected to worship at their altar. They take some of the original teachings and rephrase them, sometimes with different interpretations, which results in the meaning being twisted into something which the original author would not recognise. This is how the original idea that "encapsulation means implementation hiding" is twisted into "information is part of the implementation, therefore encapsulation also means information hiding". Non-believers like myself are treated as heretics and outcasts, but at least these "priests" do not have the power to burn heretics at the stake (although some of them wish that they did).
Following a particular set of best practices does not automatically make you a good programmer:
I have often been complimented on the readability of my code because I put readability, simplicity and common sense above cleverness and complexity, and the fact that I have chosen to ignore all the latest fashionable trends and practices as they have arisen over the years does not make my code any less readable.
A lot of young developers are often told Don't bother trying to re-invent the wheel
meaning that instead of trying to design and build a solution of their own they should save time by using an existing library or framework which has been written by someone else. This can actually be counter-productive as the novice can spend a lot of time searching for possible solutions and then working out which one is the closest fit for his circumstances. This is then followed by the problem of trying to get different libraries written by different people in different styles to then work together in unison to create a whole "something" instead of just a collection of disparate parts. In the article Reinvent the Wheel! it says that the expression is actually invalid as there is no such thing as a perfect wheel, or a one-size-fits-all wheel, so it is only you who can provide the proper solution for your particular set of circumstances. Instead of using a single existing but ill-fitting solution in its entirety you may actually end up by borrowing bits and pieces from several solutions and add a few new bits of your own, but this is a start. Eventually you will use less and less code that others have written and more and more code that you have written.
The practice of doing nothing than assembling components that other people have written is that you never learn to create components yourself. In other words you will always be a fitter and not an engineer. If you are an novice it is perfectly acceptable to look at samples of what other people have done, but eventually you will have to learn to write your own code. As it says in Are You a Copycat? you should eventually stop being a copyist and start being a creator of original works. You need to learn to think for yourself and stop letting other people do your thinking for you, otherwise you could end up as a Cargo Cult Software Engineer who suffers from the Lemming Effect, the Bandwagon Effect or the Monkey See, Monkey Do syndrome.
If everyone in the whole world was an imitator, a copyist, then the world would stagnate. Progress can only be made through innovation, by trying something different, so anyone who tells you Don't bother thinking for yourself, copy what others have done
is actually putting a block on progress and perpetuating the status quo.
Here are a few personal golden rules which I have followed for a long time, and which have always served me well.
If you have a choice between two possible solutions - a simple one and a complex one - ALWAYS go for the simplest solution. If you don't, then someone who looks at your code and is unable to quickly ascertain how it works is liable to label it as either "magic stuff happens here" or, even worse, "here be dragons!"
This has a more modern variation called Do The Simplest Thing That Could Possibly Work. Some people question the idea of working on something that could only "possibly" work, but they fail to realise that in reality you start by thinking of the simplest possible solution, code it and then you test it. If the test fails then you add a little complexity and test that, and only stop when you have something that actually works. This means that once you have found a solution that works then the only refactoring you should do is to remove complexity, not add in more.
Simple code is easier to understand than complex code, which also makes it easier to maintain. Writing code which is simple and maintainable should always be preferred over writing code which is clever yet difficult to maintain.
The opposite of KISS is KICK or even LMIMCTIRIJTPHCWA.
If you have written a piece of code and later on you find that you need to use it somewhere else, do not take the easy way out and paste a copy of that code in your second location as when you come to update that code you will find that you have multiple copies to maintain, and then it becomes easy to miss out one of the copies. Your program will then continue to execute the old, worn out code instead of the bright and shiny new code. You should instead put that code into a shared library so that you have a single copy which can be referenced from as many places as you like. After making any changes to that single copy in the shared library you will find that those changes are automatically used in every part of your application.
Turning a block of code into a reusable routine takes skill and effort, but it is a genuine investment. In my career I have known several developers who were too lazy to make the effort, or who couldn't see the point, and they wondered why I didn't rate their skills very highly. In one of my early projects as a junior programmer I was prevented from adding to the routine library simply because the project leader refused to create one. This state of affairs was not rectified until I became leader of my own project and could build my own shared library, after which my library of routines quickly grew until it became a full-blown framework.
However, do not take this idea too far and use it on blocks of code which are less than 5 lines long. Just because your program contains lots of places where a variable is incremented by 1 is no excuse to put that "add 1 to x" into its own routine. Unless the code is particularly complex I view any function, routine or method which has 5 or less lines with deep suspicion.
You should concentrate your efforts on what you actually need today and ignore those things which you think may be useful at some time in the future. When the future eventually arrives it has a habit of looking completely different from how you envisaged it in the past, so all that effort you made was completely wasted. Stick to the requirements as they are known today, and leave the future to the future.
A variation on this theme is Just Sufficient Implementation.
If something works then avoid the temptation to tinker with it just to make it work better as the act of tinkering is liable to break something. Once a program has been completed and signed off you should leave it alone and not touch it again until it becomes the subject of a Change Request. This idea is echoed in When is Enough, Enough?
This completely contradicts the modern philosophy which states that you should keep refactoring your code until it is perfect. In the first place nobody can define what "perfect" actually means as it is a totally subjective concept. In the second place if you spend any amount of time on a program and when you have finished it does nothing more than what it did before you changed it, then that time has been totally wasted. You would have great difficulty in justifying this wasted time to your paymasters, especially when there are genuine problems which should have a far higher priority than a little bit of tinkering with something that ain't broke.
On more than one occasion someone has tried to point out where there is something wrong with my code which needs to be fixed, but on closer examination the "problem" doesn't actually exist (except in his tiny mind). In these cases any time spent on implementing a solution would be time wasted as it doesn't actually make the code run faster or more reliably. Amongst these so-called "errors" have been the following:
That name is in snake_case when it should be in camelCase.I asked him if he could read the name in its present form, to which he responded in the affirmative. I asked him if the name conveyed a proper meaning, to which he responded in the affirmative. I then told him quite bluntly: "If you can read it and understand it, then that is all that is required, so go away and stop wasting my time".
You are not using the right design patterns.This shows that the person does not understand how to use design patterns properly. I do not have to use a particular design pattern in order to prove that I don't have the problem which the pattern was designed to solve. My code is as simple as possible and has a a logical structure that is easy to follow and therefore easy to maintain, so I don't need to pad it out with unnecessary design patterns.
You are not using that design pattern properly.I pointed out to him that a design pattern merely describes a design and not a particular implementation, so any implementation which performs the objective of the design can never be described as wrong. I have often been told that my implementation of the Model-View-Controller pattern is wrong, or that my implementation of the Singleton pattern is wrong, but when I ask my critic to point out where my implementation deviates from the objectives of the pattern in question they are unable to provide an intelligent response. As far as I am concerned if my code already achieves the correct result, and changing my implementation to match theirs would achieve exactly the same result, then there would be absolutely no benefit in changing my implementation to match theirs.
You are polluting global namespace.Global variables have their use in every programming language, such as being able to access them without them being passed as arguments inside every method call. This is not to say that I would prefer using a global variable instead of a method argument, but there are times when you have a collection of variables which may be accessed and which would be too cumbersome to include in every method call. Like anything which can be used, they can also be over-used, mis-used or even ab-used. Some developers go to great lengths to avoid the use of any global variables, so they put them inside objects which still have to be accessed globally. How is a global object different from a global variable? How much code do you have to write so that you can access a variable through a global object instead of the standard global namespace? My use of global variables does not cause a problem (except in the minds of the purists, but their opinions do not matter to me) so as far as I am concerned their use does not need a solution.
On more than one occasion I have seen someone devise a particular solution to a particular problem, only for others to include that solution in their own programs even when they don't have the same problem. What is the justification for that? Do they think that it's a cure-all for an endless list of unconnected problems? Some programmers don't have a clue whether that have that particular problem or not, so they implement the solution just to be on the safe side. They simply do not realise that writing code that you don't need is nothing more than a waste of time and effort, and will confuse the next programmer down the line who may spend valuable time investigating a piece of code only to find out that it doesn't actually do anything useful, or that the same result could have been achieved with far less code.
I am often asked ridiculous questions such as:
Why aren't you using an auto-loader?to which I reply
Because I don't have the problem for which auto-loaders are the solution.
Why don't you use namespaces?to which I reply
Because I don't have the problem for which namespaces are the solution.
Why don't you use interfaces?to which I reply
Because they are not a solution to any sort of problem.
Why don't you ....?to which I reply
Because I don't have to.
When I turn the question around and ask Why are you using all these things?
the answer is usually along the lines of I have to adopt all the latest fads and fashions in order to keep up with everyone else
. This desire to follow certain practices just because other people do is a classic example of the Lemming Effect or the Bandwagon Effect. I am not a lemming, I am a maverick, a non-conformist.
It is usually the symptoms which appear because of a problem that are noticed first, and it may take a while for the cause of that problem to be identified. Simply masking the symptoms so that they are less visible or cause less damage does not cure the problem at all. It will still fester and bubble and usually cause bigger and nastier symptoms to appear somewhere else. The best way to deal with a problem is not to have that problem in the first place. Too many of today's young programmers spend time reimplementing the same cure over and over again simply because they don't have the ability to identify and eliminate the underlying problem. If you go to your doctor and complain "When I bang my head against a brick wall I get a headache" and he prescribes headache tablets, then he is making a mistake by treating the symptoms of the problem instead of tackling its underlying cause. What if the medicine causes unpleasant side-effects? Will he prescribe more medicine which has its own set of side-effects? The correct answer is "Stop banging your head against the brick wall!" so why don't today's programmers follow the same pragmatic line of thought and prevent problems instead of dealing with the symptoms? Here are some of the "cures" I have encountered which should have been fixed by eliminating the problem, not by masking over it.
This is related to the idea of indirection or decoupling in which a direct call from ModuleA to ModuleB is interrupted by a call to an intermediate object called ModuleX. Thus ModuleA calls ModuleX which then calls ModuleB. The idea that this "decoupling" creates any benefits is totally delusional as the dependency between ModuleA and ModuleB has not been removed, it has simply been moved from being a direct dependency to an indirect dependency. Instead of reducing the amount of coupling this has actually doubled it by replacing a single inter-module call into two calls. This lead to the famous aphorism of David Wheeler which states the following:
There is no problem in computer science which cannot be solved by adding another layer of indirection - except for the problem of too many layers of indirection.
I do not see any benefit in doubling the amount of inter-module calls, so I don't do it.
Each journey has a start point and an end point. Journeys can be short or long depending on the distance, and the number of steps required is directly proportional to the distance. The most efficient journey is the one which takes the fewest number of steps, and the fewest number of steps can be calculated by measuring the distance along a straight line between the start and end points. That is a simple view, and in the real world there can be more complexities thrown into the mix. There can be obstacles in your way such as mountains, valleys, rivers, gorges, forests and swamps, but these obstacles may be offset by other resources being at your disposal, such as a bicycle, a car, a train, a boat or an aeroplane. This combination of obstacles and resources then changes the journey calculation from the smallest number of steps to the quickest time. Then you throw in the fact that each of these resources may come with a different cost, which then changes the calculation to the shortest time that you can afford. You then have to balance how much you are prepared to pay with how quick you want to be.
It is one thing to stand at the start point and see the target, the end point, in the distance. You can see the real obstacles in your path, and you know what resources are at your disposal, so you do your best to calculate the most cost-effective journey. Remember that the most cost-effective may not be the quickest available but the quickest that you can afford. It is one thing to deal with real obstacles, but is a whole new ball game when, after you've started your journey, you suddenly find out that you also have to deal with an array of artificial obstacles thrown up by the let's-make-it-more-complicated-than-it-really-is-just-to-prove-how-clever-we-are brigade. These new obstacles are artificial as they do not exist in the real world like mountains and rivers, but only as rules in the minds of those who consider themselves to be the intellectual elite, the paradigm police, the object taliban. You may know that you can ignore these artificial rules and still complete your journey and achieve a cost-effective result, but the paradigm police will continually chastise you for breaking their precious rules, for being a heretic. I consider myself to be experienced enough to know the difference between a real obstacle and an artificial rule, and I personally don't care about the opinions of the paradigm police, so if one of these artificial rules gets in my way I will exercise my rights as a free thinker and ignore it. This may upset the paradigm police, but the proof of the pudding is in the eating. It is not good enough to say "I have followed your rules, therefore the results must be OK". If the pudding tastes awful the fact that you followed the recipe to the letter will be irrelevant.
A facetious answer would be "If it was too easy then anybody could do it".
One of the big problems with OOP is that Nobody Agrees On What OO Is. If you ask a group of programmers for their definition of OOP you will get wildly different answers, some of which are documented in What OOP is not. They all seem to have forgotten the original and much simpler definition, which is:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
Note that the use of static methods is not object-oriented programming for the simple reason that no classes are instantiated into objects.
One of advantages of OOP is supposed to be that:
OOP is easier to learn for those new to computer programming than previous approaches, and its approach is often simpler to develop and to maintain, lending itself to more direct analysis, coding, and understanding of complex situations and procedures than other programming methods.
After reading these descriptions and having experienced procedural programming for several decades I approached OOP with the assumption that:
Having built hundreds of database transactions in several languages, and having built frameworks in two of those languages, I set about building a new framework using the OO capabilities of PHP. I then began to publish my results on my personal website, and received nothing but abuse.
OOP is supposed to be easier to learn. I say supposed for the simple reason that, like many things in life, much was promised but little was delivered. Too many cowboys have hacked away at the original principles of OOP with the result that instead of Object Oriented Programming we have Abject Oriented Programming.
As a long-time practitioner of one of those "previous approaches" and "other programming methods" I therefore expect OOP to deliver programs which are easier to maintain due to them having more reusable code and therefore less code overall. Having written plenty of structured programs using the procedural paradigm I expect OOP to deliver programs with comparable, if not better structures. This is what I strove to achieve in my own work, but when I began to publish what I had done I received nothing but abuse, as documented in What is/is not considered to be good OO programming and In the world of OOP am I Hero or Heretic? The tone of all this criticism can be summarised in your approach is too simple:
If you have one class per database table you are relegating each class to being no more than a simple transport mechanism for moving data between the database and the user interface. It is supposed to be more complicated than that.
What this person has failed to understand, probably due to a lack of experience, is that when writing a database application you are writing software which interacts with objects in a database, not objects in the "real world", and those objects are called "tables". The only operations which can be performed on a database table are Create, Read, Update and Delete (CRUD). Different combinations of these operations are performed on different combinations of tables by performing a collection of user transactions. The basic functionality of every user transaction always follows the same basic pattern - it performs one or more CRUD operations on one or more tables. It starts out as being nothing more than a "simple transport mechanism" as it entails the moving of data between the user interface, through the Business layer, to a Database layer and back again. It is the Business layer which is the heart of the application as this is where all the business rules are processed. In the RADICORE framework all standard functionality, up to and including all primary validation, is provided by components which are built into the framework. Any complex business rules can be added in later by the developer by inserting the relevant code into any of the numerous "hook" methods within any table subclass. In other words the framework provides all the simple processing while it is the developer's responsibility to add in any complexities.
Some developers still employ a technique which involves starting with the business rules and then plugging in the boilerplate code. My technique is the reverse - the framework provides the boilerplate code in an abstract table class after which the developer plugs in the business rules in the relevant "hook" methods within each concrete table class. Additional boilerplate code for each task (user transaction) is provided by the framework in the form of reusable page controllers.
I have been building database applications for several decades in several different languages, and in that time I have built thousands of programs. Every one of these, regardless of which business domain they are in, follows the same pattern in that they perform one or more CRUD operations on one or more database tables aided by a screen (which nowadays is HTML) on the client device. This part of the program's functionality, the moving of data between the client device and the database, is so similar that it can be provided using boilerplate code which can, in turn, be provided by the framework. Every complicated program starts off by being a simple program which can be expanded by adding business rules which cannot be covered by the framework. The standard code is provided by a series of Template Methods which are defined within an abstract table class. This then allows any business rules to be included in any table subclass simply by adding the necessary code into any of the predefined hook methods. The standard, basic functionality is provided by the framework while the complicated business rules are added by the programmer.
In my opinion one of the biggest causes of software which is overly complex has been the over emphasis of design patterns which, although a good idea in theory have turned into something completely different in practice. Young programmers don't just use patterns to a solve a genuine problem, they use them whether they have the problem or not in the hope that they will prevent any problems from ever appearing in the first place. So instead of using patterns intelligently they over-use them, mis-use them, and end up by ab-using them. What they fail to realise is that the abuse of design patterns actually causes a problem which the addition of even more design patterns will never solve. When Erich Gamma, one of the authors of the GoF book, heard about a programmer who had tried to put all 23 patterns into a single program he had this to say:
Trying to use all the patterns is a bad thing, because you will end up with synthetic designs - speculative designs that have flexibility that no one needs. These days software is too complex. We can't afford to speculate what else it should do. We need to really focus on what it needs.
If you want to see prime examples of how not to use design patterns please take a look at the following:
In this blog entry The Dark Side Of Software Development That No One Talks About John Sonmez wrote:
I originally started this blog because I was fed up with all the egos that were trying to make programming seem so much harder than it really is. My whole mission in life for the past few years has been to take things that other people are trying to make seem complex (so that they can appear smarter or superior) and instead make them simple.
Another reason why I think that the basic concepts of OOP have been polluted by ever more levels of complexity is that some people like to reinterpret the existing rules in completely perverse ways. This just goes to show that the original rules were not written precisely enough if they are open to so much mis-interpretation. If rewriting the existing rules is not bad enough there is another breed of developer who takes this perversity to new levels by inventing completely new rules which, instead of clarifying the situation, just add layers of fog and indirection. Take, for example, the idea that inheritance breaks encapsulation. The idea is that this produces tight coupling between the base class and the derived class, which simply goes to show that they do not have a clear idea of how to use inheritance properly to share code between classes. If I have an abstract/base class called A and a concrete/derived class called C it means that class C cannot exist on its own without without the shared code that exists within class A. The idea then that the contents of A should be kept hidden from C and treated as if they were separate entities makes a complete mockery of the whole idea of inheritance.
There are also developers out there who seem to be forever dreaming up new ideas to make the language more OO than it already is, or advocating the use of new procedures or toolsets to make the developer's life more complex than it already is. This is where all these optional add-ons originated. According to th3james all these ideas seem to follow a familiar lifecycle:
While it may be indicated that an idea has certain benefits in some circumstances there are too many developers out there who don't have the intelligence to work out if those circumstances exist or not in their current situation, so rather than thinking for themselves they apply that idea in all circumstances in an attempt to cover all the bases and make their asses fireproof. Unfortunately if you apply an idea indiscriminately and without thinking it is the without thinking aspect which is likely to cause problems in the future.
Some developers seem to think that any idiot can write simple code, and to prove their mental superiority they have to write code which is more complicated, more obfuscated, with more layers of indirection, something which only a genius like them can understand. I'm sorry, but if you write complicated code that only a genius can understand then your code is incapable of being read, understood and maintained by the average programmer. The true mark of genius is to write simple code that anyone can understand. To put it another way - The mark of genius is to achieve complex things in a simple manner, not to achieve simple things in a complex manner.
In his paper Protected Variation: The Importance of Being Closed (PDF) the author Craig Larman makes this interesting observation:
Novice developers tend toward brittle designs, and intermediates tend toward overly fancy and flexible generalized ones (in ways that never get used). Experts choose with insight - perhaps choosing a simple and brittle design whose cost of change is balanced against its likelihood. The journey is analogous to the well-known stanza from the Diamond Sutra:
Before practicing Zen, mountains were mountains and rivers were rivers.
While practicing Zen, mountains are no longer mountains and rivers are no longer rivers.
After realization, mountains are mountains and rivers are rivers again.
Novices write simple solutions, intermediates go for the overly-complicated solutions, but experts go back to simple solutions which, although they may seem to be more brittle, are often quicker and less expensive to change than those which are full of unused features. The problem is that too many of these intermediates consider themselves to be experts and look down on the novices, but they fail to realise that there is actually one more level above them. To the novice an intermediate may appear to be a man amongst boys, but to the experts he is nothing more than a boy amongst men. This inability of the unskilled to recognize their ineptitude is known as the Dunning-Kruger effect.
Another variation of the Novice/Intermediate/Expert trilogy is Child/Boy/Man. A boy looks up to a teenager, but a man looks down on a teenager. This means that a teenager can be regarded as both of the following:
A man amongst boys, but a boy amongst men.
One major difference between intermediates and experts is that intermediates often suffer from the Lemming Effect in that they go along unquestioningly with popular opinion, always eager to jump on the bandwagon and follow the latest fad, fashion, concept or technique without first finding out if it has any actual merit.
Some people cannot tell the difference between "common practice" and "best practice". If a particular practice is followed by a group of programmers then it becomes common within that group, but it may not necessarily be best. It may be best for the type of applications that they write, but it may not be best for other groups of programmers who write different types of applications. The point is that each group of programmers will adopt practices which are best for them. It would be plain arrogance for one group to attempt to impose their practices on all the other groups. Once a set of practices has become ingrained it resembles a set of religious beliefs, and criticising a person's religious beliefs is a good way to start a war.
You should never lose sight of the fact that a computer program is a set of instructions which is written in a human-readable language and then compiled into a machine-readable language. A computer does not have any intelligence of its own, it is simply a fast idiot that obeys every instruction that it has been given. Writing a computer program can be likened to writing an instruction manual for an idiot in which every tiny detail must be explicitly covered as it does not understand the concept of implicit. The fact that "human readable" is more important than "machine readable" was emphasised in this quote made in 1984 by H. Abelson and G. Sussman in "The Structure and Interpretation of Computer Programs":
Programs must be written for people to read, and only incidentally for machines to execute.
Martin Fowler, the author of Patterns of Enterprise Application Architecture (PoEAA) wrote:
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
Some obscure nobody by the name of Tony Marston (who??) translated this as:
Any idiot can write code than only a genius can understand. A true genius can write code that any idiot can understand.
The mark of genius is to achieve complex things in a simple manner, not to achieve simple things in a complex manner.
In the Software Development Mantra the editor of Methods & Tools wrote:
Even if we like sometimes to implement "clever" solutions, we should always remember that simplicity is a key factor for maintainability.
The following comment in Why bad scientific code beats code following "best practices" was made by "quotemstr":
It's much more expensive to deal with unnecessary abstractions than to add abstractions as necessary.
This came from an anonymous CS instructor at a lecture in the 1980s:
Always choose clear code over clever code.
In his blog post Avoiding object oriented overkill Brandon Savage wrote:
Code spends 80% to 90% of its life in maintenance. And in my own experience, the people maintaining the code are not always the same people who wrote it. This means your code is going to have to communicate with more than just a computer processor. It's going to have to communicate intent to developers who have never seen the code before. This is much more challenging than writing code that "just works."
It is therefore imperative that a programmer writes code which can be read, understood and maintained by others, but what exactly does "readable and maintainable" actually mean? As is usual there is a huge difference in opinion, with the only constant being "code not written by me is crap". This is then extended into "code which is not written in a style approved by me is crap". This programming style is then given a formal name, that of "standards" or "best practices". In my several decades of experience I have often moved to a new team only to discover that some of these details are the exact opposite of what was considered "best" in the previous team. I found myself wasting a great deal of my valuable time in adjusting the way I wrote code just to conform to a new set of standards where the differences were purely cosmetic. I now restrict myself to a minimalist set of standards which can be boiled down to the following:
Unfortunately a large number of people cannot stick with the basics and endeavour to fill their "standards" with ever increasing levels of irrelevant and nit-picking details, with the most common excuse being being "you must do it this way to be consistent with everyone else". But why should I lower the quality of my work just to be consistent with a bunch of idiots? Why should I change the habits which have been acceptable for several decades just to be consistent with those of an arrogant upstart who's only been writing code for 10 minutes? The notion of "consistency" is often taken too far by trying to enforce the same rule in all circumstances without realising that sometimes a different set of circumstances requires a different set of rules. On more than one occasion I have seen where a rule has been applied blanket fashion without thinking, and it is always the "without thinking" part that can cause unexpected problems. In his article Humble Architects Johannes Brodwall writes "Rule 3: Consistency isn't as important as you think". He also states in "Rule 6: Separate between rules and dogma" that there are 3 main reasons to have a rule in the coding standards:
I am happy to work with coding standards that contain rules which help avoid unsafe and incomprehensible code, but when it comes to #3 I'm afraid that you can take those rules and stick them where the sun doesn't shine. Examples of such petty rules which I love to ignore are:
In his article Pragmatic Thinking: Novice vs Expert Nirav Assar writes:
Experts don't follow rules, they follow intuition and evolved experience.
In the same article he also writes:
Rules and regulations can actually stifle a developer's productivity. It is actually easy to derail an expert and ruin their performance. All you have to do is force them to follow the rules.
In his article The Dark Side of Best Practices Petri Kainulainen writes:
When best practices are treated as a final solution, questioning them is not allowed. If we cannot question the reasons behind a specific best practice, we cannot understand why it is better than the other available solutions.
Later in the same article he writes:
If best practices get in the way, we should not follow them. This might sound a bit radical, but we should understand that the whole idea of best practices is to find the best possible way to develop software. Thus, it makes no sense to follow a best practice which does not help us to reach that goal.
In his article Don't waste time on Code Reviews Jim Bird says that you should always favour substance over style:
Reviewing code against coding standards is a sad way for a developer to spend their valuable time.
It is far more important to check that the code does what it is supposed to do than follow a set or arbitrary and purely cosmetic formatting rules. Whether an application is successful or not does not depend upon how closely the developers followed the standards, it depends entirely upon its perceived ability by the end users that it solves their problems in a cost-effective manner. In his article Your Coding Philosophies are Irrelevant James Hague writes:
It's not the behind-the-scenes, pseudo-engineering theories that matter. An app needs to work and be relatively stable and bug free, but there are many ways to reach that point. There isn't a direct connection between some techie feel-good rule and success. For most arbitrary rules espoused in forums and blogs, you'll find other people vehemently arguing the opposite opinion. And it might just be that too much of this kind of thinking is turning you into an obsessive architect of abstract code, not the builder of things people want.
If coding standards are supposed to promote the writing of code which is readable and understandable, and therefore maintainable, if it is possible to take a rule from any set of published standards and completely ignore it yet still produce code which is readable and understandable, it should be obvious that the rule has no effect and should be ignored by everybody as being unproductive and irrelevant. The effectiveness of a rule should be obvious, in which case it should be easy to follow. Any rule which goes against previous experience and which has no provable benefit will be difficult to enforce and therefore should not be enforced.
In his article We should not enforce decisions that we cannot justify Petri Kainulainen writes the following:
That is why we invented company policies and best practices. They are very convenient because they help us to enforce our opinions without the need to justify them. They are also a great way to demotivate the other developers.
In his article Coding Standards: Humans Are Not Computers P�draic Brady writes the following:
A coding standard should state a subset of common sense rules that everyone already uses. In other words, it should be almost utterly pointless to an experienced programmer.
He also has this to say regarding the use of automated tools which report every violation of the coding standards:
A perfect coding standard is, in my opinion, one which limits the rules, eradicates ambiguity, formulates multiple use cases and avoids trivialities. [...] For example, if I place a newline before the closing curly bracket of a class, will the planet instantaneously implode? Probably not. Will a programmer notice it? If they do, I feel sorry for them. Does PHP_CodeSniffer currently torture me with it? YES. MAKE IT STOP. If I use a shorthand control statement, will the planet instantaneously expl... you get the picture.
In his blog post at Unnecessary contrapositions in the new "Symfony Best Practices" Matthias Noback comments on the idea that someone, even a senior member of a team, can arbitrarily decide what is "best practice" and what is not. The argument was caused by the following statement:
[...] community resources - like blog posts or presentations - have created an unofficial set of recommendations for developing Symfony applications. Unfortunately, a lot of these recommendations are in fact wrong.
As in many other endeavours, in computer programming there can be many ways in which a particular result may be achieved. For someone to label his/her personal preference as "best" and everything else as "wrong" is a combination of arrogance and ignorance. It is arrogant by claiming that "their" opinion is the only one worth having. It is ignorant by calling non-conformant code "wrong" as the only true definition of wrongness is code which does not work. Anything which works cannot be wrong. Anything which does not work cannot be right. If a programmer has been writing successful software for several years, and someone comes along and says "You are not doing it the way that I would, therefore you are wrong", that attitude will immediately raise the hackles of that programmer and is likely to start an argument that will never be resolved. Once a person, or a group of people, have adopted a certain set of beliefs or practices, then attacking those beliefs or practices will always be an uphill battle. In his article Compartmentalization in the PHP community Matthias Noback says the following:
Though starting a fight is always tempting, it doesn't lead to converting someone to your opinion. It's not okay to fight with everyone who doesn't agree with you or your group. It's particularly not okay to fight with someone who seems to have a completely different mindset. Even though they sound stupid to you, they may have a set of experiences that's entirely different from yours. And, you know, they can live a successful life as well, believing those "stupid" things, so you might even learn something useful from them.
When someone asks me "Why aren't you following so-and-so rule?" my immediate response is always "Why should I? What is the justification for this rule? What bad thing happens if I break this rule?" Any rule which cannot be justified should not be a rule in the first place. Any rule which can be broken without anything bad happening should not be a rule in the first place. If the only bad thing that happens when I break a rule is that I offend the sensibilities of the person who wrote that rule, then all I can say is "Climb back into your pram and leave adult business to the adults!" Silly little rules do not help me write better software, they just get in the way.
You should try to resist the temptation of creating too many rules as that could turn out to be a hindrance rather than a help. In his article Cull your rules and regulations, or be frozen by them the author points out where NASA culled a list of 2,200 safety requirements, which were expensive and time consuming to implement, to a set of 500 rules which were really important. In this article he also states the following:
This a major point in companies fixing up their software process: you probably have all sorts of rules and regulations that no longer apply. Just like with managing a legacy application portfolio, you have to aggressively manage your compliance portfolio to eliminate rules that no longer apply.
[...]
You also hear some cases of federal agencies forcing this culling by simply not following the rules and seeing if anyone complained: the compliance equivalent of just turning off old, dusty servers to see who's using it.
As well as following the simple guidelines here are some which you should try to avoid:
Code must be readable and maintainable by anyone who looks at the code in the future, which may be weeks from now or years from now. Always assume that the next person will have less experience than yourself, either with programming in general, your program in particular, or the larger application of which your program is just a small part. Do not write code in a convoluted way in order to impress your seniors with how clever you can be. Instead write code to impress your juniors with your ability to break a problem down into a small parts each of which is then solved in a simple and easy to understand fashion.
You should also remember that one of the people who may look at your code at some time in the future could be yourself, by which time you will have forgotten why you wrote it in the way you did and you will look at it through the eyes of a stranger instead of being in familiar territory. There is nothing more embarrassing than thinking "who wrote this crap?" only to discover that it was you!
There is a well known principle which goes by the name of the 80-20 Rule which states that there is a natural imbalance between causes and results. For example:
In a 1960s study IBM discovered that 80% of a computer's time was spent executing about 20% of the operating code. This was because they had been adding to the instruction sets which were being built into computer processors by making more and more complex instructions which needed to be executed in a single clock cycle. The study showed that these complex instructions, which accounted for 80% of the construction costs, were only being used 20% of the time. They then redesigned their processors so that instead of complex instructions which executed in a single clock cycle they used a series of simpler instructions which used one clock cycle each. By reducing the number of instructions that were built into each chip they not only made the clock cycles faster, they also reduced the amount of power that was consumed as well as the amount of heat that was generated. By replacing complexity with simplicity they reduced their manufacturing costs and actually made their processors run faster and cooler, and with less energy. The overall effect was to make their computers more efficient and faster than competitors' machines for the majority of applications.
This philosophy, the movement from Complex Instruction Set Computing (CISC) to Reduced Instruction Set Computing (RISC) was eventually taken up by other manufacturers. I was working with Hewlett-Packard mini-computers in the 1980s when they introduced their PA-RISC range, which included a new version of the operating system and language compilers to take advantage of the new chip architecture. I can personally vouch for the fact that they were faster than the previous generation of processors.
This ratio between the complex (expensive) and the simple (cheap) can be applied to program code as well as computer processors. By adding to the number of classes, design patterns and levels of indirection in a vain attempt to produce "clever" code (more like "clever looking" code) the programmer is actually adding more lines of code than is necessary to produce the desired result. By writing 1,000 lines of code to achieve something that others can do in 500 lines does not make your code "better" in any sense of the word. It is full of waste, it takes longer to write, it takes longer to compile, it takes longer to execute, and it takes longer for other developers to read and understand. Don't forget that with more lines of code you also increase the number of potential bugs.
This ability to prefer the complex over the simple is not confined to writing more lines of code than is necessary, it also appears in the choice of language features that some developers use to achieve a certain result. In his paper The Secret of Achieving More with Less the author Richard Koch notes that Sir Isaac Pitman, who invented shorthand, discovered that just 700 common words make up two-thirds of our conversation. Including the derivatives of these words, Pitman found that these words account for 80% of common speech. In this case, fewer than 1% of words (the New Oxford Shorter Oxford English Dictionary lists over half a million words) are used 80% of the time. If you swap "words in a human language" for "words in a computer language" you will find a similar relationship between the words that are available and the words which are commonly used. I have written programs in more than one language over several decades, and I can honestly say that I have never found a good reason to use more than a small fraction of the total features that are available. Yet there are some programmers out there who try to use as many of the languages features as possible in a misguided attempt to prove how "clever" they are when in fact all they are doing is managing to confuse the readers of their code.
When I was working in America in the 1980s one of my female co-workers, who was a Valley Girl, was fond of saying "gag me with a spoon" to which I replied (in my best British accent, of course) "induce anti-peristalsis with a stirring implement". Whilst the two terms mean exactly the same thing my phrase was confusing to her simply because I used unfamiliar words. If you use unfamiliar complex constructs in your code when the same result can be achieved with familiar and simple constructs then all you are doing is slowing down the reader's understanding of what you have written. Code which is difficult to read is also difficult to understand, which in turn makes it difficult to maintain. This difficulty is something which should be discouraged at every possible opportunity.
The use of overly-complex language features where the same result can be achieved with simple and well known features has been exacerbated by all those intermediate level programmers who insist of making complex yet trivial changes to the PHP engine just because they think it would be "kewl". I have been following the conversations on the internals list, where language changes are proposed, discussed and voted upon, and I have seen such excuses for language changes as language X has this feature, so why doesn't PHP?
or I want this feature added so that I can achieve the result I want by using fewer keystrokes.
I have seen many discussions where the proposer won't take "no" for an answer even after being told that either his solution is flawed or his "problem" is not actually a problem after all. I have seen some ridiculous proposals as well as some ridiculous arguments against decent proposals. I have seem some questionable proposals voted in by as few votes as 9-to-1, which means that the language is being changed to satisfy the whims of the vociferous minority instead of the needs of the silent majority. As far as I am concerned if some functionality can be easily provided with a few lines of user-land code then there is absolutely no need to pollute the language with a new feature which no more than 9 people will actually use. Even worse are those programmers who will use the new feature for no other reason than "because it's there".
This quote came from Rasmus Lerdorf, who invented PHP, on the internals list:
Rather than piling on language features with the main justification being that other languages have them, I would love to see more focus on practical solutions to real problems.
Here is a quotation taken from the Revised Report on the Algorithmic Language Scheme.
Programming languages should be designed not by piling feature on top of feature, but by removing the weaknesses and restrictions that make additional features appear necessary.
Although I wrote some programs using assembler on a UNIVAC mainframe, INSIGHT, TRANSACT and POWERHOUSE on the HP 3000 mini-computer, my main languages were COBOL in the 1970s and 80s followed by UNIFACE in the 1990s.
COBOL (at least the one that I knew before OO capabilities were added later) was a procedural language which had programs and subprograms which were compiled and linked into a single executable. Each (sub)program was divided into a PROCEDURE DIVISION for code and a DATA DIVISION for data structures. A "program" always started executing from the first line of code in the PROCEDURE DIVISION whereas a subprogram could have any number of entry points (names) which could be CALLed from another (sub)program. Each (sub)program contained statements which could be contained within sentences, paragraphs (labels) and sections (labels followed by the word "section"). It was possible to alter the processing path through the code by using the GOTO (jump) or PERFORM (jump and return) on a paragraph or section name. It was possible to either PERFORM paragraph_A thru paragraph_Z or PERFORM section_A.
This version of COBOL (the last version I worked on was released in 1985) did not have any OO capabilities because:
CALL entry_point_A always executed the same piece of code.Writing a program consisted of starting with data structures, one for each database table and one for each form (screen), writing the procedures (code) to connect the table structure with the database, to connect the form structure with the user interface, and then to move the data between the table structure and the form structure. Additional code was required in order to perform data validation, error checking and the processing of any business rules.
As there was no clear way to separate presentation logic, business logic and data access logic into separate subprograms it was possible to write an entire program in a single source file, which made each program an example of the 1-Tier Architecture.
When I started programming we did not have the luxury of monitors and keyboards, we wrote our code on sheets of paper from a coding pad, submitted the sheets to the punch room where the girls would punch the code onto 80-column punch cards. They would then return the cards to us which we would then check, then submit the pack of cards with a piece of paper known as a "job sheet" to the computer room. A computer operator would then feeds each pack of cards into the mainframe, then return the cards to us with the computer printout of the results. The printout was on continuous flowline paper which was 132 columns wide and 66 lines per page. The source code for each program or subprogram was printed on a single listing. It was quite normal to spend all day perusing the current listing, writing out changes on the coding pad, getting the cards punched, then submitting jobs to the computer room at the end of the day so that the results could be picked up the next morning. Because of this slow turn-around we had to spend a lot of time in "desk checking" our work to make sure that the overnight run did not fail because of some stupid mistake. The idea that at some time in the future we would be able to view our code on a screen, type in a change, execute the code and see the results within seconds was beyond our wildest dreams.
While designing and building COBOL solutions I learned some important lessons:
I have written several articles regarding my experiences with COBOL which can be found here.
UNIFACE was a component-based rapid application development language based on the Three Schema Architecture with its Physical Schema (the actual database), Conceptual Schema (an internal representation of the database, which was also known as the Application Model) and External Schema (what the user sees). Each database table in the Physical Schema was created as an entity in the Conceptual Schema to identify its structure (field names and data types), primary keys, unique keys, and any relationships with other entities. It was also possible to define default code in the entity triggers. Each table and column had a series of containers known as "triggers" into which code could be inserted. Triggers were fired when the user selected a particular operation, via a function key, such as <read> or <store>, or moved the cursor from one part of the screen to another.
User transactions were developed as form components by using the Graphical Form Painter (GFP) which was built into the Uniface Development Environment (UDE). A form component started with a blank page onto which the developer could draw one or more rectangles known as entity frames which could then be linked to one of the entities (database tables) within the Application Model. One or more fields could then be painted within each entity frame, and each field name was selected from one of the entity's fields which automatically provided its size, data type and label. After being compiled the form could be run, and by pressing the function key which fired the <read> trigger the form would automatically be filled with data from the database. The user could then change any of this data, and by firing the <store> trigger the updated data would automatically be written back to the database. The developer did not have to write any code to perform simple data validation as the code already "knew" every field's size and data type, so could validate user input as it was entered.
The developer did not have to write any SQL as the firing of the database triggers automatically sent the command to the relevant database driver which constructed and executed the necessary SQL statement. It was not possible to construct SQL queries with JOIN statements, instead a foreign entity had to be painted within the entity frame (thus becoming an "inner" entity) which caused UNIFACE to fire the <read> trigger of the inner entity after reading each occurrence of the outer entity. A separate pre-compiled driver was supplied with UNIFACE, one for each DBMS engine, and the application start-up script defined which DBMS to use at run-time. It was therefore possible to switch from one DBMS to another simply by changing the start-up script and without having to modify any form components.
UNIFACE did not have any OO capabilities because:
As the presentation logic and business logic was contained in the form component, and the data access logic was contained in a separate database driver, this made the application an example of the 2-Tier Architecture.
When UNIFACE 7.2.04 was released in 1998 it provided the ability to split form components into two, with the form itself concentrating on the User Interface (UI) and all business logic now contained in a separate service component. A service component could be shared by any number of form components. This then made the application an example of the 3-Tier Architecture. Version 7.2.06 saw the introduction of a Server Pages (which could be accessed through a web browser) as an alternative to the Form component (which could only be accessed on the desktop). This also meant that an application could be developed with one set of Presentation Layer components running on the desktop and another set which could be run through a web browser, all sharing the same Business Layer and Data Access Layer components. It also introduced the use of XML streams to handle the transfer of data between the Service components and the Form/Server Page component.
While designing and building UNIFACE solutions I learned some additional lessons:
I have written several articles regarding my experiences with UNIFACE which can be found here.
The last project I worked on in UNIFACE, which is documented here, convinced me that it was totally unsuitable for web development. Possible, yes, but extremely clunky and inefficient. It generated HTML pages with custom tags whereas in my humble opinion they should have been using XSL stylesheets. UNIFACE had procedures to read and write XML documents, and to use XSL stylesheets to transform an XML document to another XML document, but for some reason they totally failed to allow the option to transform XML into HTML. I wrote about this shortcoming in Using XSL and XML to generate dynamic web pages from UNIFACE.
If you ask 10 different programmers to define what OO means you will get 10 different answers all of which are either misleading or downright wrong. This is a huge problem as without a clear and unambiguous definition you will quickly get a crowd of charlatans and cowboys who invent new meanings and new terminology and thereby muddy the waters even more instead of providing clarity. When I began working with an OO language in 2002 the first thing I did was to look for a proper definition of OO. After browsing the internet for a while I came across a quote from Alan Kay who invented the term where he challenged a manager who was claiming that his new product was object oriented:
- So, this product doesn't support inheritance, right?
- That's right.
- And it doesn't support polymorphism, right?
- That's right.
- And it doesn't support encapsulation, right?
- That's correct.
- So, it doesn't seem to me like it's object-oriented.
I came across a similar definition from Bjarne Stroustrup (who designed and implemented the C++ programming language) in section 3 of his paper called Why C++ is not just an Object Oriented Programming Language in which he said:
A language or technique is object-oriented if and only if it directly supports:
- Abstraction - providing some form of classes and objects.
- Inheritance - providing the ability to build new abstractions out of existing ones.
- Runtime polymorphism - providing some form of runtime binding.
I found the following definitions of the three principles to be the easiest to understand:
| Encapsulation | The act of placing data and the operations that perform on that data in the same class. The class then becomes the 'capsule' or container for the data and operations. This binds together the data and the functions that manipulate the data.
More details can be found in OOP for heretics |
| Inheritance | The reuse of base classes (superclasses) to form derived classes (subclasses). Methods and properties defined in the superclass are automatically shared by any subclass. A subclass may override any of the methods in the superclass, or may introduce new methods of its own.
More details can be found in OOP for heretics |
| Polymorphism | Same interface, different implementation. The ability to substitute one class for another. By the word "interface" I do not mean object interface but method signature. This means that different classes may contain the same method signature, but the result which is returned by calling that method on a different object will be different as the code behind that method (the implementation) is different in each object.
More details can be found in OOP for heretics |
For some people there is an additional aspect to OOP:
| Abstraction | The process of separating the abstract from the concrete, the general from the specific, by examining a group of objects looking for both similarities and differences. The similarities can be shared by all members of that group while the differences are unique to individual members. The result of this process should then be an abstract superclass containing the shared characteristics and a separate concrete subclass to contain the differences for each unique instance.
As explained in What is "abstraction" there are two flavours: Please also refer to What Abstraction is not and The difference between an interface and an abstract class. |
This led me to the following definition of what OO is,
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
Having worked with non-OO languages (COBOL and UNIFACE) for several decades I therefore began to play with these new concepts using the PHP language, but I only employed those features which could actually live up to the promise of "increased code reuse and decreased code maintenance". Anything which produced more code, and especially more code which could not be reused, I disregarded as a step in the wrong direction.
You can see a discussion on the differences between OO and procedural code at Your code is not OO, it is procedural.
After working my way through a few online tutorials to discover what I could do with PHP my next step was to reproduce the kind of applications that I had built with my previous languages. To assist in this I rebuilt in PHP the development framework that I had first built in COBOL and later in UNIFACE. My results are documented in A Development Infrastructure for PHP. My design goals at the outset were as follows:
There was one of the features in UNIFACE that I decided to reverse in my new PHP version. Instead of defining the table structure in the Application Model and then exporting it to the physical database in the form of DDL scripts I started with the physical database schema and imported it into my Data Dictionary from where I could generate the class files for each database table. This made dealing with changes in the database very easy - (1) update the database schema, (2) import the changed structure in the Data Dictionary, then (c) export to the application.
I created a table in my database, then created the necessary scripts to view and maintain that table:
Because I knew that I was dealing with a database table which I was going to manipulate using SQL statements I made the following decisions which I have never regretted:
$object->setFoo($foo); $foo = $object->getFoo();
$result = $object->operation($column1, $column2, ..., $columnN);
I did not like either of these options, and as I had already discovered how easily PHP handled arrays I decided to go for a much simpler option. When a request is received by PHP the various arguments appear in either the $_GET or $_POST arrays, so the simplest option as far as I could see would be to pass that array directly into the object without unpacking it into its component parts, as in:
$fieldarray = $object->insertRecord($_POST); $fieldarray = $object->updateRecord($_POST); $fieldarray = $object->deleteRecord($_POST);
The other way of getting data into an object is to read it from the database via a SELECT statement. This returns a result set which can contain any number of rows and columns which in turn can be passed around as a single array. I had seen sample code which has separate methods to populate the WHERE clause, such as getById($id) or getByName($name), but I decided to ignore this approach completely and go for the simplest option - use a single WHERE string which could contain any possible combination of column names and values, or even sub selects, as in:
$fieldarray = $object->getData($where);
This follows the minimalist principle by achieving the desired result with the minimum of code.
Note that in this first iteration I did not create a separate component for the Data Access layer. I kept all the code which generated the various SQL statements in separate methods within the Business layer component with the intention of splitting them out to a separate object once the code had matured.
I created a second table in my database, then created the necessary scripts to view and maintain that table:
You should notice here that I have deliberately used the copy-paste method to create new scripts and this breaks the Don't Repeat Yourself rule. The intelligent amongst you should realise that you have to create code with duplications before you can remove those duplications, as shown in Step #3.
At this point I had two sets of scripts, one for each database table, which contained a great deal of duplicated code which was ripe for refactoring. This is where I had to examine all the scripts, look for duplicated code, then move that code to a single place from where it could then be referenced as many times as necessary.
For the Presentation layer components I did the following:
require_once "classes/table_A.class.inc"; $dbobject = new table_A;
This made each Presentation layer component tightly coupled to a single Business layer component, which removed any possibility of reusing it with other Business layer components. I did not like this idea, so I replaced it with:
require_once "classes/$table.class.inc"; $dbobject = new $table;
The value for $table is passed in from another script using a method known as Dependency Injection.
For the Business layer components I did the following:
I repeated this process of creating tables in my database, then creating the programs to maintain those tables, until I had all the components I needed for my Role Based Access Control system. This has subsequently grown into a complete framework (which I have released as open source) with a much bigger database. I designed and built my own Data Dictionary so that I could create my class files directly from my database schema, and I could create working user transactions from my catalog of Transaction Patterns which make use of my reusable Page Controllers and reusable XSL stylesheets. This enables me to write new applications very quickly as all the standard boilerplate code is taken care of within the framework, which leaves me more time to spend on the business rules and the clever stuff.
I fulfilled my goal of creating a framework around the 3 Tier Architecture, with its separate layers for Presentation, Business and Data Access logic, as shown in figure 1:
Figure 1 - The 3-Tier Architecture
After showing my framework to other developers it was pointed out that, because I had split my Presentation layer component into two parts, one of which exclusively dealt with the production of all HTML output, I had also implemented the Model-View-Controller design pattern, as shown in figure 2:
Figure 2 - The Model-View-Controller structure
While similar, these two architectural patterns are not the same, but they do overlap and can exist together, as shown in figure 3:
Figure 3 - MVC plus 3 Tier Architecture
")
What I have effectively done is to split the "Model" of the MVC pattern into two so that all communication with the physical database is now handled in a separate object, with a separate class for each DBMS engine. This leaves the Model to deal which such things as data validation, business rule processing and task-specific behaviour.
The actual framework is a little more complicated as it contains different components for different purposes, as shown in figure 4:
Figure 4 - detailed structure diagram
")
Note that in the above diagram each of the numbered components is a clickable link.
When it comes to building database applications, especially those with large numbers of tables, nothing can beat a framework and a methodology that has been specifically built for that purpose. This is how my development speeds have improved with each different language and framework:
When my critics tell me that my approach is not the way it is done by "proper" OO programmers I simply point them to this project which was designed by OO "experts" who all knew the "proper" way to do things with all their fancy inheritance hierarchies, design patterns, multiple layers of abstraction and other fancy-sounding gobbledygook. While they spend their time in devising more and more complicated solutions and more and more silly rules I find the simplest way possible to get the job done, which is why I can complete a task in FIVE MINUTES what others can only do in TEN DAYS! Whose solution would YOU rather have?
After publishing several articles on my personal website I was asked to make my development framework available to others, so I released it as open source in 2006. I was then asked by a design agency to build a new back-end application for one of their clients called Blackwoods Gin, which was completed within the 3 month deadline. This was so successful that the agency asked me if I could build another for one of their other clients, but instead of a bespoke application just for this one client they asked if I could design and build a general-purpose package which could be used by any number of clients. This was an opportunity too good to miss, so I went ahead. As the basis of any good application is the database I decided to start with the database designs which I had read about in Len Silverston's Data Model Resource Book. As soon as I saw these designs I recognised immediately the power and flexibility that they provided, so my development process involved the following steps:
Using this procedure I created a prototype multi-lingual and multi-currency application around the PARTY, PRODUCT, ORDER, INVOICE, INVENTORY and SHIPMENT databases which I could demonstrate to the client in only 6 months. That was over 600 working user transactions in just SIX MONTHS! Could you do that with your framework? If the answer is "No" then I'm afraid that you are using the wrong framework.
The actual implementation involved the following stages:
This application went live for Wedding Rings Direct in May 2008. Since then it has been undergoing constant enhancements, both for the original client as well as several new ones.
You should be able to see that not only did I use the bare minimum of code in order to create my framework, but this framework then enabled me to create an entire back-end e-commerce application with the minimum of effort. Yet there are still some clowns out there who insist that my methods are wrong! If their definition of "wrong" includes "in shorter timescales" and "with less effort" then I can only plead "guilty".
By switching to Object Oriented Programming you are supposed to increase code reuse and decrease code maintenance when compared with previous non-OO languages
. Unfortunately a large number of today's programmers have never used a non-OO language so they are unable to make that comparison and are therefore incapable of seeing if their methods are actually an improvement or not. I have designed and developed numerous applications in non-OO languages for several decades, and in that time I have created frameworks which have allowed me to reduce development times for common tasks from one day (COBOL) to thirty minutes (UNIFACE) and then to five minutes (PHP). This fall has been directly proportional to the amount of reusable code I have had at my disposal as well as the ability to generate code from reusable templates. First, let me identify how I have used the principles of Encapsulation, Inheritance and Polymorphism:
| Encapsulation | I have created a separate class for every business entity with which the application has to deal. As every business entity has its own table in the database this equates to a separate class for each database table.
I have also created several View classes - one for HTML output, one for PDF and another for CSV. |
| Inheritance | As the operations which can be performed on a database table - create, read, update and delete - are static I have been able to place a large amount of code in an abstract table class which can be inherited (and therefore shared) by every concrete table class. As I have several hundred tables in my application this represents a huge amount of shared code. |
| Polymorphism | Every Page Controller communicates with a Model using method names which are defined in the abstract table class, which means that any Controller can be used with any Model.
The construction and generation of all SQL statements is performed within a separate Data Access Object, with a separate class for each different DBMS (MySQL, PostgreSQL, Oracle, SQL Server). As each of these classes use identical method names I can switch from one DBMS to another without having to change any code in any of the Model classes. |
The biggest problem in OOP is deciding what types of object to create, and how many. In his article How to write testable code the author identifies three distinct categories of object:
| Entities | An object whose job is to hold state and associated behavior. The state (data) can be persisted to and retrieved from a database. Examples of this might be Account, Product or User. In my framework each database table has its own Model class. |
| Services | An object which performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). Examples of Services could include a parser, an authenticator, a validator or a transformer (such as transforming raw data into HTML, CSV or PDF). In my framework all Controllers, Views and DAOs are services. |
| Value objects | An immutable object whose responsibility is mainly holding state but may have some behavior. Examples of Value Objects might be Color, Temperature, Price and Size. PHP does not support value objects, so I do not use them. I have written more on the topic in Value objects are worthless. |
This echoes the Classification of domain objects which Eric Evans wrote about in his book on Domain Driven Design.
This is also discussed in When to inject: the distinction between newables and injectables.
When developing a database application you should bear in mind the following points:
The "standard procedures" are often referred to as boilerplate code. This is the code which is liable to be repeated and is therefore a prime candidate for moving into a reusable module, thus following the Don't Repeat Yourself (DRY) principle. Before you can deal with repeating patterns in your code you must first be able to spot them using a process called Abstraction. Following the advice of Erich Gamma, one of the Gang of Four who wrote the famous book on Design Patterns, you should not start by picking a selection of design patterns and then write code to implement them, you should write code that works, and then refactor it to see if any patterns emerge. As explained in Designing Reusable Classes which was published by Ralph E. Johnson & Brian Foote in 1988, this involves a technique which they call programming-by-difference in which you scan through your code looking for similarities with the aim of separating the similar from the dissimilar, the abstract from the concrete, so that you can place the similar in reusable modules and the different in unique modules. This is what I learned to do in my COBOL days when I created my first framework, and it is something which I have carried forward into every rewrite of that framework.
My framework contains the following objects:
There are no value objects as in PHP all values are held as simple variables.
How do you identify and create your domain/model classes? You first identify the various entities that will be of interest in your Business/Domain layer, then you look for patterns of behaviour which you can turn into properties and methods. You should isolate everything which is common and therefore sharable by placing it into a class, preferably abstract, which can be inherited.
Note that all domain knowledge is kept entirely with the Model classes for each domain/subsystem, which means that the Controllers, Views and DAOs are completely domain-agnostic. This means that they are not tied to any particular domain, do not contain any domain logic, and can therefore be used with any domain.
When creating classes you should avoid the following:
For an explanation look at David Raab's comment to the article Are You Still Debugging? in which he said the following:
A class with one method "is" a function! What is an object? A collection of data and functions (note the plural) that operate on this shared mutable state. What happens if you only have one function in a class? It is the same as one function outside of a class. There is no point in adding a grouping construct (class) around a single item.
It would be the same as if you put every single variable inside a one-element array. Sure you can do that. Does that makes sense? No. Is it better to put single variables inside one-element arrays? No. Only if you are a fanatic that believes that everything gets better if you put everything into arrays.
By the way, having classes that contain nothing but static methods is NOT object oriented because you can call those methods without creating an object beforehand, and if your code is NOT oriented around objects then it is NOT object oriented.
Once you have created a Model class with methods and properties you will need a second script to load and instantiate the Model so that various methods can be called. This second script is known as a Controller as it controls which methods are called on which domain object in order to satisfy a particular user request.
How is it possible to have a small number of reusable Controllers which interact with hundreds of Model classes? The simple answer is polymorphism. Each Model class inherits from my abstract table class which contains all the standard methods for communicating with a database table. Each Controller communicates with one or more Models using the standard methods which are defined in the abstract table class. Because of this simple arrangement any one of my Controllers is capable of communicating with any of my Models - all I have to do is tell it which one(s), and this is achieved through a series of unique component scripts. There is one of these tiny scripts for every user transaction in the application.
Putting the entire application into a single class would be as nonsensical as putting all your data into a single database table, so the normal approach is to break down the application into smaller modules, each with their own specific area of responsibility. In my pre-OOP days this was known as modular programming. In this way you should achieve two objectives:
The biggest problem the novice developer encounters with the notion of splitting something into smaller parts is knowing what to split and when to stop splitting. An application is much too large to be put into a single class, so what are the different responsibilities of an application which can be identified as separate units or components? In business applications which allow a user to view and maintain the data that is held in a database the next smaller unit is the user transaction (task). But again, creating a separate class for each user transaction would not be a good idea as it would still be far too large and would contain a lot of code that would be duplicated in other classes. It is therefore necessary to split each user transaction into smaller components with the intention of replacing duplicated code with a single copy that can be reused many times.
To answer the question How do you separate concerns?
Robert C. Martin wrote:
You separate behaviors that change at different times for different reasons. Things that change together you keep together. Things that change apart you keep apart.
GUIs change at a very different rate, and for very different reasons, than business rules. Database schemas change for very different reasons, and at very different rates than business rules. Keeping these concerns (GUI, business rules, database) separate is good design.
What he is describing here fits the description of the 3-Tier Architecture which has separate layers for Presentation (UI) logic, Business logic and Data Access logic.
An application consists of a number of user transactions (tasks), so it would be logical to split the application code into a separate module for each user transaction. Thus for each database table you should have separate transactions for the Create, Read, Update and Delete operations. By having each operation in a separate transaction it then becomes easier, via a Role Based Access Control (RBAC) system to grant a user access so some operations but not others. The Read operation should also exist in two forms - Enquire (for a single row) and List/Browse (for multiple rows). The next step would be to see if each user transaction could be split into smaller parts. This is where you start with the 1-Tier Architecture and progress through the 2-Tier to the 3-Tier Architecture. This may also be combined with the Model-View-Controller design pattern to produce a 3-Tier/MVC hybrid as shown in Figure 3. This architecture provides separate modules for separate tasks within each user transaction, and therefore follows the Separation of Concerns design principle (which may also be known as the Single Responsibility Principle):
This means that all knowledge of the application, all the data validation and business rules, are confined to the Business layer. All the other layers are completely application agnostic, which means that I can add new entities to the Business layer without having to amend any Controllers, Views or Data Access Objects. This matches the description of "Skinny Controller, Fat Model" in the article Fat Controller by Ian Cooper. This is the opposite of the "Fat Controller, Skinny Model" design which produces problems such as those described in Transaction Script and Anemic Domain Model as described by Martin Fowler.
When splitting a large class or module into smaller pieces you should avoid the tendency to go too far and create a plethora of minuscule classes as the resulting code will be so fragmented that it will become more difficult to understand, follow and therefore maintain. In his article Avoiding object oriented overkill Brandon Savage has this to say:
The concept that large tasks are broken into smaller, more manageable objects is fundamental. Breaking large tasks into smaller objects works, because it improves maintainability and modularity. It encourages reuse. When done correctly, it reduces code duplication. But once it's learned, do we ever learn when and where to stop abstracting? Too often, I come across code that is so abstracted it's nearly impossible to follow or understand.
A situation I have seen far too often is where someone takes a sensible piece of code and splits it unnecessarily into smaller units simply because of an over zealous (and in my view a perverted) interpretation of this principle. Remember that the definition of encapsulation is to create a class which contains all the methods and all the properties of an entity, so anyone who says that some of these methods or properties should be split off into other classes is breaking one of the fundamental principles of OO and is therefore not fit to lecture anyone about anything. The worst excuse I have ever heard regarding the over-splitting of code is to enforce the completely artificial rule that no method should exceed more than 10 lines of code (or however many can fit into a single page on your screen) and no class should have more than 10 methods. The idea behind this is that your mind can only take in what you can currently see in front of you on the screen. I'm sorry, but if you don't have the mental capacity to think about more than a single page of code at a time then you simply don't have enough mental capacity to be a programmer, and certainly not enough metal capacity to lecture me on how to write software.
Amongst the most stupid interpretations of the Single Responsibility Principle which I have encountered are the following:
getInstance() method inside each class, I have that method inside its own singleton class.All the while such perverse interpretations are allowed to go unchallenged the world will be inundated with bloated and incomprehensible code whose sole purpose is to provide employment for all those pseudo-intellectuals. That is why, for example, I think that creating 100 classes just to send a single email, as done in the SwiftMailer library, is complete and utter madness. This should be held up as a shining example of how not to write code.
My interpretation of the Single Responsibility Principle is quite simple - each of my Model (Business layer) classes is responsible for a single database table, and, following the rules of encapsulation, is responsible for all the properties and all the operations for that database table. The only subdivision that I will contemplate at this point is to split off the generation and execution of all SQL statements to a separate Data Access Object so that I can easily switch my DBMS engine between MySQL, Postgresql, Oracle and SQL Server. Some junior programmers of limited experience may say that this level of separation is unnecessary as, once created, an application will rarely switch to another DBMS, but as usual they would be missing the point. The key words here are once created, which means that when a customer installs my software I should give him a choice of different DBMS engines instead of restricting him to a single option. After the software has been installed the customer may never switch to another DBMS, but the DBMS that he starts with is his choice, and my software allows me to offer that choice simply by changing a single line in the configuration file.
More of my opinions on the Single Responsibility Principle/Separation of Concerns can be found in Not-so-SOLID OO Principles.
Simply dividing an application into lots of little classes will not guarantee that the application will perform well and be readable, understandable and maintainable. Care has to be taken in the design of each module, and the way in which control is passed from one module to another, so that you avoid the generation of spaghetti code, ravioli code or lasagna code. One way to judge the quality of software is to look for high cohesion and low coupling, as explained below:
| Cohesion | Describes the contents of a module. The degree to which the responsibilities of a single module/component form a meaningful unit. The degree of interaction within a module. Higher cohesion is better. Modules with high cohesion are preferable because high cohesion is associated with desirable traits such as robustness, reliability, reusability, extendability, and understandability whereas low cohesion is associated with undesirable traits such as being difficult to maintain, difficult to test, difficult to reuse, difficult to extend, and even difficult to understand.
More details can be found in OOP for Heretics. |
| Coupling | Describes how modules interact. The degree of mutual interdependence between modules/components. The degree of interaction between two modules. Lower coupling is better. Low coupling tends to create more reusable methods. It is not possible to write completely decoupled methods, otherwise the program will not work! Tightly coupled systems tend to exhibit the following developmental characteristics, which are often seen as disadvantages:
Note that this is restricted to when one module calls another, not when one class inherits from another. More details can be found in OOP for Heretics. |
| Dependency | Dependency, or coupling, is a state in which one object uses a function of another object. It is the degree that one component relies on another to perform its responsibilities. It is the manner and degree of interdependence between software modules; a measure of how closely connected two routines or modules are; the strength of the relationships between modules.
More details can be found in OOP for Heretics. |
There are some programmers who argue that Having a separate class for each database table is not good OO, but as they cannot offer any proof to support this claim I ignore them completely. OO afficionados may talk about associations, aggregations and compositions, but these do not require special treatment in a database, so I do not see why I should deal with them by inserting special code into my software. Every table is a separate entity in the database, so I cannot see why it should not also be a separate entity in my software.
When designing and building a separate class to handle each database table the novice programmer will first concentrate on the fact that each database table has a different structure and different business rules and should therefore require custom code to handle all these differences. By concentrating on the differences the novice programmer is failing to practice the art of abstraction which also requires the identification of any similarities. This leads to a programming style known as programming-by-difference in which the similarities are extracted and placed into a sharable module, such as a abstract class, while the differences are maintained in separate and unique modules, such as concrete classes. In this way each concrete class can share the similarities by inheriting from the abstract class while it contains nothing but the code which is unique to the table which it represents. If you cannot recognise the similarities with database tables then take a look at Standard patterns in every database application.
Novice programmers continually make the same mistakes by employing the following practices:
These have the effect of requiring enormous amounts of effort to manually create each table class, and the end result is tight coupling when the aim should be loose coupling. By adopting a different approach I have greatly reduced the amount of code required in each class which can now be created by an automated instead of a manual process, thus requiring far less effort. By recognising and taking advantage of the Standard patterns I have adopted a different approach which is as follows:
This is explained in more detail in The Road to Rapid Application Development (RAD).
As the amount of code I needed to produce for each table class had been greatly reduced I then noticed some similar patterns which allowed me to generate that code automatically using procedures which I built into my Data Dictionary.
Note that as well as being able to create the initial table class file at the touch of a few buttons this design also allowed any changes to a table's structure to be absorbed very easily. After changing the table's structure all that is needed is to repeat the procedure to import the metadata into the Data Dictionary and then export it to rebuild the table structure file. THis will not rebuild the table class file in case it has been amended to include any "hook" methods.
The traditional method requires a separate Controller to be manually constructed for every Model. This is normally the result of each Model having a separate property for each database column which then requires a corresponding set of setters and getters. The end result of this is that each Controller becomes tightly coupled to its one-and-only Model. Another mistake is to have all the user transactions (use cases) for a Model being handled by a single Controller.
Instead of having a separate Controller for each Model, which prevents the Controller from being shared, my own technique is to have a separate Controller for a particular user transaction which can then linked with any Model in the application. This is made possible because of my loosely coupled design. Every concrete table class supports the same set of methods by inheriting them from an abstract table class, and every class has its data passed in and out using a single $fieldarray variable. This then produces large amounts of polymorphism which I can then exploit by using Dependency Injection. This is demonstrated in the following code sample where a component script is used to "inject" a class name into a controller which loads and instantiates that class into a object before calling one of the many polymorphic methods:
-- a COMPONENT script <?php $table_id = "foobar"; // identify the Model $screen = 'foobar.detail.screen.inc'; // identify the View (a file identifying the XSL stylesheet) require 'std.add1.inc'; // activate the Controller ?> -- a CONTROLLER script (std.add1.inc) <?php require "classes/$table_id.class.inc"; $object = new $table_id; $fieldarray = $object->insertRecord($_POST); if (empty($object->errors)) { $result = $object->commit(); } else { $result = $object->rollback(); } // if ?>
I abandoned the idea of having a single control module being responsible for all the user transactions on a single database table as far back as the 1980s for reasons discussed in COBOL: Module functionality and later in Component Design ? Large and Complex vs. Small and Simple.
I have a separate Controller for each of my Transaction Patterns, each of which is linked to a particular View (or sometimes no View at all).
While researching PHP I came across two methods of constructing an HTML document:
Option #1 is a quick and dirty solution which is OK if you only have a small number of HTML pages. The disadvantage is that once you have output even a single character you cannot jump to another script using the header('location: ...') function otherwise you will get the 'headers already sent' error message.
Option #2 usually requires the use of a templating engine where you have a template which identifies the structure of the HTML document and has empty slots for the data. All the PHP script has to do before it terminates is to extract the data from whatever Model(s) it has been working with, inject it into the chosen template, then get the templating engine to spit out the result.
The fact that I have personally developed thousands of user transactions with screens at the front end has enabled me to spot repeating patterns in those user transactions. I broke down these patterns into separate categories - structure, behaviour and content - and devised a series of Transaction Patterns which combine a particular structure with a particular behaviour. The structures are provided by a small collection of XSL stylesheets, the behaviour is provided by a small collection of Controllers, and the content is provided by any of the available Model classes.
The extraction of data from the Model class(es) is made extremely simple in my framework simply because I use a single $fieldarray variable to hold all my application data instead of a separate property for each column. I can then retrieve all application data from a Model object using the single getFieldArray() method instead of a collection of getters.
I chose option #2 with my chosen templating engine being Extensible Stylesheet Language Transformations (XSLT) which I encountered during my work with UNIFACE. This uses data which has been loaded into an XML document and XSL stylesheets which identify the transformation rules. I originally used a custom stylesheet for each different web page where the column names and their positions on the page were hard-coded, as shown in Generating dynamic web pages using XSL and XML, but after a bit of refactoring I managed to create a small set of reusable XSL stylesheets which had the column names and their positions supplied in a separate screen structure file. This is loaded into the XML document where it is processed during the transformation process. This has allowed me to create over 4,000 different pages in my ERP application using just 12 (yes, TWELVE) XSL stylesheets.
This means that I have been able to construct a single standard procedure which can produce the HTML document required by any component in the application.
For CSV output I have the OUTPUT1 transaction pattern which will read the selected data one row at a time and write it to a text file. This has variations in the OUTPUT4 and OUTPUT6 patterns.
For PDF output I have the OUTPUT2, OUTPUT3 and OUTPUT5 patterns. These use a separate report structure file which is described in RADICORE for PHP - creating PDF output.
While novice programmers tend to manually code the SQL queries for each user transaction (task) within their Models this is very labour intensive in a large application which contains thousands of user transactions. To correctly deal with the principle of high cohesion and SRP/SOC the generation of all SQL queries should be handled in an entirely separate module. As this exists in the Data Access layer it is referred to as the Data Access Object (DAO).
By utilising a separate DAO module it should be possible to switch that model to another version in order to access a different DBMS. While some people say that once a particular DBMS has been chosen it is extremely unlikely for it to be changed are missing an important point which is embedded in the phrase once a particular DBMS has been chosen
. The advantage of the RADICORE framework is that it offers its users the choice of four different database engines - MySQL, PostgreSQL, Oracle and SQL Server - before they start their development.
Some developers create a separate DAO for each table with its own set of finder methods, but this again requires far too much effort. My approach is to have a single DAO for each DBMS which can handle all the queries for all the tables in that database. This can handle all the standard CRUD queries, which includes the ability to generate automatic JOINs to parent tables, but more complex queries can be handled by using custom code in the _cm_Pre_getData() method.
Note that I do not use PHP Data Objects as all it does is allow you to connect to a different DBMS very easily, but it does not allow you to switch from one DBMS to another after you have built your application. Once you have generated queries that run in a MySQL database you cannot switch to Oracle or SQL server due to differences in syntax.
My framework is used to create user transactions to view and maintain the contents of database tables. Some of the application components are generated by the framework:
I have used this framework to build the following applications:
Each user transaction makes use of the following reusable components:
If you do not have the same levels of reusability in your framework I strongly suggest that you stop trying to tell me that my methods are wrong and look instead at your own work as it clearly does not do what it's supposed to do.
More information regarding the levels of reusability which I have achieved can be found in the following:
Having identified that the bare essentials for OOP are nothing more than Encapsulation, Inheritance and Polymorphism I therefore regard anything else as an optional extra, an embellishment whose sole purpose is nothing but ornamentation, is cosmetic rather than functional. As these are optional it is therefore my choice whether I use them or not, and as a pragmatic programmer I choose not to use anything unless it passes some simple tests:
If none of those questions can be answered in the positive then I'm afraid that the feature or practice has costs without providing any benefits and can therefore be safely consigned to the rubbish bin as a complete waste of time. To put it another way, instead of:
Let's run it up the flagpole and see who salutes it.
each of these silly ideas should be subjected to the following acid test:
Let's drop it in the toilet bowl and see who flushes it.
If you look closely at the following list you will see that none of them is a PHP function which actually produces a result, they exist only for style and do not provide any substance.
In my humble opinion all the following ideas are excrement, not excellent, and should be flushed down the toilet:
I have been told many times that before you can code your classes you must first design them using Object Oriented Design which involves identifying entities and their relationships using is-a and has-a descriptors. You can then create your class hierarchies and identify all the method names that your application will require. The persistent data store (database) is not supposed to be designed until after the software components have been finalised, often requiring the use of mock objects for the database until the database has actually been built.
This goes against everything that I learned in my pre-OO days:
It therefore follows that the database should be designed first, the software should be designed last, and the software structure should be designed around the database structure. The idea that I should design my software components before I design the database, which may result in a completely different and probably incompatible structure, therefore strikes me as being counter-intuitive and totally wrong. I can achieve faster and more accurate results by designing my database first, then constructing a separate class for each database table (or, better still, have my framework generate the table classes from the database structure). In this way my database and software structures are always in complete harmony, which means that I don't need to employ one of those abominations called an Object Relational Mapper. This approach seems so natural to me that I have managed to automate it to such an extent that I can create my table classes, and the user transactions which perform the basic CRUD operations, in a matter of minutes without having to write a single line of code:
My critics keep telling me that Having a separate class for each database table is not good OO, but I find their arguments to be weak and without substance, so I ignore them. They also fail to realise experts such as Martin Fowler, the author of Patterns Of Enterprise Application Architecture (PoEAA), do not agree with this notion. Take a look at his Table Data Gateway, Row Data Gateway, Class Table Inheritance and Concrete Table Inheritance patterns if you don't believe me. In his article OrmHate the author also says the following:
I often hear people complain that they are forced to compromise their object model to make it more relational in order to please the ORM. Actually I think this is an inevitable consequence of using a relational database - you either have to make your in-memory model more relational, or you complicate your mapping code. I think it's perfectly reasonable to have a more relational domain model in order to simplify [or even eliminate] your object-relational mapping.
Note that the words or even eliminate are mine. Later in the same article he also says:
To use a relational model in memory basically means programming in terms of relations, right the way through your application. In many ways this is what the 90's CRUD tools gave you. They work very well for applications where you're just pushing data to the screen and back, or for applications where your logic is well expressed in terms of SQL queries. Some problems are well suited for this approach, so if you can do this, you should.
I have been building database applications for several decades in several languages, and I have personally designed and built many thousands of user transactions. No matter how complex an individual transaction may be, it always involves performing one or more CRUD operations on one or more database tables. All I have done is adapt my procedural programming method to encapsulate the knowledge of each database table in its own class, then use inheritance and polymorphism to increase code reuse and decrease code maintenance. This is supposed to be what OOP is all about, so how can I be wrong? In addition, because my class structures and database structures are always kept in sync I do not have any mapping code or any mapping problems.
My approach makes it very easy to develop database applications as I don't have to waste time on the following:
Template methods are a fundamental technique for code reuse. They are particularly important in class libraries because they are the means for factoring out common behaviour.Template methods contain a series of sub methods which can either be invariant or variable/customisable. The invariant methods are fixed in the abstract class while the variable hook methods can be defined in the subclasses in order to provide customised behaviour for each subclass.
Rather than pretending that the database is a second class citizen and that knowledge of the database structure and SQL queries should be kept hidden I prefer to do the exact opposite - I design my database first then build my components around the database structure with methods that correspond to database operations. This methodology is known as Table Oriented Programming.
SUMMARY: After designing the database I already have all the information I need to create my classes and all their methods, so I don't have to waste any time with OOD.
Domain Driven Design (DDD) is described as follows:
Domain-driven design (DDD) is a major software design approach, focusing on modeling software to match a domain according to input from that domain's experts. DDD is against the idea of having a single unified model; instead it divides a large system into bounded contexts, each of which have their own model.
This is not the way I see it. I was building enterprise applications covering such areas as Order Processing, Invoicing, Shipments and Inventory/Stock Control for 20 years in non-OO languages before I switched to PHP with its OO capabilities, and although each area has unique features which require a separate database and a separate collection of user transactions there are a surprising number of similarities. Every user transaction requires the following:
It is important to note that while the data being processed is different in each subsystem, the rules for handling that data in those three areas are exactly the same. The rules for handling HTML forms are the same regardless of the data, the rules for handling tables in an SQL database are the same regardless of the data, and the steps taken to move the data back and forth in the middle layer are the same regardless of the data.
The correct way to implement OOP is to provide as much reusable software as possible, and the way to do that is to abstract out the similarities from the differences, as explained in The meaning of "abstraction", so that the similarities can be provided in reusable components and the differences can be confined to unique components.
The first pattern is that each domain/subsystem has its own database, and while the contents of that database will be unique the structure will always follow the same set of rules:
The second pattern is that each event/task can be boiled down to it performing one or more operations on one or more tables, then displaying the result to the user either as HTML, CSV or PDF.
How can you convert these patterns into reusable code? When you write the code for lots of events/tasks you will probably come across the situation where you have written a task which does something on TableA, but now you want a new task which does exactly the same thing on TableB. What you need to do is break down the task into three distinct areas - structure, behaviour and content.
Each task will therefore become as simple as saying "Merge this Transaction Pattern (which provides the structure and behaviour) with this/these table(s) (which provides the content)". In the RADICORE framework this is known as a component script.
The notion that in DDD I must therefore design my software around the unique features of the domain is therefore rubbish. Every domain is simply another instance of a database application, so all I need do is go through the process of building a new database application with a new database schema. Once I have designed the database I do not have to go through an additional exercise of designing the class files which will support each table in that database as I can generate each class file using the database schema. In this way each class has knowledge of and is tied to the structure of its associated database table.
The notion that in DDD I must must create a method within the relevant Model which identifies each particular event/task is also rubbish. If I have 3,500 separate tasks and I have a separate method for each of those tasks then that immediately shuts out any prospects of polymorphism which any experienced programmer would tell you is a pre-requisite of Dependency Injection. By recognising that the only operations which can be performed on a database table are Create, Read, Update and Delete (CRUD) I have put the code for these methods in the abstract table class which is then inherited by each concrete table class. Every one of my Page Controllers communicates with its Model(s) using these methods which means that any of my Controllers can be used with any of my database tables. If I have 40 Controllers and 450 database tables this provides me with 40 x 450 = 18,000 (yes, EIGHTEEN THOUSAND) opportunities for polymorphism.
This topic is discussed further in Why I don't do Domain Driven Design.
I had always assumed that Object Oriented Programming was exactly the same as Procedural Programming except for the addition of Encapsulation, Inheritance and Polymorphism. They are both designed around the idea of writing imperative statements which are executed in a linear fashion. The commands are the same, it is only the way they are packaged which is different. While both allow the developer to write modular instead of monolithic programs, OOP provides the opportunity to write better modules. Imagine my surprise when I was told that it was much more complicated than that. I have replied to this ridiculous idea in What is the difference between Procedural and OO programming?
While reading that wikipedia article I was struck by two facts:
I do not like being told how to write code by people I do not know or trust. I will use the features of the language as I see fit in order to produce the best result. If you do not like my methods then you are free to ignore them, just as I ignore yours. I do not like being told any of the following:
When I am told that my methods are wrong I laugh so much that I can feel the tears running down my trouser leg. Anybody with more than two brain cells to rub together will tell you that something that works cannot be wrong just as something that does not work cannot be right. YOUR methods may work, but MY methods work even better simply because they make me more productive than you can ever dream to be.
An Object Relational Mapper (ORM) is the common solution to the problem of Object-Relational Impedance Mismatch. This is where the structure of the software components (classes) is different from the structure of the database components (tables), and where an extra component (mapper) is needed to act as an intermediary between the two in order to deal with the differences. The difference in structures is caused by using two different design techniques:
These two design methodologies supposedly consider the same factors - the data which needs to be manipulated (properties) and how it needs to be manipulated (methods) - but reach totally different conclusions. To me this signifies that one of the two methodologies is seriously flawed, and my experience with designing and building database applications over several decades has proven to me that the database design is far more important than the software design. Not only that, one of the fundamental principles of Jackson Structure Programming (JSP) is that the software structure should mirror the database structure as closely as possible. Having witnessed problems with applications where this has not been the case, and seen these problems disappear where this was the case, you will forgive me if my experience has led to the following simple rules:
For this reason I do not waste my time with Object Oriented Design. After designing and building my database I create the software components (classes) by creating a separate class file for each database table. I have automated this by building my own Data Dictionary which has import and export functions. Each table class then becomes the Model in the Model-View-Controller design pattern. Working user transactions are then created by combining a Model with one of my Transaction Patterns which use pre-written and reusable Controllers as well a pre-written and reusable Views.
I have written a more in-depth article on this subject which can be found in Object Relational Mappers are EVIL.
I am not the only one with a low opinion of Object Relational Mappers as can be seen in the following articles:
SUMMARY: When building a database application the database design comes first, and the software structure should mirror the database structure. This means that there is never any Object-Relational Impedance Mismatch in which case that abomination called an ORM is never needed.
Encapsulation is a process in which you first identify an "entity", something which has properties (data) and methods (operations which can be performed on that data), then you create a class for that entity. The class then becomes the 'capsule' or container for the data and operations. At no point does it say that the properties of an object must also be objects in their own right, so I prefer to leave them alone. This also avoids the overhead of creating objects where a simple variable will do.
There is a small number of programmers who claim that PHP is not a "proper" object oriented language because it does not treat everything as an object. Instead of procedural code such as:
$result = function($variable);
they want to see this style instead:
$result = $variable->function();
This is crap idea which should be flushed down the toilet for the following reasons:
PHP is a multi-paradigm language, just like C++, in that it supports both procedural and object oriented programming styles. This means that I should be free to use such things as procedural functions and data arrays as I see fit. I will not change such code to use objects unless there is a compelling reason to do so, and I'm afraid that satisfying the pseudo-requirements of the paradigm police does not fall into that category.
Rather than saying everything is an object
I am more inclined to say that everything is either a string or an array
. After all, the HTML output which is sent to the client's browser is a string, the SQL query which is sent to the database is a string, and the data which PHP receives following a GET or POST is an array of strings. So that which is not a string could be an array of strings. I personally still use procedural functions in my code because converting them into classes would require a great deal of effort and would not provide any benefits. There is no point in changing a function into a method unless it has to maintain state between calls. I would rather have a single file containing 100 functions than 100 classes each containing a single static method. I still use arrays of variables instead of objects because arrays provide all the functionality that I need without the overhead of creating objects. Too many developers are taught to avoid functions and arrays for no good reason other than "it's not pure OOP". I do not agrees with this idea of "purity", and I am not alone in this thought as can be found in an article called Are PHP developers functophobic?
SUMMARY: Use objects intelligently where they provide tangible benefits, not indiscriminately because "that is how it is supposed to be done".
The biggest question for novice programmers is What type of objects should I create? followed by which piece of logic goes where? While it is normal to start by putting all the logic into a same place, after you have done so this should be followed by some refactoring where you identify the different areas of logic and, by following the principles of Separation Of Concerns/Single Responsibility Principle, place the code for each distinct area into its own module. This is why we put all HTML code, SQL code and business logic into separate modules.
Simply splitting a large code base into a collection of small modules is not enough to make an application efficient and maintainable. You need to aim for high cohesion and low coupling, as explained in Cohesion, Coupling and Dependency.
Object Identity is describe as follows:
In object-oriented programming, analysis and design, object identity is the fundamental property of every object that it is distinct from other objects. Objects have identity ? are distinct ? even when they are otherwise indistinguishable, i.e. equal.
I question the notion that object identity is the fundamental property of every object for the simple reason that when I instantiate a class into an object it does not automatically contain a property called "identity". The term fundamental is supposed to mean necessary, so if it is necessary then how come an object can exist without it? How come this "fundamental property" is not mentioned anywhere in the PHP manual?
Later on in the same article it says the following:
Thus, identity is the basis for polymorphism in object-oriented programming.
This statement is rubbish. I have thousands of cases of polymorphism in my framework and none of my objects has a property called identity, so the two concepts must be totally unrelated.
In my framework, which deals with the manipulation of data within a relational database, the only "objects" which have a physical identity are the rows in a table which have primary keys. I never need to reference the identity of an object (instance of a class) only the identity of a row of data within that object.
PHP has never supported value objects which are described as follows:
In computer science, a value object is a small object that represents a simple entity whose equality is not based on identity.
When I say "support" I mean that value objects are not mentioned anywhere in the PHP manual. There can be various third-party userland libraries which offer value objects as an option, but personally all I see is a lot of wasted effort for absolutely no benefit. When you consider that PHP was designed to handle HTML forms at the front end, SQL databases at the back end, and business rules in the middle, and that both of the outer technologies make their data available as an array of strings and not an array of value objects, the effort of converting each of these string values into an object so that it can be processed by the business layer is, in my humble opinion, a complete waste of time. This is compounded by the fact that you have to convert each of the objects back into strings before they can be processed by the front and back ends.
As I can do what needs to be done without the use of value objects, and have done so for the past 20 years, I cannot see the point in using them. All I see its lots of effort without any benefit. Any code written to use value objects does not add value to a project, it adds bloat.
I have written more on this subject in Value objects are worthless.
PHP was designed to work with simple scalar values and not value objects, so I see any attempt to add unnecessary complications as a violation of both the KISS and YAGNI principles.
When constructing a class which represents a database table it is common practice to create a separate property for each column in that table, but is this the best practice? Few programmers realise that this produces tight coupling when the objective should be loose coupling. The way to achieve the correct level of coupling is quite simple - do not split the $_POST array into its component parts before loading it into the Model. This requires the Model to have a single property to hold all application data so that it can be inserted or extracted using a single variable. This can then cope with any amount of data being sent in from the user interface as well as that being read from the database.
Other benefits are discussed in Separate properties for database columns are NOT best practice.
Years after I had completed my framework and started to publish articles on what I had achieved and how I had achieved it I received complaints that what I was doing was wrong because I wasn't obeying the rules of OOP. I did not follow any such rules as I didn't know that they existed. In my previous 20 years of building numerous business applications in several different languages the only "rule" that existed was "use the facilities offered by the language as you see fit to achieve the most cost-effective result, and ensure that it can be maintained by others". I began to hear statements such as:
By leaving the $_POST array intact I can pass this array as a single input and return argument on all method calls. This produces loose coupling (which is a good thing) as I can change the contents of the array without having to change any method signatures.
One of the arguments I have seen in favour of the use of setters is when the application use separate methods for load(), validate() and store(), which means that it is technically possible to alter some application data after the validate() and before the store(), which could result in bad data being written to the database. My method avoids this scenario completely as once the insertRecord($_POST) or updateRecord($_POST) method has been called it is physically impossible to change any value in the array before the method has completed.
SUMMARY: There is no rule which states that I must pass data around one variable at a time, so when dealing with data sets which can contain of any number of rows and any number of columns it makes much more sense to me to pass the entire data set around as a single array variable. This does not prevent me from dealing with individual items in the array should I need to, but it requires much less code when passing the data from one object to another. Writing less code is supposed to be one of the features of OOP, so how can it be wrong?
Visibility is based on the idea that encapsulation is about data hiding which I have always thought of as being a stupid idea, because if the data is hidden then how are you supposed to move it in and out of the object?
Visibility allows an object's properties and methods to be declared as either public, protected or private. PHP4 did not have this capability, so everything was public by default. When this option was provided in PHP5 I decided not to use it for the following reasons:
There is a difference between stopping someone from doing something disastrous and stopping them from doing something which is perfectly valid and perfectly safe. If all occurrences of protected and private can be changed to public and the program still works as it should then it just proves that their use has absolutely no effect and is therefore a total waste of time. It is inessential, and by following the minimalist philosophy it can be removed.
Some people think that the visibility options are a requirement of OOP simply because they seem to think that "encapsulation" is the same as "information hiding", but this is simply not the case as explained in the following:
SUMMARY: Encapsulation is about enclosing an entity's data and the operations which perform on that data in a capsule known as a class. The internal workings of the class, known as the "implementation", are automatically hidden from view. The application data cannot be hidden otherwise you have no mechanism to put it in and get it out. Visibility does not provide any benefits to anybody, especially the end user. All it does is place restrictions on the developer. The idea of data hiding has always seemed strange to me. Surely in an application whose sole purpose is to move data between a GUI and a database then hiding that data defeats that purpose?
In all the OO code samples which I looked at on the interweb I noticed that each class had methods which were specifically linked to that class, so if I had classes for Customer, Product and Invoice I would end up with methods such as the following:
Considering that these methods are now specific to a particular Model, any Controller which communicates with any one of those Models would then become tightly coupled with that Model. This is supposed to be a bad thing as it reduces reusability and eliminates any scope for polymorphism.
I design and build user transactions for database applications, and every user transaction performs one or more operations on one or more database tables. Anybody who knows anything any database systems should be able to tell you instantly that there are only four basic operations which can be performed on a database table, and they are Create, Read, Update and Delete. In my architecture each database table is represented by its own class which is the Model in the Model-View-Controller pattern, which means that each class needs to support those operations, which means in turn that the Controllers need to use those operations (methods) on the Models with which they communicate. By performing a single 'read' operation on a database table I have instant access to all of the columns on all of the rows which satisfy that query, so I don't need specialised methods to get at individual rows or columns. My approach is to use generic methods which can be applied to any database table object, such as the following:
Note here that by defining all these methods in the abstract table class which is inherited by every concrete table class then $dbobject can be instantiated from any class in the application. This increases the scope for polymorphism and allows the Controllers to be used on any Model instead of being tied to a single Model.
I have even seen some code samples for methods which obtain specific values such as:
$balance = $object->getAccountBalance(); $tax = $object->calculateSalesTax();
I do not use such methods for the simple reason that I do not have to. The only object which would need to refer to a table column by name is the Model, and this would either be provided by the SQL query or provided internally. Neither the Controller nor the View would use such methods as they would only ever address the single data array and never a separate property for each column. The account balance should automatically be supplied when retrieving account data, just as the invoice balance should automatically be supplied when retrieving invoice data. Any sales tax should automatically be recalculated whenever an order line is added, updated or deleted.
SUMMARY: When dealing with database tables there are only four operations that can be performed - Create, Read, Update and Delete - so why do classes which deal with database tables require more than four methods? Having generic method names in all your table classes gives instant access to polymorphism and increases your capacity for reusable code. Using specialised method names eliminates polymorphism and makes the code less reusable, which is surely against the principles of OOP!
Some people say that you should have a separate method for each user transaction, but I see a problem with that idea. If you have a separate method then you need a separate component to call that method, and this totally eliminates the possibility of having sharable code.
In my basic RADICORE application with just its 4 subsystems there are 300+ user transactions, but in my main ERP application there are 20+ subsystems with over 4,000 user transactions, and the thought of having to create and maintain 4,000 unique method names strikes me as requiring too much effort.
My personal preference needs far less effort as it relies on maximum reusability. The significant points are as follows:
header("location: <script_id>)" command to be executed, where <script_id> is obtained from the MNU_TASK table.Every programmer should know that data values supplied by a user cannot be trusted and need to be validated/sanitised/filtered before they are used. This is especially true in a web application as all the data entered in an HTML form are strings, which means that the $_POST array is an array of strings. This allows the user to enter a value such as "10 green bottles" into a field which is only supposed to contain a positive number, and if you try to insert that value into a integer column in your database you will get a nasty surprise.
Where and how should this validation be performed? I have seen different suggestions from different people, such as the following:
All the sample code I have seen forces the developer to manually insert code to perform this basic validation. This then causes a problem if the structure of a table ever changes as the code has to be modified to deal with this change. Is there a better way. Can this procedure be automated. As an experienced programmer who has worked with databases for several decades I am able to answer "YES" to both of those questions. To speed up this process what you need is the following:
The data for point #1 already exists in the database and can be extracted using its INFORMATION_SCHEMA. You can either manually insert this metadata into your table class, or you can do what I do and construct a procedure to extract this information and write it to a table structure file which is loaded into the object by standard code within the constructor.
The data for point #2 should already exist in the object, but instead of a separate property for each column it would be far more convenient to hold it in a single $fieldarray variable. This is equivalent to the $_POST array before it is disassembled into its component parts.
Having these two sets of data then means that you can write a standard procedure which can be called automatically with the insertRecord() and updateRecord() methods. This will perform all primary validation without requiring any code to be inserted into the class. Secondary validation will require custom code to be inserted into the relevant "hook" methods.
I have automated this procedure by developing my own Data Dictionary which has functions to extract the data from the database and then export it to the file system. As well as allowing the class files for new database tables to be generated without having to write any code, any changes to a table's structure can be incorporated into the application simply by rerunning the the extract/export functions. This will not overwrite the table class file, but it will overwrite the table structure file.
Another practice in "proper" OOP which raised a red flag as soon as I saw it, such as in How dynamic finders work and PHP ActiveRecord Finders, was the use of specialist "finder" methods for database queries, such as:
The idea of creating such methods in my software never occurred to me for the simple reason that they don't exist in SQL. In order to select particular subsets of data in SQL all you need do is specify a WHERE clause in the SELECT statement, and this clause is nothing more than a simple string into which can be inserted a myriad of possibilities, such as the following:
field1='value1' field1='value1' AND field2='value2' (field1='value1' AND field2='value2') OR (field1='value11' AND field2='value12') OR (...) field1='value1' AND field2 [NOT] LIKE 'value2%' field1='value1' AND field2 IS [NOT] NULL field1 IN (SELECT ...) [NOT} EXISTS(SELECT ....) field1 BETWEEN 3 AND 12 ... et cetera, et cetera
This is why my framework contains only one method to retrieve data:
$array = $dbobject->getData($where);
The SELECT statement may be customised further by using any combination of the following:
$dbobject->sql_select = ('...'); $dbobject->sql_from = ('...'); $dbobject->sql_groupby = ('...'); $dbobject->sql_having = ('...'); $dbobject->sql_orderby = ('...'); $dbobject->setRowsPerPage(10); // used to calculate LIMIT $dbobject->setPageNo(1); // used to calculate OFFSET
By using a single $where argument it is therefore possible to specify anything which the database will accept, and because it is a simple string and not an object it is easy to view and modify its contents.
Note that the WHERE string is used to evaluate the values in columns. In order to evaluate the result of an expression you must use the HAVING string instead.
SUMMARY: The SQL language does not have separate finder methods to interrogate a database, just a single WHERE clause, so why should classes which access database tables be any different?
Multiple Inheritance provides the ability for a subclass to inherit properties and methods from more than one superclass and is not supported by PHP. So what? It is not supported in Java either, but that does not stop hordes of Java programmers from writing effective software.
I have been designing and building database applications for businesses for over 30 years, and I have never come across the need for multiple inheritance. If anybody thinks that they need it I strongly suggest that they think again. If they get their brains in gear and start firing on all cylinders they will eventually think of a simpler method.
For example, several years ago in one of the many PHP newsgroups there was a posting from a wanna-be programmer who complained that the lack of multiple inheritance in PHP was preventing him from writing effective software. He had a variable that he wanted to inherit from the "numeric" class as well as the "required" class, but the language wouldn't allow it. It wasn't the language that was the stumbling block, it was his block-headed approach to the problem. Let me make this absolutely clear - you do not need multiple inheritance to validate a variable's contents as this can be achieved using bog standard or plain vanilla code. In my own framework I would define meta-data for each variable using code similar to the following:
$this->fieldspec['price'] = array('type' => 'numeric', 'precision' => 11, 'scale' => 3, 'is_required' => true);
Validating that the 'price' value in the data array conformed to the above specifications would be an automatic process carried out by my validation class. When I say "automatic" I mean that I would not have to write any code to perform the data validation as this would be performed automatically by the framework. Each field/column in a database table has its own entry in $this->fieldspec, and each set of field specifications identifies the rules which need to be passed for that field's data to be considered as valid. As the number of rules is fixed for each data type, it is (for me at least) a trivial exercise to write code to test that the data for each field conforms to the given specifications for that field.
If there is a simple way then why choose something which is more complex?
Summary: Multiple inheritance is only a requirement in some people's designs. Other people can design workable solutions which do not need multiple inheritance.
This is where you first define an object interface which contains one or more method signatures without method bodies (i.e. without any code to implement them). Then you define a class which implements that interface, in which case you have to duplicate each method signature in your code, but this time with the method bodies in order to provide the implementation. As the main motivation for object oriented programming is software reuse I cannot see the point of using a facility which does not provide implementations which can be reused.
This topic is also the subject in a separate article entitled Object Interfaces are EVIL.
I found the following definition is wikipedia:
The use of interfaces allows for a programming style calledprogramming to the interface. The idea behind this approach is to base programming logic on the interfaces of the objects used, rather than on internal implementation details. Programming to the interface reduces dependency on implementation specifics and makes code more reusable.
As I don't use object interfaces I obviously cannot implement this principle. Even if I could I would not as, try as I might, I simply do not understand it. Program to the interface, not the implementation
is a meaningless statement as you cannot simply call an interface, you must call a method on an object which actually implements that interface.
I have yet to see a code sample which proves that this idea has merit, and until I do I will dismiss it as bogus. If this is supposed to mean calling a method on an unknown object where the identity of that object is not provided until runtime, then as a description of how to use polymorphism is is pretty pathetic.
This topic is discussed further in Object Interfaces are EVIL.
I have read about two different situations where mock objects are used:
The common method of building database applications by "proper" OO programmers is to start with the software design and leave the actual database design till last. After all, the physical database is just an implementation detail, isn't it? This requires the use of mock database objects which are easier to change than a physical database. OO programmers often complain that changing the database structure after the software has been built is a real pain because it requires lots of changes to lots of components. In my humble opinion this pain is a symptom of doing something which is fundamentally wrong.
This I call the Dyson approach because it sucks so much. My method is entirely the opposite:
Note that I don't have to write the class file by hand, it is generated for me by my Data Dictionary. My implementation also also makes it very easy to deal with database changes. Simply change the database structure, perform the import/export in my Data Dictionary and the job is done. I do not have to change any code in any Controllers, Views or the Data Access Object. I do not even have to change any code in the Model unless the affected column is subject to any business rules or secondary validation. I may also have to change a screen structure script if the column appears in or disappears from any HTML screens.
This seems stupid to me as all you are doing is testing the mock object instead of the real object, so what happens if your real object suddenly behaves differently and unexpectedly encounters a real error that you did not cater for in your mock object? One problem I have encountered on several projects for different clients is where some numpty changes the structure of a database table by adding in a new column with NOT NULL set but without a default value. This screws up any existing INSERT statements which have not been made aware of this database change as they will immediately fail because they do not provide a value for a NOT NULL column. No amount of testing with mock objects will deal with this, so if you want to test that your software can deal with real world situations you should test your real objects and not phony ones.
SUMMARY: I don't waste any time with mock objects, which means that I have more time to spend on real objects.
In OO theory class hierarchies are the result of identifying "IS-A" relationships between different objects, such as "a CAR is-a VEHICLE", "a BEAGLE is-a DOG" and "a CUSTOMER is-a PERSON". This causes some developers to create separate classes for each of those types and subtypes where the type to the left of "is-a" inherits from the type on the right. This is not how such relationships are expressed in a database, so it is not how I deal with it in my software. Each of these relationships has to be analysed more closely to identity the exact details. Please refer to Using "IS-A" to identify class hierarchies for details.
I also consider the construction of class hierarchies to be the cause of those errors which led to the rule "favour composition over inheritance". It has been known for decades that it is safer to only inherit from an abstract class, so doing otherwise is inviting trouble.
When I read the statement subtyping (implementation inheritance) provides polymorphism without code sharing while subclassing (class inheritance) provides code sharing without polymorphism
I was completely mystified as I had already been providing my applications with copious amounts of code sharing and polymorphism through class inheritance since I produced my first sample application way back in 2003. The heart of my framework is built around a single abstract table class which is then inherited by every one of my concrete table classes, of which there can be hundreds. This has allowed me to define all the sharable code in one place using the Template Method Pattern but to insert custom variations into any subclass by the use of overridable "hook" methods. It would appear that some earlier less sophisticated languages only allowed methods to be overridden if they had been defined as abstract methods in a interface instead of non-abstract methods in a superclass. This artificial restriction is described in more detail in Subclasses vs Subtypes.
In OOP an Association is described as follows:
It defines a relationship between classes of objects that allows one object instance to cause another to perform an action on its behalf.
Concrete implementation usually requires the requesting object to invoke a method or member function using a reference or pointer to the memory location of the controlled object.
This is not how relationships work in a database, so it is not how they are implemented in the RADICORE framework. If there is a parent-child relationship between two entities (tables) then my implementation works as follows:
As far as I am concerned all relationships follow a standard pattern:
For more details please refer to Object Associations are EVIL.
In OOP Composition implies that the contained class cannot exist independently of the container. If the container is destroyed, the child is also destroyed. This is represented in a database by having a separate table for each child, and each row in the child table has a foreign key, which is set to NOT NULL, which relates it to a row in its parent table. Thus a child row cannot be created without providing a value for that foreign key.
The idea that if two tables are related then I should have a single class to handle access to both tables simply does not exist in any DBMS with which I have worked, so it does not exist in any code which I write. Each table is a separate entity in the database which is subject to its own set of SQL queries, so it has its own object in the software. Access to a related table is handled by standard code in the framework using the relevant Transaction Pattern. This enables me to access the child table either with or without going through the parent table first.
For more details please refer to the following:
Object aggregation implies that the contained class can exist independently of the container. If the container is destroyed, the child is not destroyed as it can exist independently of the parent. Martin Fowler has this to say on the subject of aggregates:
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
This wikipedia page has this to add:
Objects outside the aggregate are allowed to hold references to the root but not to any other object of the aggregate. The aggregate root checks the consistency of changes in the aggregate.
For more details please refer to Object Associations are EVIL - Object Aggregation
I had no time for any of these theories as I had 20 years of practical experience with non-OO languages under my belt. Instead of creating custom methods within each table class to deal with each "association" I provided standard methods in my framework, thereby cutting down the amount of code which had to be written. I did not see any sample implementations of any of these theories which convinced me in any way that they could produce results as simple and effective as what I had already achieved, so I ignored them. I have compared the theoretical approach with my practical approach in the following articles:
The idea that if there is a relationship between two tables then I should create a single class to handle both tables as well as that particular relationship is, in my humble opinion, an anti-pattern. It is a bad idea because it reduces the ability to have reusable code where it should do the opposite and maximise reusability. The whole idea of using OOP in the first place is to increase the amount of reusable code so that you have less code to write and therefore less code to maintain. If you have a class that is responsible for more than one database table then it must have separate methods to perform the operations on each table, which means that those methods must have unique names. If you have unique method names then you immediately lose the benefits provided by polymorphism and dependency injection. If you have unique method names then you must have separate objects which call those unique names. This produces tight coupling which is supposed to be a Bad Thing ™.
Instead I prefer to have each table in a separate class so that it can share exactly the same method names for each of its operations by inheriting them from an abstract class. This means that I can have an object which calls the same methods on any table class which therefore provides more polymorphism and more opportunities for dependency injection. This produces loose coupling which is supposed to be a Good Thing ™. The use of an abstract class also enables the use of the Template Method Pattern which is is at the heart of framework design.
In the RADICORE framework each table (Model) class deals with nothing but the business rules for that particular table. I have worked with enough different flavours of relationship to work out how to deal with each in a standard fashion using code that is built in the framework without requiring any extra code that needs to be added to any Model class.
I have been told many times that I do not understand design patterns, that I am using the wrong patterns or not implementing the patterns that I do use in the correct way. I ignore such criticisms because to me they are nothing but nonsense as explained in my article Design Patterns - a personal perspective.
Here are some of my reasons:
Q: What patterns do I need to implement the MVC pattern?
A: You will need a Model, a View and a Controller, plus an Observer which detects when something in the Model has changed so it it can notify the View.
This strikes me as totally clueless for the following reasons:
What patterns do I need to implement pattern X?just leaves me speechless!
As well as the Model, View and Controller you will need an Observeris just as nonsensical. THE CLUE IS IN THE NAME, STUPID! If it's called Model-View-Controller then it is a safe bet that you will need a Model, a View and a Controller. If it really needed an Observer then it would be called the Model-Observer-View-Controller design pattern, now wouldn't it?
My own implementation could be described as MVCD as I have taken all database access out of the Model and put it into a separate Data Access Object (DAO) or Gateway.
Design patterns were developed by programmers who are superior to me in order to solve problems, so the more patterns I use the more problems I solve or avoid, even though I didn't know that I had those problems in the first place. Erich Gamma had this to say about that idea:
Trying to use all the patterns is a bad thing, because you will end up with synthetic designs - speculative designs that have flexibility that no one needs. These days software is too complex. We can't afford to speculate what else it should do. We need to really focus on what it needs.
He also said the following about using design patterns when there is no need:
A lot of the patterns are about extensibility and reusability. When you really need extensibility, then patterns provide you with a way to achieve it and this is cool. But when you don't need it, you should keep your design simple and not add unnecessary levels of indirection.
Do not start immediately throwing patterns into a design, but use them as you go and understand more of the problem. Because of this I really like to use patterns after the fact, refactoring to patterns.
This sentiment is shared by Dustin Marx who said:
The best use of design patterns occurs when a developer applies them naturally based on experience when need is observed rather than forcing their use.
In his summary of Head First Design Patterns Jeff Atwood wrote:
Patterns, like all forms of complexity, should be avoided until they are absolutely necessary.
For me design patterns are the wrong level of abstraction. I design and build database applications which consist of large numbers of user transactions, and design patterns never provide complete transactions or even components of transactions, just designs which then have to be implemented separately. I prefer to use Transactions Patterns as they provide reusable implementations, not just their designs, which then gives me ability to say "Take this transaction pattern and that class, now build me a working transaction" and I have instant access to runnable code. This is simply not possible with design patterns as they do not provide implementations in the form of reusable code. You cannot say "take this information, that design pattern, and generate working code", you have to write the code for each implementation by hand, and if you have to write each implementation by hand then where exactly is the reusability?
I have been told by several people that Transaction Patterns do not exist for the simple reason that nobody famous has written a book about them. This leads me to the following conclusions:
The only design pattern that I have ever implemented after reading about it was the Singleton. Even then I ignored every one else's implementation which had a separate singleton method inside each class (is that duplication or what?) and opted instead for a single abstract class called singleton with a single static method called getInstance. It may not be the "proper" way of doing it, but it has worked flawless for me for over a decade.
When I developed my PHP framework I designed it to use the 3 Tier Architecture which I had first encountered in the UNIFACE language. During this exercise I just happened to split my presentation layer component into two parts - one which interfaced with the user and another which created the HTML output using XML with an XSL stylesheet. Someone who saw my code remarked that by doing so I had created an implementation of the Model-View-Controller design pattern, but that was purely by accident and not by design (no pun intended).
XSL stylesheets are examples of real patterns as, once written, they can be used over and over again to produce predictable and repeatable results. All you have to do is vary the XML input. I have taken this one step further by creating Transaction Patterns which are based on reusable Controllers and reusable XSL stylesheets. All I have to do is say use this pattern with that database table
and at the press of a button I have a working transaction (or a family of transactions) which I can run immediately. If you cannot produce similar patterns which can be implemented with such little effort then it is you who needs to work on your pattern skills, not me.
SUMMARY: Design patterns do not provide reusable code templates, they simply provide descriptions of code which you have to write yourself. Transaction Patterns are far superior as they consist of pre-written code which can be used over and over again.
When writing software it is not acceptable to assume that everything will always work as expected. If you do, and something out of the ordinary happens, the result could either be that the program simply stops without telling you where and why it stopped, or it could produce erroneous results which may not be detected until some time later. Neither of these outcomes would be good, so we have to litter our programs with extra code to deal with unexpected circumstances. This code basically falls into one of two areas:
An example of a non-fatal error would be where user input contains an invalid value, such as a non-numeric character in a numeric field. When writing programs which deal with user input the only safe option is to validate each and every field thoroughly before attempting to do anything with it. If any of these validation checks fail then instead of moving forward the program should return to the user with an error message telling him/her which field is invalid and why. The user can correct his/her mistake and try again.
An example of a fatal error would be when writing to the database failed due to some error such as the connection being lost or a syntax error with the query. In such cases there is no point in going back to the user as there is nothing that the user can do, so the program should abort, preferably after logging all details of the error in some way, perhaps with the ability to email it to the system administrator. What the program should not do is ignore the error and carry on as if nothing had happened, otherwise the user will carry on working without realising that all his/her efforts are a waste of time.
Exceptions were invented to solve the Semipredicate problem where a function can only return a single output value which is either a valid result or an indication of failure (such as boolean FALSE) but without the ability to identify the actual reason for that failure. The solution is to change the function so that when it detects an error it can throw an exception which is separate from the normal result and which can then be caught by the calling code. So instead of:
$result = function($argument); if ($result === false) { ... the function did not work, but I don't know why! } // if
you replace it with code similar to the following:
try {
$result = function($argument);
} catch (Exception $e) {
$errmsg = $e->getMessage();
$errno = $e->getCode();
... code to handle the error
}
This requires the function to throw the exception using code similar to the following:
if (condition) {
throw new Exception('message text', 1234);
} // if
return $result;
Please note the following:
try/catch block and that function has not been coded to throw an exception then the catch block will never be executed.try/catch block then a PHP Fatal Error will be issued with an "Uncaught Exception ..." message, unless an exception handler has been defined with set_exception_handler().There are quite a few procedural functions in PHP which do not throw exceptions, but help is at hand with the $php_errormsg local variable which can be used as follows:
$result = fopen('foobar', 'r'); if ($result === false) { // $php_errormsg contains "fopen(foobar): failed to open stream: No such file or directory" } // if
Note that if you are using a custom error handler as described in Customising the PHP error handler you may need to change $php_errormsg to $GLOBALS['php_errormsg'].
Before I switched to developing in PHP4 I used other languages for several decades which also did not have exceptions, so I was familiar with writing code for the detection and handling of both fatal and non-fatal errors. When exception handling was implemented in PHP5 I looked at it but decided not to change the code that I had already written as it would not provide anything extra.
It is important to note that exceptions should only be used for exceptional (i.e. unforeseen) circumstances and not for those which can happen on a regular basis. In his article The Truth Behind the Big Exceptions Lie the author states that exceptions should only be used for issues that require you, the developer, to take action to resolve them. Data validation errors should never be regarded as exceptions as they are common occurrences, they are not fatal, there can be more than one, and they can easily be resolved by the user without intervention from a developer. If an input screen has 10 fields and each one of them contains invalid data then the user should be informed of all those errors at the same time. In my code when I detect that some user input has failed its validation I do not throw an error, I simply load the details into a class variable as in the following example:
function _cm_commonValidation ($fieldarray, $originaldata) // perform validation that is common to INSERT and UPDATE. { if ($fieldarray['start_date'] > $fieldarray['end_date']) { $this->errors['start_date'] = 'Start Date cannot be later than End Date'; $this->errors['end_date'] = 'End Date cannot be earlier than Start Date'; } // if return $fieldarray; } // _cm_commonValidation
In my Controller I don't have to catch any errors from the Model, I simply examine the $errors variable to see if it is empty or not, as in the following example:
$fieldarray = $dbobject->insertRecord($_POST); if ($dbobject->errors) { $errors = $dbobject->errors; } // if
As you should be able to see the $errors variable can hold any number of errors for any number of fields. If there are no errors then the insert operation worked and I can proceed to whatever step is next. If the $errors array is not empty then I inform the user and give him/her the opportunity to correct them.
Fatal errors are dealt with in a totally separate manner. I never throw them back to the calling object as there is nothing that the calling object can do except abort, so I perform my abort processing there and then. As many details as possible concerning the error, including a stack trace, should be logged so that the system administrators can identify the cause of the error and fix it as quickly as possible.
I developed my PHP framework several years before version 5 was released, which meant that I used version 4 which did not have exceptions, so what problems did this cause me? None whatsoever. As I write database applications a common place where something nasty can go wrong is when I execute an SQL query, but PHP4 provided everything that I needed, as shown in the following:
$result = mysqli_query($this->dbconnect, $this->query);
if ($result === false) {
$errno = mysqli_errno($this->dbconnect);
$errmsg = mysqli_error($this->dbconnect);
if ($errno == 2006) {
// connection has been lost, so re-connect and retry
...
} else {
trigger_error($this, E_USER_ERROR);
} // if
} // if
As you can see this does exactly what I want without the use of exceptions, and changing the code to use exceptions would not provide anything extra, so why bother?
While exceptions may have some use when dealing with procedural functions, as far as I am concerned they are totally redundant for objects as the object itself can supply the error details via a class variable without the overhead of creating a separate error/exception object. Look at the table below for the differences:
| Without Exceptions | With Exceptions | |
|---|---|---|
| throw |
if (condition) {
$this->errorMessage = 'Message text';
$this->errorCode = 1234;
return false;
} // if
This could be shortened to:
if (condition) {
$this->setError('Message text',1234);
return false;
} // if
|
if (condition) {
throw new Exception('message text', 1234);
} // if
|
| catch |
$result = $object->method($argument);
if ($result === false) {
$errmsg = $object->errorMessage;
$errno = $object->errorCode;
....
} // if
|
try {
$result = $object->method($argument);
} catch (Exception $e) {
$errmsg = $e->getMessage();
$errno = $e->getCode();
....
} // if
|
As with every other aspect of OOP which I have read about, exceptions can be used intelligently or they can be abused. Exceptions are supposed to be unexpected and rare events, so should not be used for common events such as data validation errors. They should also not be used to control the flow of logic. Other developers have encountered various problems with the use of exceptions, and their thoughts can be explored in the following articles:
If exceptions themselves are an unnecessary complication, some developers have to make the situation worse by introducing checked exceptions. This is where an object does not simply throw a single exception object with a variable error code, it throws a separate named exception for each different type of error. Every checked exception that an object can throw must be handled with its own entry in the catch block, as shown in the following example:
try {
.....
} catch (ThisException $e) {
.....
} catch (ThatException $e) {
.....
} catch (TheOtherException $e) {
.....
} catch (FooBarException $e) {
.....
} catch (SnafuException $e) {
.....
}
Fortunately PHP does not support checked exceptions, and I hope they never get introduced. I am not the only one who thinks that they are of dubious value as can be witnessed in the following articles:
SUMMARY: Exceptions were developed for functions, not objects. They were developed to get around a problem which functions have but objects do not. I can do everything I need to do without using exceptions, therefore I do not need exceptions.
Dependency Injection is a technique which allows a program to follow the Dependency Inversion Principle in which software modules are de-coupled. Coupling describes the degree of interaction or dependency between two modules where high or tight coupling is considered to be bad and low or loose coupling is considered to be good. It is not possible to write completely de-coupled methods as the application will not work. So, in my humble opinion, loose coupling is good whereas complete de-coupling does not produce benefits which outweigh the costs. It produces code which is more convoluted and less understandable, and therefore more difficult to maintain.
In the software world "dependency" is the degree that one component relies on another to perform its responsibilities. For example, If ModuleA calls ModuleB then there is a dependency between ModuleA and ModuleB. ModuleA is dependent on ModuleB as ModuleA cannot operate without ModuleB. On the other hand ModuleB is *not* dependent on ModuleA as ModuleB does *not* call ModuleA. ModuleB should not know or care about the identity of its caller.
In this situation ModuleA is sometimes described as the client which consumes the service provided by ModuleB.
In the 3 Tier Architecture the application consists of components which exist in one of three separate layers, as shown in the following diagram:
The different layers in the 3 Tier Architecture
")
In this architecture the Presentation layer is dependent on the Business layer because the Presentation object calls a method on a Business object in order to carry out its function. The Business layer is dependent on the Data Access layer because the Business object calls a method on a Data Access object in order to carry out its function. There are no other dependencies between these layers. In traditional programming each dependent object is instantiated in the calling object just before it is called.
In Dependency Injection the service object is instantiated outside the client and injected into the client when the client itself is instantiated. The service then becomes part of the client's state. For example, instead of the Data Access object being instantiated by the Business object just before its service is consumed it is instead instantiated by the Presentation object and injected into the Business object as a variable. The Business object then calls a method on this variable without having to instantiate a class into an object itself. While this particular scenario may sound correct, it actually violates the rules of the 3-Tier Architecture which state that no object in the Presentation layer can communicate directly with any object in the Data Access layer. This "communication" includes the knowledge of which DAO needs to be instantiated.
What is the benefit of DI (Dependency Injection)? When the service object can be instantiated from one of several classes and the class names are known before the client object is instantiated. A shining example of this is given in the Copy program described by Robert C. Martin in his article The Dependency Inversion Principle. This Copy program reads data from one device and writes in to another. Note that the input and output devices may or may not be the same. Although it would be possible to code the read and write operations for each device within the program, new devices could not be catered for without changing and recompiling the program. Another method would be to move the read/write logic into a separate class for each device. The input and output objects could then be instantiated from the relevant device classes and then injected into the Copy program so that it could then perform read operations on the input object and write operations on the output object. The Copy program would then not need to know any internal details of any of the device objects, and it is even possible to create classes for new devices without having to change or even recompile the Copy program.
It should be noted that in the above example each dependent object in the Copy program can come from one of a number of possible sources. Dependency injection allows for the actual source to be chosen outside of the program, thus avoiding having code within the program to choose from a list of possibilities. It should therefore be obvious that if a dependency can only ever be supplied from a single source that the overhead of allowing the dependency to be changed via injection would be a total waste of time. It would violate the YAGNI principle because you would be catering for the possibility that the dependency could come from multiple sources at some time in the future when your current design specifically states that the dependency will only ever come from a single source.
How is DI handled? The typical method which I have seen described over and over again is a three-step process:
While some programmers use DI in circumstances similar to those described in the Copy program above, others use it in their testing framework so that they can easily switch between real objects and mock objects. Others use it at every possible opportunity for no good reason other than they think it should be done that way. Personally I use DI as little as possible and only when there are distinct advantages. I do not use mock objects, so that argument is irrelevant. The only places where I find a use for DI is in my Controller and View objects. Consider the following code snippet from one of my page controllers contained in file std.enquire1.inc:
<?php require 'include.general.inc'; $mode = 'enquire'; // identify mode for xsl file initSession(); // initialise session // create a class instance for the database table require "classes/$table_id.class.inc"; $dbobject = new $table_id; // get data from the database $fieldarray = $dbobject->getData($where); // build list of objects for output to XML data $xml_objects[]['root'] =& $dbobject; // build XML document and perform XSL transformation $view = new radicore_view($screen_structure); $html = $view->buildXML($xml_objects); echo $html; ?>
The missing parts in this script - the values for $table_id and $screen_structure - are provided in a separate component script such as the following:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
Note the following:
Neither this script (the Controller) nor the View contain any hard-coded class names for the Model, nor any property names, so they will function with whatever class names they are given. This makes them both extremely reusable because they are loosely coupled. That is the only reason that I am using DI at all, because it makes the code reusable and not because I am following some stupid "rule" that I don't believe in.
What I do not do is use DI to inject my Data Access Object (DAO) into my Business layer (Model) component as advocated by some developers. For example, in Domain Models Should Not Depend on Data Layers (and its follow-up articles Let Presentation Depend on Data Access , Dependency Inversion and Use Events for Writes) it is argued that the DAO should be injected into the Model for no good reason other than it prevents a violation of the Dependency Inversion Principle. As I regard this principle as nothing more than snake oil I place absolutely no value in it and see absolutely no advantage in following it. In fact it is one of the rules of the 3-Tier Architecture that the Presentation object (Controller) must not have any contact with the Data Access object at - the Presentation layer (Controller) can only communicate with the Business layer (Model), and the Data Access Object can only be accessed by the Model. That is why I do not instantiate the DAO until the Model actually requires to access the database, in which case it calls a standard _getDBMSengine() method which identifies which DAO is required from an entry in the configuration file. Even though the DAO may be instantiated from one of several classes, and I may need different instances for different database servers, I can achieve this with standard code and without the stench of DI.
The idea that you need to completely decouple the Data Access layer from the Business layer I find to be completely without merit. There will always be a dependency between those two layers, so as far as I am concerned the only factor that needs further consideration is whether you have tight or loose coupling. Tight coupling results in components which are less reusable, so the real target should be loose coupling and not complete de-coupling.
In his article Repository Design Pattern Demystified the author tries to take this Dependency Injection/Inversion of Control madness to new levels by advocating the use of the Repository design pattern. The article tries to justify the use of this pattern by saying that there may be a future need to access more than one data source, but he only gives an example of a single data source and does not show how multiple sources could be included, either with or without the use of a repository. When I see how much code has to be written, and therefore has to be read by others in order to understand it, I am truly appalled. The article lists the following as pros for this approach:
The article lists the following as cons for this approach:
As well as the Model instantiating and calling the DAO only when necessary, the Model may have other dependent objects which it instantiates and calls when necessary. For example, a user transaction may have data which needs to be spread across several database tables, so how do I handle that? The Controller will call the insertRecord() method on the first table, and within this table class it will validate this data, perform an insert on this table, but before performing a commit it will execute the contents of the _cm_post_insertRecord() method which contains code similar to the following:
function _cm_post_insertRecord ($rowdata) // perform custom processing after database record has been inserted. { $dbobject = RDCsingleton::getInstance('other_table'); $other_data = $dbobject->insertRecord($rowdata); if ($dbobject->errors) { $this->errors = array_merge($this->errors, $dbobject->getErrors()); } // if return $rowdata; } // _cm_post_insertRecord
Notice that I don't have to filter the data that I pass to the 'other_table' object as each table object is responsible for filtering its own data. I can change the structure of the 'other_table' by adding, changing or removing columns, but I do not have to make any changes to the above code as none of the columns are identified by name - $rowdata is an associative array which can contain any number of 'name'='value' pairs. If the 'other_table' object encounters any errors (and there may be more than one) then they are added to $this->errors which causes the current transaction to terminate, and all error messages will be displayed on the current screen.
I can just see the OO purists frothing at the mouth and jumping up and down in a demented state yelling You have a dependency instantiated directly in a class which makes you tied to that implementation of the dependency, and this is a direct violation of the Dependency Inversion Principle!
My response is: So What? I need to pass control from this table object to the 'other_table' object, and this is by far the simplest and cleanest way to achieve that. The dependent object is identified, instantiated and consumed in a single place with the minimum amount of code. If this dependency ever changes I only have to change code in a single place. As a practitioner of the minimalist philosophy this approach is as perfect as it can be while your approach goes too far in completely the opposite direction.
If you dare tell me that this code is wrong and therefore unmaintainable I will have no option but to call you either a liar or an idiot. Anybody can read those 5 lines of code and understand instantly what it does, and to split that code up so that it is spread across 3 different places just to satisfy some theoretical principle which has no practical value in the real world could never be classed as an "improvement" by any stretch of the imagination. My technique is simple, concise, is easily readable, and it works. Changing it to follow the rules of DI would not make it any simpler or more readable or make it work better, so DI as an option has no value for me.
I am not the only one who thinks that DI is overrated. Check out the following articles:
SUMMARY: While loose coupling is better than tight coupling I do not believe that aiming for complete de-coupling is worth the effort. Dependency Injection has genuine value only in limited circumstances, so trying to use it everywhere does nothing more than add unnecessary complexity and make the code less readable and therefore less maintainable. People who follow the Dependency Inversion Principle (DIP) are nothing but DIPsticks. People who love Dependency Injection Containers (DIC) are nothing but DICkheads.
Some people think that Dependency Injection is so great that it should be used for every dependency even when there is only a single dependent object instead of a group of alternatives. Implementing a design pattern in places where it will not actually be used is never a clever idea. Please refer to Dependency Injection is EVIL for more details.
All the documents I have read regarding dependency injection claim that its purpose is to make a class independent of its dependencies
, but that is not correct. That is NOT its purpose, it is only the means by which it achieves its purpose. As I explain in this document the true purpose of Dependency Injection is to provide a mechanism to take advantage of polymorphism. DI enables you to call the same method signature on different objects, and having the same method signature available in different objects is called polymorphism. Without polymorphism there can be no Dependency Injection.
As well as NOT using dependency injection to deal with every single dependency in my applications, another argument against my simplistic approach is that I do not have any mechanism to manage my dependencies, such as a Dependency Injection Container (DIC). This is an object that knows how to instantiate and configure objects, and to be able to do its job it needs to know about the constructor arguments and the relationships between the objects. In some cases this object may contain a hard-coded list of objects and their dependencies, but it may instead obtain this information from an external XML or YAML file.
The argument that my critics use usually goes along the lines of "I have been taught to do so-and-so as it is the way it should be done, the proper way, the right way. You are doing something different, and as it it not the "right" way it must therefore be wrong!" This is a pathetic argument used by those who are lacking adequate experience of the real world. Today's young programmers are taught to externalise their dependencies and to use some sort of dependency management process, and when they see code which does not follow this so-called best practice they immediately go into panic mode. They only see that I am not following what they have been taught, but they totally fail to understand why I have done so. I have been programming for several decades without the need for any sort of dependency injection or dependency management, so I will not switch to using such devices unless there are obvious advantages in doing so.
If you read what I wrote in Dependency Injection you should see that there are basically two types of dependency:
For the former the identity of the chosen dependency is made in the previous script, as shown here. This is extremely simple, and there would be absolutely no advantage in using a separate "dependency container" or other sort of dependency management mechanism.
For the latter the dependency is identified, instantiated and consumed in a single place as shown here, and as there is no dependency injection there does not need to be any sort of external dependency management mechanism.
The term "decoupling" (which is the same as "uncoupling") is the opposite of coupling which comes into play when when one module calls another. This defines a dependency between the two modules. As an example, if module 'A' calls module 'B' then there is a dependency from 'A' to 'B' as 'A' requires the services of 'B' in oder to carry out its function. There is no dependency from 'B' to 'A' as there is no call from 'B' to 'A'.
The only way to decouple this dependency is to remove the call, which removes the dependency. Unfortunately this is not the way that some mis-informed programmers see it. In the article The Importance Of Decoupling In Software Development I found the following definition:
Decoupling is isolating the code that performs a specific task from the code that performs another task. It's important because it makes the code more maintainable, reusable, and easier to test. When you decouple functionality in your application, there is less chance of introducing errors when updating or replacing part of a system.
...
A common design pattern for solving problems like these is called Inversion of Control (IOC). IOC is a software architecture pattern where control flow goes against traditional methods. Instead of having modules dependent on each other, IOC works by having modules depend on an intermediary module with abstracted services. This intermediary module seamlessly manages all operations and allows you to switch between different service providers.
The term "intermediary" means "go-between", so it means introducing another module which goes between 'A' and 'B'. Thus instead of 'A' calling 'B' directly the call to 'B' is replaced by a call to 'I' (intermediary) and it is 'I' that now contains the call to 'B'. Some clueless newbies now that that because the direct call from 'A' to 'B' has been removed that the dependency from 'A' to 'B' has been removed and that 'A' and 'B' have been decoupled.
This is absolute nonsense. 'A' is now dependent on 'I' which in turn is dependent on 'B'. 'A' is still dependent on 'B', but the dependency is now indirect (through 'I') instead of direct. On top of that the single call from 'A' to 'B' has been replaced by two calls, 'A' to 'I' to 'B' which means that the volume of coupling has doubled. This could double the amount of problems caused by the ripple effect.
This topic is discussed further in Decoupling is delusional.
A Front Controller is a design pattern which provides a centralized entry point for handling requests. The Front Controller receives the request, does some standard processing, then passes control via some sort of router to the script which actually handles the request. Each request usually involves a single user transaction and a single web page, and the script can therefore be referred to as a Page Controller. The alternative to using a Front Controller is to use the web browser to pass control directly to the Page Controller.
Some developers say that you must use a Front Controller as it is the only way to deal with the request/route/dispatch/response cycle that exists in web applications. I completely disagree. I do not need separate components to handle the request, route and despatch parts for the simple reason that they are automatically handled by the web server. The web server receives a URL which identifies a script on the file system, the web server activates that script, that script does whatever it was programmed to do and then returns a result. I can go straight to the relevant script without the need for a separate controller, router and dispatcher, so if I don't need them then why should I use them?
A lot of the popular PHP frameworks use a Front Controller as a matter of course, which leads a lot of developers to consider that using a Front Controller is the standard. Some while ago a colleague told me that I should switch to this pattern for no good reason other than all the big boys use it, so if you want to be considered as one of the big boys you should use it too
. That was a pathetic argument then, and it is still just as pathetic now.
I am not the only one who dislikes the Front Controller. In his article The no-framework PHP MVC framework Rasmus Lerdorf (who created the PHP language) had this to say:
Just make sure you avoid the temptation of creating a single monolithic controller. A web application by its very nature is a series of small discrete requests. If you send all of your requests through a single controller on a single machine you have just defeated this very important architecture. Discreteness gives you scalability and modularity. You can break large problems up into a series of very small and modular solutions and you can deploy these across as many servers as you like.
What he is saying, in summary, is that you shouldn't waste your time in writing code which duplicates what the web server already does. Each user transaction should have its own Page Controller script, and the web server can use the URL to take you straight to this script without going through an intermediate router object. In this case the web server is the router, so writing your own router would be a duplication of effort and therefore a waste of time. Using a Front Controller is wasteful because you have to do two things:
I have written applications which contain thousands of user transactions, and each transaction has its own component script which looks similar to the following:
<?php $table_id = 'person'; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
Each of these scripts has its own URL, which enables the web server to activate it directly without having to go through a front controller. You should be able to see immediately that this uses an implementation of the Model-View-Controller design pattern, and it only identifies those components which are relevant to this user transaction. This means that you can quickly get to the meat of this transaction without having to navigate through a plethora of routers, factories, dispatchers, facades and service locators.
People say that the benefit of a front controller is that you can have all your initialisation code in a single place which you can execute before you pass control to your page controller. Such people must be totally unaware of one of the fundamental principles of computer programming, commonly known as the DRY principle, which is that of code duplication. Instead of having separate copies of the code in multiple places you create a single copy in a shared library which you can then call from as many places as you like. Each of my 40 page controllers, such as std.enquire1.inc for example, starts with the command initSession(), so the same copy of the standard initialisation code is always executed before the page controller does the rest of its stuff. Anyone who says that the existence of multiple calls to initSession() is itself a duplication of code should stand at the back of the room and wait for their brain cells to develop into something more than a gelatinous mass which does nothing but fill the gap between their ears.
The only time you absolutely need a Front Controller is when your entire application is compiled into a single executable program, in which case every time the program is run it will start from the same place. Even if your program has thousands of sub-programs, it will always have to go through the "program" part before it can be directed to the relevant sub-program. With PHP there is no concept of a single application, just a collection of individual scripts, each one representing a separate user transaction with its own URL. Each script is totally autonomous and only executes the code that it actually needs, so new scripts can be added to or subtracted from the application without have to touch any of the existing scripts. Because the web browser acts as the Front Controller it can pass control directly to the requested page without the need for any router.
PHP is not a compiled language in which all components of an application have to be combined into a single executable file with a single entry point. Each request is a separate discrete entity which has its own script in the file system, and each of these scripts can be accessed directly by the URL in the web server. All the functionality of a front controller is therefore already handled by the web server and does not need to be duplicated in the PHP code.
There is nothing I can do with a front controller that I cannot do without a front controller, consequently I consider a front controller to be a total waste of time and effort, so I choose not to waste my time with one. I have written an application which contains over 2,000 user transactions, and every transaction has its own URL which points straight at the Page Controller script which performs that transaction. This works perfectly without the need of a separate router object, so a router is not "necessary", and a front controller is not "necessary".
The only time I ever use a component which operates in the same way as a Front Controller is when providing web services as the server always operates through a single point of entry, a single URL. It then has to determine which operation needs to be performed on which object so that it can pass control to that object.
SUMMARY: Front Controllers replace functionality already provided by the web server, and as they do not add any value I consider them to be a waste of effort.
According to the PHP manual namespaces were added to the language to solve the following problems:
- Name collisions between code you create, and internal PHP classes/functions/constants or third-party classes/functions/constants.
- Ability to alias (or shorten) Extra_Long_Names designed to alleviate the first problem, improving readability of source code.
This identifies three different pieces of code:
There is no need to add namespaces into PHP core as it has nothing to clash with except itself. If any clashes do arise then it is up to that core developer to fix his mistake otherwise the code which he is developing cannot be released.
There is no need to use namespaces in your application code as it will generate a compile error if you use a name which has already been reserved by PHP. You should never use names which clash with another part of your application as that is indicative of a failure in project management.
This leaves only the third-party libraries which are developed outside of your application and which are imported into it at a later date. Because these libraries are developed by people who know nothing about your application they have no idea what names you have used, so they may use names which clash with yours. The only way to avoid any possible clashes is for every third-party library to incorporate their own namespaces, but it is now standard practice for all third party libraries to be installed via Composer, and that mandates the use of namespaces, so that solves the problem.
As I don't have any naming collisions or Extra_Long_Names there would be no benefit in changing my framework, or the applications which I have created using it, to use this feature, so the costs of such an exercise cannot be justified.
Another reason for me to refuse to use namespaces is that they must be written to conform to the PSR-4 standard which requires multi-level names which correspond to directory names in the file system. The directory structure used by RADICORE does not conform to PSR-4 (which it pre-dates by many years) as there is no top-level "vendor namespace" with a series of subdirectories. This standard was specifically designed to deal with third-party libraries constructed by different vendors, but RADICORE is not a library, it is an extendable framework, an application in its own right. It is not something that you can plug in to your own application. It can be extended by adding new subsystems, each with its own subsystem directory.
In spite of the fact that the use of namespaces is entirely optional, and provides a solution to a very limited problem, I see in the PHP internals newsgroup that some developers are attempting to make the use of namespaces mandatory by moving all the existing PHP functions and classes into the "PHP" namespace just so that the same names can be used in a different namespace. This would break backwards compatibility on a grand scale and as there would be no tangible benefit would therefore be totally unjustified.
SUMMARY: Namespaces were designed to solve a problem which I don't have, so I don't use them. They are an option, not a requirement, so I choose not to use them. They were designed for the developers of third-party libraries, and RADICORE is not a library, it is a framework. Their use has zero benefit to my customers, so the cost of converting my code to use them cannot be justified. Although I see no reason to change any part of my framework, or any of the applications which were developed using that framework, any potential name clashes with third party libraries is taken care of by virtue of the fact that all modern libraries use their own namespaces.
Further discussion on this topic can be found in the following:
SUMMARY: Namespaces were introduced to handle third-party libraries, and as RADICORE is a framework, not a library their inclusion would be a violation of YAGNI.
According to the PHP manual the autoloading mechanism was added to the language to solve the following problem:
Many developers writing object-oriented applications create one PHP source file per class definition. One of the biggest annoyances is having to write a long list of needed includes at the beginning of each script (one for each class).
This annoyance does not exist for me as not only do I never have to write a long list of includes at the beginning of each script, I never have to write any includes ever. How is this possible? Because all the necessary include statements are built into the framework components which means that I never have to write any in my application code.
Please refer to Autoloaders are abominations for more details.
SUMMARY: Autoloaders solve a problem which I don't have, and introduce new problems that I don't want, so I don't use them.
When I started my software development career using COBOL on a mainframe computer it wasn't sufficient to assume that just because a program compiled cleanly that it was free from bugs. It had to be tested to prove that it did what it was supposed to do, and this testing came in several stages:
All this testing was completely manual because hardware was expensive, people were cheap, and testing tools did not exist. As testing tools matured and it became both possible and cost-effective to write automated tests, this made the job of the QA department more efficient.
Roll forward several decades and we have a different situation. Hardware is cheap, people are expensive, and we have an abundance of testing tools. It is now possible to create automated tests which can run at the touch of a button, thus eliminating a great deal of manual effort. Unfortunately a large number of organisations which never had a separate QA department are under the impression that all this testing should be done by the developers, and this has caused a new religion called Test Driven Development (TDD) in which the tests are written first, then the code is written which passes those tests. I use the term religion because some people jump from automated testing being possible to automated testing being mandatory. Not only is it mandatory, but it must be done using their favourite tools according to their rules and their preferences. This attitude strikes me as arrogant and dictatorial. It raises a red flag in my experienced mind and gets my nose twitching in anticipation of the smell that is bound to follow.
In his article Self Testing Code Martin Fowler makes this observation:
But you can also produce self-testing code by writing tests after writing code - although you can't consider your work to be done until you have the tests (and they pass). The important point of self-testing code is that you have the tests, not how you got to them.
There are two significant points in this statement:
I would add a third important point to list list:
This thought is echoed in Test Cases Are Not Testing (PDF) where it says the following:
Programmers write code. This is, of course, a simplification of what programmers do: modeling, designing, problem-solving, inventing data structures, choosing algorithms. Programming may involve removing or replacing code, or exercising the wisdom of knowing what code not to write. Even so, programmers write programs. Thus, the bulk of their work seems tangible. The parallel with testing is obvious: if programmers write explicit source code that manifests working software, perhaps testers write explicit test cases that manifest testing.
He goes on to quantify why the skills required by testers are completely different from the skills required by programmers. If the skills are different there is no reason to expect a single person to have both skills.
Another lesson which I learned early on in my career is that the person who builds something should never be the person who tests it. That's why factories have an assembly line for the builders and a separate QA department for the testers. This is especially true in software development where the developer mis-interprets something in the program specification and therefore creates a bug which only the specification writer will trap. If the developer then writes a unit test with the same mis-interpretation then the test will pass, but the code will still be wrong. If there are no other tests before the software gets delivered to the client then the client will see that buggy software.
Unfortunately the ability to have automated tests which are written by the developers has been turned into an obsession. Too many managers seem to think that automated tests are an absolute necessity when in fact that they are nothing more than an expensive luxury. Too many managers seem to think that striving for 100% code coverage is a worthwhile goal. Too many managers seem to think that automated unit tests can completely replace all other testing - integration testing, system testing and acceptance testing. Too many managers seem to think that they can sack the QA department (if they had one in the first place) and move the burden of testing onto the developers. Too many managers fail to realise that developing and testing are different skills, and by making a developer spend more time on doing what the QA department used to do he has less time to do what he is supposed to do, which is develop software.
I have heard some programmers say that by writing their own unit tests they feel that they have become better programmers. This to me is a complete fallacy. As a programmer I am paid to write working code. Any time I spend writing unit tests is time NOT spent writing code and this must surely be a waste of my programming skills. Writing code and writing tests are different responsibilities, so expecting one person to carry out both responsibilities must surely be breaking the Single Responsibility Principle (SRP).
Another thing that most people fail to realise is that UAT (User Acceptance Testing) cannot be automated. It is not sufficient for the customers to run a program that after several hours outputs the word "Passed" on the screen. They actually have to run the software to prove to themselves that it is acceptable, that the GUI is pretty enough, that it easy to use, that it performs the functions they want as efficiently as possible. It is also necessary for them to test the system using data of their choosing so that it covers all the edge cases that are known to them, which may be more than the edge cases that were communicated to, or assumed by, the software vendor. When selling software to large corporations it is usual for the QA people from both the software vendor and the customer to get together to construct the test plan. This test plan is a written document, not a bunch of code. For each user transaction being tested it identifies a test number, how to navigate through the menus to reach that function, what the screen looks like, how the function responds to different inputs, and all the possible error messages. This test plan is usually run by the software vendor before it is given to the customer so that by the time the customer runs it is as 100% bug free as it can be. In theory when the customer runs the test plan there should be no issues, but in the real world practice and theory are different animals. Any issues need to be corrected and the tests rerun, and it is only when all the tests pass that the test plan can be signed off. This document then becomes written proof that the vendor has supplied what the customer asked for, and that the customer has accepted the software.
Rather than aiming for 100% code coverage, which attempts to test every line of code, in his article Selective Unit Testing - Costs and Benefits Steven Sanderson suggests a more cost-effective approach with these words:
I personally find I can deliver more business value per hour worked over the long term by using TDD only on the kinds of code for which it is strong. This means nontrivial code with few dependencies (algorithms or self-contained business logic).
I have only worked briefly with one testing tool (PHPUnit) and I found it impossible to run tests against the code which touched the database, used web services, or which communicated with the user via HTML forms or Ajax, so my manager's aim of 100% code coverage was a complete non-starter. It also tried to enforce naming conventions and a programming style which conflicted with my code - if any class name contained underscores it would replace all underscores with "/" characters and use each "/" as a directory separator when attempting to load the class. This is a show-stopper for me as I develop applications which talk to relational databases, and I have a separate class for each database table where the class name is the same as the table name. As the table names contain underscores it therefore means that the associated class names also contain underscores, but PHPUnit cannot load the classes because it buggers up the class name and looks in a nonexistent directory.
Here is a view of testing expressed by Steve McConnell:
Testing by itself does not improve software quality. Test results are an indicator of quality, but in and of themselves, they don't improve it. Trying to improve software quality by increasing the amount of testing is like try to lose weight by weighing yourself more often. What you eat before you step onto the scale determines how much you will weigh, and the software development techniques you use determine how many errors testing will find. If you want to lose weight, don't buy a new scale; change your diet. If you want to improve your software, don't test more; develop better.
The notion that you must have automated tests in order to catch all bugs before the software is delivered to the end user is not really cost-effective according to this quote from Bruce Schneier:
Microsoft knows that reliable software is not cost effective. According to studies, 90% to 95% of all bugs are harmless. They're never discovered by users, and they don't affect performance. It's much cheaper to release buggy software and fix the 5% to 10% of bugs people find and complain about.
In his article I don't love the single responsibility principle the author Marco Cecconi writes the following:
Designing for testability gives you testable code, but not necessarily readable or maintainable code.
Here are some other articles which express an opinion on the subject:
The main points I read in the above articles are:
If TDD is just another design process, then why should I switch from the design methodology which I have been using successfully for several decades? I can write code faster than I can write tests, so how can TDD make me more productive? I do not believe that TDD will cause my designs to be better, nor will it make me more productive as a developer, so unless you can justify that the benefits are worth the costs then I shall treat TDD as just another passing fad and ignore it completely.
For many years I worked in organisations which had a Quality Assurance (QA) department of software testers who were totally separate from the software developers, just as the people who write the user manuals are totally separate from the developers. Development, testing and documentation are areas which require different sets of skills, so are performed by different groups. While the developer may be able to test his own code up to a point what you must remember is that he wrote code to implement the assumptions he made based on his interpretation of the program specification, and any tests he performs will simply test those same assumptions. But what if those assumptions are wrong? That is where additional pairs of eyes in the form of the QA department can be invaluable, as described in the following articles:
Some people seem to say that TDD actually speeds up the development process, but I could not disagree more. If I can build a new database table, then build a family of transactions to maintain that table - List, Create, Enquire, Update, Delete and Search - in five minutes (yes,I did say five minutes) without having to write a single line of code, how much time are you prepared to wait while I write a second piece of software which proves that the first piece of software actually works?
I once worked on a contract with a start-up company where my task was to design and develop web service APIs so that external merchants could integrate their software with ours. I was the sole developer working closely with the Merchant Integration Team using a set of simple APIs which had been built by a previous contractor. In order to get as many merchants signed up to the system as quickly as possible I had to make modifications to deal with any merchant's particular quirks. Some merchants had software which could use web services, but could not handle our data formats, so I had to write code to map their format to ours. Some merchants had software which did not have any web service capabilities at all, so I had to write additional code to send and receive CSV files via FTP. Some merchants did not want to push their data to our website, they wanted us to pull the data from theirs on a varying schedule, which meant that I had to design and build a whole new process to handle this. A fast response to changing requirements was required, and a fast response was what I delivered. All this was done without any automated testing as all testing was manual. Six months into a the contract in steps a new manager who was bitten by the TDD bug and who insisted that code could not be released into production until it had passed its unit tests. A good idea in theory, but in practice it created nothing but problems:
Here are some reasons why I don't like to waste my time in building automated tests:
Just because I don't write automated tests does not mean that I release untested and therefore buggy software. Being a developer from the old school I still do my testing the "old school" way. I don't wait until I've written all the code before I start testing. I think a bit, write a bit of code, then test that bit of code. I continue with this think-code-test cycle until the job is finished, having done any refactoring along the way, then I hand it over to someone else to test and release.
Just because *I* don't write automated tests does not mean that I think that automated tests in themselves are a bad idea. Coming to grips with the various testing tools which are available, and then writing the tests themselves, should be considered as a skill which is entirely separate from software development. Some people recognise this separation of responsibilities as I often see jobs being advertised for "software testers" with different skills than "software developers". Instead of the QA department being disbanded and their duties being taken over by developers - which will have a detrimental effect on developer productivity - the QA department should be encouraged to write automated tests of their own.
However, when developing enterprise applications for particular markets such as the pharmaceutical industry, the need for automated testing is overruled by the need for manual testing which can be documented and signed off. The software designers and the users get together and create a Test Plan which identifies every user transaction and every set of options with their expected results, sometimes with screen shots or other output examples. This can result in a document which is hundreds, or even thousands of pages long. When the application development has been completed the software designers run through the test plan as part of their Integration Testing, and pass any defects back to the developers so that they can be fixed. When all defects have been corrected it is then the turn of the users to run through the same test plan as part of their User Acceptance Testing (UAT). When the UAT has been completed the users add their signatures to the test plan, and this turns it into a legal document which identifies both what the users expect from the application and proof that it meets those expectations.
SUMMARY: Automated unit testing is expensive and may not be cost-effective at all. If done by the developers it seriously reduces the amount of time that they can spend on their primary task, which is to develop code. Testing is a separate skill and should therefore be handled by a separate department.
I'm a firm believer in the old adage that no job is finished until the paperwork is done. While I believe that each piece of source code should contain proper comments which explain each section of raw code, I do not believe that external documentation should be extracted from these comments as in themselves these comments are not enough. I have always written external documentation by hand and will continue to do so. This external documentation expands on and is in addition to the comments in the source code. It describes how each piece fits into the whole, possibly with some code samples and even some diagrams where appropriate. For an example of the handwritten documentation for my Radicore framework please take a look at A Development Infrastructure for PHP, User Guide to the Menu and Security System and Functions, Methods and Variables.
Lots of developers use automated documentation today for various reasons:
I can safely say that without exception every piece of automatic documentation that I have come across has been virtually useless. It is like taking a 1000-piece jigsaw and providing a technical description of each individual piece. While the description of each piece might be technically accurate it does not help in describing the "big picture", it does not help in describing how the pieces work together or how the individual modules contribute to the application as a whole.
I also do not like having to put those awful docblocks all over my source code so that they can be extracted by the PhpDocumentor program. I would rather keep my source code short and sweet and invest the time in producing human-readable instead of computer-generated documentation.
SUMMARY: Automated documentation is no substitute for the real thing, and trying to extract from the source code does nothing but make the source code ugly and less readable.
Annotations (now called Attributes) are specially formatted entries in the comments of a source file that control its runtime behavior. They can be used for such things as configuration, routing (for front controllers, which are bad in themselves), and meta-data. The main argument for this "feature" is that other languages have it, so PHP should have it as well. Here is an example:
/** * @Column(type="string", length=32, unique=true, nullable=false) */ protected $username;
You may look at that code and say "Wow! that's clever!" but I look at it and think WTF!! simply because there is a much simpler method of achieving exactly the same thing with standard PHP code. In my own framework I would use something like the following:
$this->fieldspec['username'] = array('type' => 'string', 'size' => 32, 'primary_key' => true, 'is_required' => true);
The advantage of my method is that I never have to create or modify that code by hand. It is generated for me from my Data Dictionary after I have imported the database structure. I also don't need any special annotation parser to extract the information to make it usable at runtime.
There are other advantages of having this meta-data available in such a standard fashion:
I can also describe all relationships between tables using standard PHP code. Where some frameworks use annotations like this:
/**
* @Entity
* @Table(name="ecommerce_products",uniqueConstraints={@UniqueConstraint(name="search_idx", columns={"name", "email"})})
* @ManyToMany(targetEntity="Phonenumber")
* @JoinTable(name="users_phonenumbers",
* joinColumns={@JoinColumn(name="user_id", referencedColumnName="id")},
* inverseJoinColumns={@JoinColumn(name="phonenumber_id", referencedColumnName="id", unique=true)}
* )
*/
I can use standard PHP code such as this:
$this->primary_key = array('field1', 'field2'); $this->unique_keys[] = array('field3'); $this->child_relations[] = array('child' => 'tblChild', 'type' => 'RES', // REStricted, CAScade, NULlify 'fields' => array('fldChild1' => 'fldParent1', 'fldChild2' => 'fldParent2')); $this->parent_relations[] = array('parent' => 'tblParent', 'fields' => array('fldParent1' => 'fldChild1', 'fldParent2' => 'fldChild2'));
Again because this is standard PHP code I can generate it from my Data Dictionary and read it without the need of any special annotation parsers.
My view on annotations is quite simple: comments should never have any impact on code behavior. Ever. That is not just my personal opinion as the same sentiment is shared by others:
If you think that annotations are a good idea it just shows that you have a lot to learn. If you don't know how to achieve the same results with standard, plain vanilla code then as a writer of readable code you are a total failure.
SUMMARY: Using comments to affect runtime behaviour is a stupid idea. Anything that can be done with annotations can be done with plain vanilla code, so learn how to write plain vanilla code instead of those I-think-it's-clever-but-it's-actually-stupid alternatives.
An Anonymous Function, which may also be known as a Lambda or Closure, allows the creation of functions which have no specified name. They can be stored in a variable and passed as an argument to other functions or variables. So instead of:
function FooBar ($argument) { .... return ... } $result = FooBar($arg);
we can have the following:
$fooBar = function ($argument) { .... return ... } $result = $fooBar($arg);
A Closure is slightly different from a Lambda it that it enables variables defined in the parent scope to be accessed.
$fooBar = function ($argument) use ($var1, $var2 , &$var3) { .... $var1 ... $var2 ... $var3 return ... } $var1 = 'something'; $var2 = 'something else'; $var3 = 'something different'; $result = $fooBar($arg);
This may look clever to you, but if I can achieve the same result with bog standard plain vanilla code then why should I use a previously-unknown alternative that did not exist until recently? If I have to support users of my code who are still using an earlier version of PHP then I cannot change my "working" code to this "clever" alternative without breaking backwards compatibility, and supporting my users is much more important to me than being clever in the eyes of other developers.
SUMMARY: I can already do what needs to be done with plain vanilla code, so changing existing code to do the same thing but in a "clever" way would not be a cost-effective use of my valuable time.
Generators provide an easy way to implement simple iterators without the overhead or complexity of implementing a class that implements the Iterator interface.
The example in the manual shows how to use foreach to iterate over an array of data without the need to build the entire array in memory beforehand, which for very large arrays may cause you to exceed a memory limit, or require a considerable amount of processing time to generate.
SUMMARY: Generators are an example of clever code which provide benefits only in limited and specific circumstances. In decades of programming I have never written any code which would benefit from being rewritten using a generator, so I consider this feature to be a worthless addition to the language.
Enumerations are a restricting layer on top of classes and class constants, intended to provide a way to define a closed set of possible values for a type.
I first came across the enum datatype in MySQL. I stopped using it for the following reasons:
I used the enum datatype to provide a list of options for either a dropdown list or a radio group. These have an internal value and an external representation (what the user sees) and were known as ValReps in the UNIFACE language. They can be provided from an associative array where the "key" is the internal value and the "value" is the external representation.
My PHP solution involved the following steps:
If the contents of the list are static I store the list of allowable values as an associative array in a file called language_array.inc which is held in directory <subsystem>/text/<language_code>/ where:
<subsystem> is the subsystem name<language_code> is the language code (as shown in directory structure)If the contents are dynamic I store them in a database table.
I do not like the way that Enumerations have been implemented because I see them as nothing more than a complicated way of doing something which I have already done for decades using simple code. They require the use of class-like structures to maintain the list of options whereas my version uses simple lists of data either from a disk file or a database table. I can change the contents of these lists without having to amend any code.
This is also described in FAQ09 - How to incorporate dropdown lists or radio groups.
Mixins are defined as follows:
In object-oriented programming languages, a mixin is a class that contains methods for use by other classes without having to be the parent class of those other classes. How those other classes gain access to the mixin's methods depends on the language. Mixins are sometimes described as being "included" rather than "inherited".
Traits are defined as follows:
In computer programming, a trait is a language concept that represents a set of methods that can be used to extend the functionality of a class.
The two terms have the same effect which is to simulate multiple inheritance by being able to 'include' additional superclasses instead of using the keyword 'extend'. In PHP the implementations have been merged under the name Traits. A trait is similar to an abstract class in that it cannot be instantiated into an object, it can only be included (but not inherited) into another class. There is no limit to the number of traits which can be included into a class.
I eventually found a use for traits in the ERP application which I built using RADICORE when I enhanced the usage of User Defined Fields. These are custom fields which can be defined by the user, and originally they were maintained and viewed using screens which were separate from the core application. When one of my users complained that this was too clunky and "wouldn't it be nice if these user defined fields were treated in the same way as standard fields" I looked at ways that this could be implemented. This required an addition to the standard processing, but only for a small number of tables which had this ability turned on. All the standard processing was already handled in my abstract table class, but extra processing was required for those core tables which had this option turned on. What was needed was a way to process additional methods in the standard flow for these tables. What I needed was to add some extra methods into my abstract class.
I found the solution using traits. I first created the trait class to contain the new methods:
filename: include.user_defined_fields.trait.inc <?php trait user_defined_fields { var $udf_fieldspec=null; // fieldspecs for user-defined fields var $udf_dropdown=null; // dropdown lists for user-defined fields function _udf_getColumnSpecs (.....) {.....} function _udf_getColumnValues (.....) {.....} function _udf_addFieldsToScreen (.....) {.....} function _udf_updateFields (.....) {.....} function _udf_setSearch (.....) {.....} function _udf_adjustQuery (.....) {.....} } ?>
I then updated my abstract class to process these new methods, but only if they had been included:
filename: std.table.class.inc <?php abstract class Default_Table { ..... if (method_exists($this, '_udf_getColumnSpecs')) { $result = $this->_udf_getColumnSpecs(.....}; ..... } ..... } ?>
For each core table which used this option I amended the class files as follows:
filename: foobar.class.inc <?php require_once 'std.table.class.inc'; require_once 'include.user_defined_fields.trait.inc'; class foobar extends Default_Table { use user_defined_fields; // include methods from this trait ..... } ?>
Easy Peasy Lemon Squeezy.
I have never bothered with type hints simply because I was taught to provide a hint in the name of each variable. That was good enough for me in my 20 years of programming before I switched to PHP, it was good enough when I created my framework in PHP 4, and I see no reason to change the habit of a lifetime. Besides which I never use a new feature in the language unless it provides some sort of benefit, and even if I invested time in updating my entire code base I would see no reward. Another reason I disliked this feature was I could see straight away that its initial purpose of providing type hinting would eventually be changed into type enforcement, and I did not want to see PHP's dynamic typing abilities converted to static typing as I saw that as a backward step.
There is a theory amongst a large number of programmers that strictly type languages are superior to dynamically typed languages. If these ill-informed novices did their homework they would realise that the truth is the exact opposite. They think that Type Safety is the exclusive domain of strictly typed languages, but that is far from being correct. In the early languages which did not check a variable's type any mismatch in a function's arguments would cause a crash at run time. This was fixed in compiled languages which introduced type checking at compile time. A type error would cause the compilation process to abort, and to fix this the programmer would have to change the code.
Static type checking is only practicable in those languages where data from external sources, such as the user interface or the database, are presented in variables which already have the correct type, but this requires the use of pre-defined static data structures which are then compiled. If it was ever necessary to convert a value from one type to another then the language would provide a function to perform this conversion. It was then up to the developer to insert the code to call this function manually.
PHP, being dynamically typed, does not have a separate compilation process, so type errors can only be detected at run time. The potential for type errors is greatly increased due to the fact that data from external sources cannot be presented in pre-typed structures as neither the HTTP nor SQL protocols use static structures, they use dynamic structures in the form of arrays in which all the values are presented as strings. This means that whenever anything other than a string is required a type mismatch will occur. However, what a lot of dumbos fail to realise is that PHP has a more sophisticated mechanism of dealing with these mismatches, as described in RFC: Strict and weak parameter type checking, which is consistent with the C-based functions on which PHP is based. The logic is quite straightforward - if the language detects that a value has the wrong type, and it has a function which can convert that value to the expected type, then it can automatically call that function to bypass the error without forcing the developer to call that function manually.
So, unlike strictly typed languages which will automatically throw a Type Error, PHP will use its superior abilities to automatically fix that error. The only reason that this behaviour will fail is when the string value cannot be converted into the expected type, such as converting "ten green bottles" into an integer. It is therefore imperative that all input from the user be validated so that nonsense values can be reported to the user before they are sent to the database. Users of the RADICORE framework do not have to write their own code to do this as the in-built validation object handles it for them.
What the fans of strict typing fail to realise is that when this option is turned on you must add code to prime the pump before it will work properly, and the act of adding code to do manually what PHP can already do automatically should be regarded as a waste of effort and a violation of YAGNI.
I have learned to love the fact that I don't have to waste time writing redundant code to deal with type errors (except those introduced by the incompetent core developers) so I'm afraid that strict typing will be just another one of those options which I refuse to use.
I have written further on the topic of strict typing in the following:
Please also refer to:
There are far too many programmers who think that writing efficient code means writing code with as few keystrokes as possible. They try to squeeze as many instructions as they can into a single line, then they stand back and say "Look how clever I am!" What these clowns fail to realise is that clever code is more difficult to read than simple code, and that the maintainability of a piece of code is directly proportional to its readability. The easier it is to read a piece of code the quicker it is to understand what it does and how it does it, which then makes it easier for that piece of code to be maintained in the future. Program code is read more often than it is written, so saving a few keystrokes at the writing stage is a bad idea if it slows down the reading and understanding stage.
A shining example of unreadable compact code is given by Dylan Bridgman in his article Writing highly readable code in which he shows the following code snippet:
<?php // data $a = [ ['n'=>'John Smith', 'dob'=>'1988-02-03'], ['n'=>'Jane Jones', 'dob'=>'2014-07-08'] ]; // iterate the array for($x=0;$x<sizeof($a);$x++){/*calculate difference*/$a[$x]['a']=(new DateTime())->diff(new DateTime($a[$x]['dob']))->format("%y");} ?>
When this is written properly with one statement per line it becomes much quicker to read and understand, as shown in the following:
<?php // data $a = [ ['n'=>'John Smith', 'dob'=>'1988-02-03'], ['n'=>'Jane Jones', 'dob'=>'2014-07-08'] ]; // Calculate and store the age in years of each user foreach($users as &$user) { $today = new DateTime(); $birthday = new DateTime($user['dob']); $age = $today->diff($birthday); $user['age'] = $age->format("%y"); } unset($user); ?>
Anyone who says that they can read and understand the first code snippet just as fast as the second is a liar. If you look carefully you will see that the second code snippet is actually more efficient as it does not have to evaluate sizeof($a) within every iteration. It could be made even more efficient by moving the line $today = new DateTime(); to outside the loop as this only needs to be evaluated once.
Another article which follows this line of thought can be found at Avoiding one-liners in PHP which shows that squeezing multiple expressions into a single line makes the code less readable and difficult to debug by setting a breakpoint on a single expression.
Another variation of this code compression is called method chaining (also known as fluent interfaces) which allows several method calls to be squeezed into a single line, such as in the following example:
<?php $person = new Person; $result = $person->setName("Peter")->setAge(21); ?>
Again this may seem "clever" and "efficient", but it is less readable than the long-hand equivalent, and being more difficult to read it is automatically more difficult to maintain and therefore should be avoided. See Fluent Interfaces are Evil for more details.
Sometimes a change can be made to the language to help a lazy programmer reduce the number of keystrokes when typing code, such as the short array syntax which allows this code:
$array = array(1,2,3);
to be replaced with:
$array = [1,2,3];
This change was introduced simply because some lazy programmers said "Other languages do it this way, so PHP should too!" This is a pathetic argument as it makes the code less readable. As I already have a large well-established codebase that does it old fashioned way I do not see any advantage of switching to the new syntax, so I won't. I have been using the old way for 15 years now, and there is nothing wrong with it, so my brain has been trained to use it. I will therefore be sticking to what I am used to.
While some people think it is clever to condense several expressions into a single line of code. I do not for the simple reason that it makes the code less readable and therefore more difficult to maintain. There is actually a term for the act of replacing proper words with symbols, and that word is obfuscate which is described as To alter code while preserving its behavior but concealing its structure and intent
. How can such an act ever be described as best practice?
The vast majority of PHP developers work on nothing but front-end websites, and most of them use some sort of framework rather than writing everything from scratch. These frameworks are built by other front-end developers based on their experience in building their own front-end websites.
I do not work on public-facing web sites, I work on business-facing web-based administrative applications which can also be known as enterprise applications. Just because these applications are written to run over the internet does not mean that they have the same requirements as web sites, and as such they require a different type of framework. If you do not understand the differences between the two then please take a look at Web Site vs Web Application.
I have looked at several of the popular front-end frameworks and the first thing that strikes me is that none of them actually qualify for the name "framework" according to the wikipedia definition. They are actually nothing more than libraries as they do not offer the full range of facilities which one would expect to find in a proper framework, as discussed in What is a framework?. Any framework which uses a Front Controller gets an immediate black mark from me, as does any framework which requires more than five classes to construct a web page. Any framework which calls itself an MVC framework, but which does nothing but provide empty directories called 'model', 'view' and 'controller' gets another black mark. Any framework which does not provide facilities to generate Model classes from the database structure tells me that they haven't a clue about writing database applications. Any framework which seeks to use as many of these optional extras as possible I regard as an over-engineered monstrosity.
A "proper" framework should offer the following facilities:
It is also quite common for front-end developers to think that the world revolves around their website and that any back-end should be regarded as nothing more than an add-on to their work. They design and build the front-end first without any thought to the back-end. It was this attitude which prompted me to write An end-to-end eCommerce solution requires more than a fancy website and Why you should build your web application back-to-front.
I was designing and building database applications before the internet existed, and to avoid rewriting the same chunks of code in each application I designed and built my own frameworks, first in COBOL and then in UNIFACE. I switched to PHP in 2002, and the first thing I did was to rebuild this framework which I eventually released as open source in 2006. A lot of people dismiss my framework with the reason being that it is no good for building front-end websites, which shows their ignorance of the following:
SUMMARY: Front-end frameworks may be adequate for developing front-end websites, but they are sadly lacking when it comes to developing back-end administrative applications. It is like taking a tool for building flash sports cars and using it to build an articulated lorry.
Some developers will eventually realise that if they build a front-end website which accesses a database then they may actually require sets of screens to view and maintain these database tables in a separate application. I say "separate" as access to these screens should not be through the front-end website. The back-end application should have its own URL and should only be accessible to authorised people, such as members of staff. Here are some of the approaches I have found to create a back-end application (commonly known as a CRUD application) using some of the popular front-end frameworks:
You may notice that some of these solutions are not actually built into the framework but supplied as add-ons. They also require different levels of effort, sometimes with the use of command line tools instead of interactive screens, and having to create various components manually. The screens which are created are very basic and often limited to what I refer to as the List1, Add1, Enquire1, Update1 and Delete1 patterns, which means that it is often very difficult to create screens which are based on more sophisticated Transaction Patterns such as being able to create PDF output. Compare this with the equivalent procedure in RADICORE:
In case you didn't notice, these steps enable you to build and run basic components without having to write a single line of code! Note that all these steps are covered in the tutorial. Once the initial class file has been created you can modify it to include any custom code for business rules or task-specific behaviour. If the table structure changes you can simply rerun the import/export procedures to recreate the table structure file without overwriting the class file. You can also create more advanced tasks from some of the other Transaction Patterns when the need arises.
A back-end application will probably require facilities which are simply not required in a front-end website, such as:
While it is possible for a subsystem within the Radicore framework to be completely stand-alone, it is also possible to build a large application which is comprised of a set of integrated subsystems. In very large applications which contain a large number of subsystems, it may be possible to turn access off for any unwanted subsystems.
You should also be aware of the following points:
SUMMARY: A back-end application can be much more than a collection of simple CRUD screens, and a proper back-end framework should be able to help you generate simple CRUD screens as quickly as possible, with as many facilities as possible, but provide the ability to extend simple screens into complex user transactions.
Here is a summary of the main points in this article:
This tells me that anything other than those three important concepts are in fact unimportant if not totally irrelevant. All those optional extras were invented by persons of questionable intellect after the fact, and not including them in your code does not make your code "not OOP".
As a long time practitioner of some of those previous approaches I therefore expect OOP to be easier to learn and easier to develop and maintain, so when I see the advocation of principles and practices which do not support these aims I have the right to stand up and voice my opinion.
How a piece of software was written is irrelevant as far as the paying customer is concerned. Given the choice between two pieces of software which achieve the same thing, but one was written "properly" but uses twice as many lines of code, is twice the price and will take twice as long to deliver as the other, which do you think the organisation will choose?
When I see "solutions" which are not as simple as they could be I need to see proper justification for these unwarranted complications. If those complications are there for no other reason than to provide a solution to a problem which does not actually exist, then it shows that the analysis of the problem was faulty, so any solutions based on that faulty analysis must also be regarded as faulty.
Do enough work to get the job done and then stop. Enough is just right whereas more than enough is too much, excessive, a waste.
If I can achieve a result in 500 lines of code with a small number of objects, yet you choose to do it using double the number of lines and double the number of objects, what does this prove? That you are better programmer? I think not. That your understanding and use of design patterns is superior to mine? I think not. The proof of the pudding is in the eating, so it is results that count, not the method you used to achieve those results. By using 500 lines of code more than me you have added in 500 lines of useless, dead code. More lines of code is more lines to write, more lines to execute, and more lines to read. More lines to write means more time needed to write, and more time needed to test, and time costs money. More lines to execute will have an adverse effect on performance. More classes, each in its own file which needs to be loaded separately, will have an adverse effect on performance. More lines of code to read means more lines to understand, which will make it more difficult to maintain.
If you are a member of the let's-make-it-more-complicated-than-it-really-is-just-to-prove-how-clever-we-are brigade be aware that yours is not the only way, and it is far from being the best way, the most cost-effective way. As a long-time follower of the KISS principle I choose to walk down a different path, and as I am able to produce software which is far closer to fulfilling the promise of OOP than you are, then surely my understanding and implementation of OOP must be better than yours.
You may say that PHP is not a "proper" OO language, but I would say that you are one of those crowd of lemmings who do not know what OO is. According to Alan Kay and Bjarne Stroustrup the definition is quite simple, and all those optional extras are both unnecessary and irrelevant. Not only does PHP5 support the definition of OOP, so did PHP4 before it. I wrote my open source framework in PHP4 making use of encapsulation, inheritance and polymorphism to increase the amount of reusable code and decrease code maintenance, and I have been actively supporting and enhancing it since 2002. Even though it was originally written for PHP4 it still runs today in the latest version of PHP, and I have steadfastly resisted the urge to try out each new clever trick that has been added to the language since version 5 was released. Why? Because if I have code that works why should I spend time in rewriting it to use different code that works exactly the same? If it ain't broke don't fix it. The only changes I have made to my code have been changes that have been forced upon me, such as:
All the other new features I have ignored because I can achieve what I need to achieve without them.
I have used my framework to write a large multi-module ERP application called TRANSIX which has been used by commercial organisations in the UK since 2008. Again I have been actively supporting and enhancing this application to the present day, and the fact that I have been maintaining and enhancing my code for over a decade must prove that it is not such an unmaintainable mess as you may think. I have recently signed a licensing deal with a US software house who plan to sell my ERP application to large organisations all over the world, so that must prove that it is also good at what it does, good enough to compare favourably against rival software written by so-called "experts".
If I can write effective software using the bare minimum then why can't you? If I can write effective software without using any of the optional extras then why can't you? As far as I am concerned any programmer who is incapable of writing effective software using nothing more than the bare minimum of encapsulation, inheritance and polymorphism is just that - incapable. Not only incapable but also borderline incompetent, and, judging by the amount of crap that they can't stop producing, they are also incontinent.
The advantages of a minimalist approach are quite simple:
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles: