The common computer application comes in two parts: program code (typically object oriented) which allows users to view and maintain different sets of data, and a database (typically relational) which allows the data to persist between executions of that program code. Both of these components should have some sort of structure (if they don't then you are in BIG trouble), but although they dealing with exactly the same data, each of them is designed and constructed using totally different principles:
As a consequence of these two design techniques being totally different, the structures produced from them are also totally different, so much so that they are totally incompatible. This incompatibility is known as the Object-Relational impedance mismatch, and is why the the Object-Relational Mapper (ORM) was invented. An ORM is a component which sits between an in-memory object (the computer program being executed) and a relational database in order to convert the structure of one into the structure of the other in all communication between the two. However, building an ORM is not an easy process. Martin Fowler says the following in his article OrmHate:
The object/relational mapping problem is hard. Essentially what you are doing is synchronizing between two quite different representations of data, one in the relational database, and the other in-memory.
In solving the problem of the incompatible structures the introduction of an ORM produces problematic side effects of its own. Because it is an additional component it involves the following:
Extra effort to design, build and document.
Extra effort to maintain should the software or the database change.
Extra resources at runtime.
Eventually the effort in maintaining this particular "solution" can be just as large, if not larger, as the original problem it was meant to solve. This leads to a fundamental question:
If a solution has side effects which are just as significant as the problem it was meant to solve, then is it the right solution?
Is there a different solution which produces fewer side effects? How about an obvious one - if the difference between the two structures causes a problem, then why can't the two structures be made less different? This will remove the need for an ORM as well as any problems caused by using an ORM. This is not a new idea. Some will say that it has already been tried, and failed, therefore it should not be considered as a possible solution at all. Some say that the differences between relational theory and OOD are so great that it is impossible to combine them without sacrificing some of the fundamental features that OO provides, therefore there is no choice but to employ an ORM. Let us examine this in more detail.
As I mentioned earlier a computer application has two parts, software and a database, which both work with and manipulate exactly the same data. The only difference is that one does it in memory while the other does it to disk. However, the design of the software (Object Oriented Design) and the design of the database (Database Normalisation) follow different rules, and the result of applying these different rules is a different data structure. Why on earth should these two sets of rules produce different and incompatible structures when applied to exactly the same data? Surely this would indicate that one of these sets of rules is broken and in need of serious repair? Let us examine these rules in more detail.
A well-structured relational database is designed by applying a process called Database Normalisation, which starts with First Normal Form (1NF) and progresses all the way up to Sixth Normal Form (6NF). The principles of normalisation are simple, common sense ideas that are easy to apply. Each can be defined in a single sentence, with practical "before" and "after" examples showing how they can be applied. A design cannot be considered for the Nth Normal Form until it has first passed through the N-1 Normal Form. Although some of the higher levels of normalisation are optional (this is known as de-normalisation), even if a designer stops at 3NF he must have progressed through 1NF and 2NF to get to that point.
Object Oriented Design (OOD), combined with its physical implementation in Object Oriented Programming (OOP), does not have a clear and concise set of rules or processes. There is no "step 1" to "step 6". All it has is a basic set of "features" which must exist in a language in order to support a method of programming using objects. These features can be defined as follows:
Writing programs which are oriented around objects. Such programs can take advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
Note that the effectiveness of your implementation can be measured by the amount of reusable code that you produce. The more reusable code you have at your disposal then the less code you need to write to get the job done, the less time it will take and the more productive you will be.
An instance of a class. A class must be instantiated into an object before it can be used in the software. More than one instance of the same class can be in existence at any one time.
The act of placing data and the operations that perform on that data in the same class. The class then becomes the 'capsule' or container for the data and operations. This binds together the data and the functions that manipulate the data.
The reuse of base classes (superclasses) to form derived classes (subclasses). Methods and properties defined in the superclass are automatically shared by any subclass. A subclass may override any of the methods in the superclass, or may introduce new methods of its own.
Same interface, different implementation. The ability to substitute one class for another. By the word "interface" I do not mean object interface but method signature. This means that different classes may contain the same method signature, but the result which is returned by calling that method on a different object will be different as the code behind that method (the implementation) is different in each object.
There are other "features" such as multiple inheritance, visibility (private/protected/public), interfaces, exceptions, et cetera, but these are all later add-ons and therefore not fundamental to OO.
The major problem with these features is that there is no simple progression from "not object oriented" to "object oriented" as there is from "not normalised" to "normalised". Some of these features are in fact optional and not mandatory - it is possible to write a class which does not have inheritance, or which does not share any methods with other classes (polymorphism). It is even possible to split an entity's data and/or operations across more than one class, thus breaking encapsulation. The bare minimum then is to have a class from which you can instantiate one or more objects.
Because there is no simple and verifiable step-by-step progression from "not object oriented" to "object oriented", just a set of features (some of which are optional), it is left up to the individual to decide how to implement these features. Unfortunately this leads to the situation where 100 different programmers, when given the same problem, will produce 100 different implementations. There is no single, universally-accepted opinion on what OOP is and what it is not, or what constitutes "good OOP" or "bad OOP". Because there is so much interpretation involved, this inevitably leads to a great deal of mis-interpretation. As an example, before you can design a class you are supposed to go through a process called "abstraction", but what does abstraction actually mean? Unfortunately the dictionary provides two different definitions:
A statement summarizing the important points of a text. To reduce to the essential details. Summary, synopsis, précis, résumé, outline, abridgement, condensation, digest.
Thought of or stated without reference to a specific instance. An ideal or theoretical way of regarding things. Separated from matter, practice, or particular examples; not concrete; insufficiently factual; unreal; hypothetical; abstruse; difficult to understand; incomprehensible.
The result of one is a summary of essential points, the result of the other is unreal and difficult to understand. If the result of this abstraction process is wrong, it surely follows that every step taken from that point is a step in the wrong direction, even more so when every step taken does not have to follow an easily-verifiable formula.
The failure of some (most?) OO programmers to understand what the term "abstraction" really means causes them to reach conclusions and make decisions which are, IMHO, fundamentally wrong, such as:
Abstract concepts are classes, their instances are objects. Classes are supposed to represent abstract concepts. The concept of a table is abstract. A given SQL table is not, it's an object in the world. Having a separate *class* for each table is therefore bad OO.
I have to disagree. This is a prime example of someone totally misunderstanding the terms "abstract", "concept" and "real". When I see the terms "the concept of an SQL table" and "a given SQL table" I read them as follows:
the concept of an (unspecified) SQL table - what can be done with any SQL table, regardless of its name and its structure. There are four main operations - SELECT, INSERT, UPDATE and DELETE - each of which is performed by constructing and executing an SQL query which has a predefined format with possible arguments. While the format of every possible query is known in advance, nothing can be executed without providing the details of a "real" database table.
a given (specified) SQL table - by specifying a particular table name along with its particular structure it then becomes possible to perform an actual SQL query in order to produce real results. A working SQL query cannot be constructed and executed until the table name and the column names are provided.
An SQL table is not an object, it is merely the blueprint for a type of object, and is therefore a class. It is not until you create a record in that table that you have an actual instance of that blueprint. Thus a table definition is a class while a table row is an instance of that class. The terms "concept" and "real" can be implemented as follows:
An abstract class can be constructed to include the concepts that can be applied to any unspecified SQL table. Such a class cannot be instantiated into an object as an SQL query can be constructed and executed without the details of an actual SQL table.
A concrete class can be defined in a subclass by inheriting from the abstract superclass and adding the missing details, which in this case would be the table name, its structure, and any relationships with other tables.
While the abstract class may be quite large as it needs to contain code for every possible SQL query, each concrete subclass is very small as it only identifies the barest of details for a single specific database table. When instantiated into a object this combines all the possibilities of the superclass with the actualities of the subclass.
It would appear, then, that having a separate class for each table is not so bad after all. In fact, if you examine my critic's statement you will see that it is his interpretation of that statement which is questionable:
The concept of a table is abstract.
This is why I have an abstract table class which identifies every operation which can be performed on any (as yet unspecified) database table.
A given SQL table is not, it's an object in the world.
This is why I have a concrete table class for each database table, which inherits from the abstract table class. Objects are instantiated from a concrete class, not an abstract class. It really is that simple, and definitely not as complicated as some OO proponents would lead you to believe.
While there are undeniable differences between relational and OO theory, too many of today's OO programmers spend far too much time in exaggerating those differences and complaining that they are totally incompatible. I am sure that they only do this in a feeble attempt to justify their perceived need for an ORM to act as an intermediary between the two. If you actually examine these so-called differences in greater detail you will see that it is actually possible to diminish their scale - in other words, to make mole hills out of mountains. Take a look at the list of "differences":
Databases do not have classes. While they do not use the word "class", if you look at this definition you will see that a class is nothing more than a blueprint that defines objects of a certain kind. If you examine the DDL (Data Definition Language) which describes a database table, is it not fair to say that the DDL is a blueprint for all records (objects) which may exist in that table?
"But what about the methods?" I hear you say. Each table definition does not need to define the methods that can be performed on that table for the simple reason that the same basic methods - create, read, update and delete - are universal across all tables. You may point out that a class can have many more methods than these, but I would point out that ANY method, regardless of its complexity, is nothing more than a variation of one of these four.
Databases do not have instances. If the DDL of a database table can be considered to be the same as a "class", then surely a physical record within that table can be considered to be the same as an instance of that DDL? That's not a difficult concept, is it?
Databases do not have encapsulation. If you look at this definition and disregard the fact that no methods are defined for each table as the four methods - create, read, update and delete - are universal across all tables, then a database table is no different from a class. You can put all the data for the same entity into a single table - customer data goes into the CUSTOMER table while product data goes into the PRODUCT table - just as you can put in into a single class, or you can split that data across multiple tables just as you can split it across multiple classes. What you can do in one you can do in the other, so what's the big difference?
Databases do not have inheritance. If you look at this definition you will see that inheritance is merely a technique for sharing the methods and properties of a superclass with a subclass. So how do you share data in a database? Instead of the word "extends" use "foreign key" instead and it all becomes clear. All the shared data is placed in a table of its own, known as a "foreign table", and is referenced through a pointer known as a "foreign key" (i.e. the key to an entry on the foreign table). This makes it easy to connect the two tables together at runtime by using a relational join.
In a lot of tutorials on OO I see examples of class hierarchies created just because something IS-A type of something else. For example, "dog" is a class, but because "alsatian", "beagle" and "collie" are regarded as types of "dog" they are automatically represented as subclasses. This results in a structure similar to that shown in Figure 1:
With this approach you cannot introduce a new type (breed or variety) of dog without creating a new subclass which uses the "extends" keyword to inherit from the superclass.
This is not how it is handled in a database. The DOG entity would have its own table, and in my software each table, because it has its own business rules, would have its own class. Each table can handle multiple rows, so its class should do so as well. In a database the idea of being able to split the contents of the DOG table into different types, breeds or varieties would not involve separate tables, it would simply require an extra column called DOG-TYPE which would be just one of the attributes or properties that would be recorded for each dog. If there is no need for a separate table for each DOG-TYPE I can see no reason to have a separate subclass for each DOG-TYPE.
If there were additional attributes to go with each DOG-TYPE then I would create a separate DOG-TYPE table to record these attributes, and make the DOG-TYPE column of the DOG table a foreign key which points to the DOG-TYPE column of the DOG-TYPE table, which would be its primary key. This would produce the structure shown in Figure 2:
With this design all the attributes of a particular type/breed of dog are stored on the DOG-TYPE table, so instead of a separate subclass for each DOG_TYPE I would have a separate row on the DOG-TYPE table. When reading from the DOG table you can include a JOIN in the SQL query so that the result combines the data from both tables. This is how you can "inherit" attributes in a database. The introduction of a new type of dog requires no more effort than adding a record to the DOG-TYPE table. There are no changes required to the software, no new classes, no new screens, no new database tables, no nothing. From a programmer's point of view this simple 2-table structure is far easier to deal with than an unknown number of subclasses.
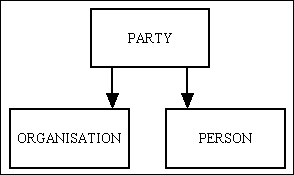
There may be cases where the number of different "types" is fixed, but the difference between them are quite significant and therefore require different table structures, in which case I would use a structure similar to what is shown in Figure 3:
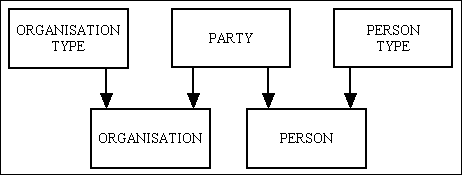
Here a PARTY can either be an ORGANISATION or a PERSON. The PARTY table holds the data which is common to both, while the other tables hold the data which is specific to that type. Now, if both ORGANISATION and PERSON can be broken down into different types I would use the structure shown in Figure 4:
Databases do not have polymorphism. If you look at this definition you will see that polymorphism is nothing more than the ability for several classes to share the same methods. When you consider the fact that methods are not defined for each table in a database for the simple reason that the same set of methods - INSERT (create), SELECT (read), UPDATE and DELETE - is common across all tables, it is plain to see that all tables automatically share exactly the same methods. Does this fit the definition of polymorphism or what?
Databases are not object oriented. So what? Something does not have to be OO in itself for it to be accessible from an OO program. The HTML and XML languages are not object oriented, but does that prevent an OO program from generating HTML or XML documents? The SQL language is not object oriented, but does that prevent an OO program from generating SQL queries? I think not. The real complaint is that it is not possible to take an in-memory object and simply dump it to a relational database in its current structure without any additional effort. There is all that messy SQL to deal with, all those SQL queries to generate. SQL is not object oriented, so many OO programmers haven't a clue how it works. SQL requires knowledge of the database structure, and efficient database structures are designed using a theory which again is not objected oriented, so many OO programmers haven't a clue how it works. What these poor demented souls dream of is the introduction of an OODBMS which follows their thinking more closely. Unfortunately for them the OODBMS has a long, long way to go before it replaces the solid, well proven RDBMS. This topic is discussed in more detail in OO Design is incompatible with Database Design.
Many OO programmers just haven't a clue about relational databases and the universal SQL language, so they do not see the benefit of making their object structure as close as possible to the database structure. Instead they have this nasty habit of designing structures which are so obtuse, so off the wall, so far removed from the more sensible, normalised structure of the database, that it is virtually impossible to make the two communicate with each other without the intervention of a translation mechanism or ORM. To them their class structure comes first, and the database structure is left till last as a mere "implementation detail", an afterthought. In my humble opinion a good database design is the foundation for a good application, and anyone with more than two brain cells to rub together will tell you that you always start any construction with a solid foundation. Anything else is a disaster waiting to happen.
It appears that I am not alone in this opinion. The following book title was found on www.oreillymaker.com:
I have tried using Hibernate for several projects. Every time, using Hibernate has been ok until at some point I start using many-to-many relationships, or want control over the order of things to be loaded. I start fiddling with the annotations, lazy loading, try HQL, and start getting pissed off. Then I look at what sql queries are being sent to the database, and it hits me every time:
As soon as a project gets to a certain size Hibernate's magic ends up getting in the way.
I most often know how I want the database to be, and I know SQL enough to get the results I want. If I want to tune queries or write queries, then SQL is the bloody language for it. Not HQL or any other ORM bastardized substitute. What is wrong with using the query language created for this purpose?
Instead of exaggerating the differences between the two design methodologies and making the use of an ORM virtually mandatory, my personal approach is to minimise the differences, or preferably eliminate them altogether, and try to get them to work with each other as closely as possible, thus making the use of an ORM totally redundant. I achieve this with one very simple technique - every table in the database has its own class. One table, one class, no exceptions. The data structure in the software matches the data structure in the database down to using the same names and the same data types. My critics (of whom there are many) are quick to come up with arguments such as:
To use a relational model in memory basically means programming in terms of relations, right the way through your application. [...] Some problems are well suited for this approach, so if you can do this, you should.
Give or take 1-2 implementation details, an RDBMS's table and an OO language's class is the same thing: A specification of a set of grouped attributes, each with their associated type.
In all of my experience with writing database applications before switching to an OO language it was standard practice to define a data structure in your code that was an exact match to the table structure in the database. Not only was it standard practice, it was impossible to do otherwise. Because the software structure and the table structure were identical and interchangeable there was never any mismatch and consequently never any need for an ORM.
The only time that anything like an ORM was needed was if you took a piece of software which was built for a particular data structure and tried to connect it to a database table with a different structure. In this case you had to go through an intermediate piece of software which would accept input from one structure but produce output for another structure. It is obvious to me that the existence of a mismatch is the result of a deliberate act on the part of the developer, with the only legitimate excuse being when you have a single piece of software which you want to link to different databases with different structures.
This approach is not proper OO. Seeing that Nobody Agrees On What OO Is this is just a personal opinion and not an absolute fact. In my opinion Object Oriented Programming involves nothing more than:
Writing programs which are oriented around objects. Such programs can take advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
I have tried this approach, but it did not work. You may have tried, but did you try hard enough? Your implementation may have failed, but was it because your implementation was faulty? Each problem can have more than one solution, and each solution can have as many different implementations as there are grains of sand in the desert. Unfortunately a lot of the sample implementations I have seen have been clouded by people's insistence on following a set of arbitrary rules which actually hinder an efficient solution. I am results-oriented instead of rules-oriented, so if an artificial rule gets in the way of my solution I simply ignore it. That annoys the person who created that rule, but my customers pay me to deliver solutions, not to follow rules that don't work.
Speaking as a programmer who has built several systems which involve OO software communicating with a relational database I can state quite categorically that it can be done for the simple reason that I have done it. Perhaps my approach is more successful because I had over 20 years of experience in software development before moving into object oriented programming, and this experience made it easier for me to get to grips with how best to implement the OO paradigm. Contrast this with a lot of todays newbie programmers who have zero experience and are taught utter rubbish by clueless dunderheads who have the nerve to call themselves "experts". Instead of being allowed to experiment with various approaches to find out which one works best they are told "there is only one way", and so they follow like sheep and are never allowed to learn anything better. Those people only know what they have been taught, whereas I know what I have learned through experience. Believe me, there is a BIG difference between the two.
Unlike so many others I was not a clueless newbie when I jumped into the quagmire of object oriented programming. I had decades of experience behind me, and I used this experience to separate the wheat from the chaff. I started off my programming career using COBOL, that well known procedural language, using indexed files, hierarchical and network databases, and then some 16 years later I moved to UNIFACE, a model-driven and event-driven language using relational databases. During all this time I learnt the following valuable lessons:
Start with a properly designed (i.e. normalised) database. I have worked with a few badly structured databases, so I know from personal experience what a disaster they are.
Follow up with a software design that works with, not against, the structure of the database. Not only should the software have structure (I have seen my share of unstructured COBOL code, thank you very much) but that structure should actually mirror the structure of the database (as taught at a Jackson Structured Programming course I attended in 1979). I do not waste my time re-examining the data using "is-a" and "has-a" relationships in order to build a complex class hierarchy as every database table, without exception, automatically has its own class.
The majority of this experience was with software houses where the job involved designing and building an application for one customer before moving on to another application for a different customer. This was a high pressure environment which involved bidding against other software houses for the contract, and then having to complete that project to budget and within timescales. No room there, then, for wooly-headed theories which did not cut the mustard.
In 2002 I decided to teach myself PHP so that I could move into web development, and because it had OO capabilities I decided to learn about OOP as well. From reading various books and online tutorials I discovered that the basic principles of OOP are encapsulation, inheritance and polymorphism, so I tried to combine my decades of previous experience with these new principles in order to write software. My starting point was to rewrite a development framework which I had originally designed and written in COBOL (using a single tier architecture) in 1985, then rewrote in UNIFACE in the 1990s, firstly using a 2-tier architecture then again using a 3-tier architecture when that capability was introduced into the language. My original COBOL framework was successful in reducing developer effort as it removed a lot of boring, repetitive coding and provided a lot of features "out of the box". My first 2-tier rewrite in UNIFACE was better, and my 3-tier rewrite better still, so I wanted to see if PHP+OOP could continue this trend. I'm happy to say that I was not disappointed. I went through the following sequence of events:
The UNIFACE language had a feature called component templates which made it easy to generate new components from a pre-defined template or pattern. It worked on the premise that each component can be categorised by structure, behaviour and content, with the template built around a particular structure (screen layout) and behaviour (code). A functioning component could be created by combining a template with a particular entity (database table). As I had found this feature a great aid to rapid application development I wanted something similar in my PHP framework, but as it did not exist I had to invent it. I devised a catalog of transaction patterns where the structure is provided by an XSL stylesheet, and the behaviour is provided by a page controller. By combining a pattern with a database table class (the content) the result is a functioning transaction.
I created a database table, then wrote a family of forms to view and maintain the contents of that table. I wrote a separate controller script for each of the LIST, SEARCH, INSERT, UPDATE, DELETE and ENQUIRE components, but made them all communicate with the same table class.
I constructed a class file for this table, and filled it with the code to satisfy the requirements of all the members of that forms family. I then copied this file and made it do exactly the same thing for another database table. It was then a straightforward exercise to compare these two files to see where the same code was duplicated, and to move this common code to a superclass from where it could be shared via the mechanism of inheritance. Because I was able to move a vast amount of common code into the superclass I found that each table subclass turned out to be quite small - it contained barely more than the table name and its database structure.
Originally the superclass contained all the logic to access the database, but I eventually split this off into a separate Data Access Object. The original DAO was for dealing with MySQL, but I have since written additional classes for PostgreSQL, Oracle and SQL Server. It is possible to switch from one DBMS to another simply by changing a single configuration parameter. Unlike other implementations I have a single DAO for the entire application and not a separate DAO for each individual table.
Because there are only four basic operations which can be performed on a database table - SELECT, INSERT, UPDATE and DELETE - I created a corresponding method for each operation:
SELECT = getData($where) - the $where string is optional, and is in the form of the WHERE clause of an SQL SELECT statement. The result is an array of zero or more rows, and each row is an associative array of name=value pairs.
INSERT = insertRecord($array) - the input array is the POST array from the HTTP request. This is converted into an SQL INSERT statement which is then executed.
UPDATE = updateRecord($array) - similar to INSERT, but uses the identity of the primary key to construct the WHERE clause.
DELETE = deleteRecord($array) - similar to UPDATE.
Later on I added other methods such as insertMultiple(), updateMultiple() and deleteMultiple() which could deal with any number of records at a time instead of being limited to just one.
Notice that because I know that I will be accessing a relational database, and nothing but a relational database, using SQL statements that I am embracing that fact and deliberately modelling my class methods around those SQL operations. I am not going out of my way to hide the fact that there is an SQL database in the background, which makes it a lot easier when I want to communicate with that database.
I decided to have a single getData($where) method for retrieving records from the database as this is infinitely flexible and can deal with any set of circumstances. Other implementations seem to favour a separate method for each combination of selection criteria, but this sounds like a lot of effort with absolutely no benefit.
Even though each class deals with a specific database table, and each table has a list of columns, I decided NOT to have a separate class variable for each column. Why? The input from an HTTP request is an associative array, and it made more sense to me to pass the whole array to the business object as a single unit instead of unpicking it and using a setter method to pass in one column at a time. It is just as easy to access a column within an array as it is a class variable, so there are no disadvantages to this approach.
Having a single class variable to hold all table data in an array instead of a separate variable for each column means that the array can contain any number of columns, and it is easy to add in extra columns at runtime, either by obtaining them from other tables with an SQL JOIN or by generating them with a calculation. This array may also be multi-level, in which case it can contain any number of rows. Other people seem to think that an object can only deal with one database record at a time, which then requires extra code to deal with multiple records, but my approach is simpler and more flexible.
When a page controller retrieves data from a database object for transfer to the View component the single array for all the object's data is extracted and passed to a standard routine which converts it into an XML document without having any column names hard-coded anywhere. This means that I do not have to waste time with using getter methods for each individual column.
The contents of the XML document is transformed into an HTML document by means of an XSL stylesheet. Originally each database table required its own set of XSL stylesheets as each of them was customised to identify which field was positioned where, and with what HTML control. Eventually the need for XSL customisation was removed as these details can be extracted from the XML document after having been specified in a screen structure file. This means that a small set of pre-written XSL stylesheets can be used to produce a large number of different screens.
One big advantage of using XML and XSL to create HTML output is that the order in which data is added to the XML document has absolutely no effect on the order in which that same data is extracted and turned into HTML. This means that I can change the order in which the data is processed in an XSL stylesheet without having to change the order in which that data is written to the XML document in my program code.
When each page controller activates a method on a database object this sets in motion a sequence of invariant and variable methods which go all the way to the database and back again. This sequence contains a selection of variable methods which are defined in the superclass, but which are empty. These empty methods can be copied to a subclass where they can be filled with custom code, and this custom code will be executed at runtime. This mechanism, which is an implementation of the Template Method Pattern, allows the developer to interrupt the processing flow with custom code at any stage, as shown in this series of UML diagrams.
None of my page controllers requires any knowledge of which methods are used to access which database objects for the simple reason that every database object uses exactly the same generic methods. This fits the description of polymorphism. This is totally unlike the approach I have seen advocated where each method name includes the entity name. For example, with entities called CUSTOMER and PRODUCT the method names would be getCustomer(), getProduct(), insertCustomer(), insertProduct(), etc. This method would require each controller to be tied to a specific object as the method names it used would only work on that particular object. My approach means that a controller can be used on any object as the method names are identical.
None of my page controllers contains any hard-coded class names as these are passed down in a variable from a component script. The controller simply uses the variable to load the class file and instantiate an object, then call methods on that object. Because my controllers do not contain any hard-coded class names or method names they are infinitely reusable.
Each database table class requires some knowledge of the structure of its associated database table in order to function properly. The structure details were built up in stages:
A list of column names for the table is required so that any names in the input array from the insertRecord() method which do not belong in that table, such as the SUBMIT button in the POST array for example, can be filtered out before constructing the query string which performs the INSERT.
A list of column names which comprise the primary key is required so that the correct WHERE clause of an UPDATE or DELETE query can be constructed.
A list of column names which comprise any candidate keys is required so that their uniqueness can be verified if they are changed during any UPDATE operations.
As well as the name of each database column, its properties (type, size, etc) are also required so that user input can be validated and cleansed before it is used in any database query. The verification that date fields contain dates, numeric fields contain numbers, and required fields are not empty can then be built into the framework as a standard module and does not have to be manually coded within any database class.
A list of all child relationships (where this table is the parent) is required so that any delete constraints (Restricted, Cascade or Nullify) can be correctly verified and applied when any record is deleted. This logic can be built into the framework as a standard module so does not have to be manually coded within any database class.
A list of all parent relationships (where this table is the child) is useful so that SELECT queries can be constructed with JOINS to parent tables. This logic can be built into the framework as a standard module so does not have to be manually coded within any database class.
Each database table class thus knows what data is held within that table's structure, and, with the combination of standard methods which are inherited from the abstract table class plus the use of custom methods to handle any business rules associated with that table, also contains all the operations which can be performed on that data. This fits the definition of encapsulation.
Originally each table's class file and associated structure details were built manually, but eventually I was able to automate this by building a Data Dictionary. This can import its data directly from the database, then, with the press of a button, export the details to the application in the form of two files - a class file and a separate structure file.
Originally all the component scripts and screen structure scripts for each transaction had to be built manually, but eventually I was able to automate this by adding a transaction generation function into the Data Dictionary. This works by choosing a database table, then a transaction pattern, and it will generate the relevant scripts at the press of a button. It also adds transaction details to the menu database so that, in most cases, the new transactions can be run immediately.
To summarise, in order to define the classes which an application needs I must first identify all the different entities and their properties, and the operations which can be performed on them. If I am developing a database application then the entities and their properties have already been defined in the database structure, where each entity has its own table and its own set of properties. Because they are database tables the only operations that can be performed on them are SELECT, INSERT, UPDATE and DELETE. It makes sense to me to use the database structure as my software structure instead of going through a separate process which produces a different set of entities, properties and methods. This has two distinct advantages:
I have one design process, not two, so it is less work.
It does not produce incompatible structures, therefore I do not have to deal with any incompatibilities.
It seems that this concept is too simple for some people.
The standard answer from OO purists would be to create a new class which contains elements from all the relevant tables, but this type of solution simply is not in my repertoire. My solution incorporates any one of the following options:
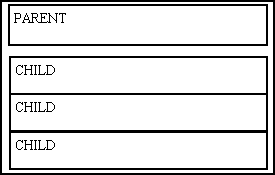
When dealing with a one-to-many or parent-child relationship it is quite common to have an output screen which has a separate zone for each of the two tables, such as one at the top which shows a single occurrence from the parent table, and another below it which shows multiple occurrences from the child table, as shown if Figure 6:
Figure 6 - parent and child data in different zones
There is no rule which says that a controller may only communicate with a single model (database object), so I have built my controllers to access a separate database object for each zone. In this example it will call the getData() method on the PARENT object using whatever selection criteria has been passed down to it. Only one record will be displayed, but if more than one is retrieved the screen will contain hyperlinks to scroll back and forth between them. The primary key will be extracted from the current PARENT record and used in the getData() method on the CHILD table. The number of CHILD records actually displayed on each page will be determined by the page size, which can be varied by the user. If more records are available than can fit on a single page then hyperlinks will be available to scroll back and forth between them.
This controller can be used for any two tables which exist in a parent-child relationship as the logic is exactly the same, only the table names are different.
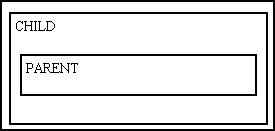
Another way of dealing with a parent-child relationship is to include data from the PARENT table inside the zone used by the CHILD table, such as when using a foreign key on the CHILD to obtain one or more fields from the PARENT, as shown in Figure 7:
The most efficient way of combining data from more than one table in the same result set is to use an SQL JOIN. It is a feature of my framework that it is possible to have the JOIN statements constructed automatically based on relationship information which is obtained from the Data Dictionary. There is no rule that says that the data which is extracted from a database object must be obtained from a column within that table, so it is possible to construct a data array that contains columns from any number of different sources. It is therefore possible to construct SQL queries which are as complicated as you like as the result set which is produced is extracted wholesale, converted into XML, then transformed using an XSL stylesheet. The XSL stylesheet does not care where the data came from, as the fact that it exists within the XML document is good enough.
If it is not possible to use an SQL query with JOINs to obtain the data from multiple sources in a single operation then, as a last resort, it can be performed one step at a time in the application. There are custom methods available all along the processing path which means that the contents of an object's data array can be inspected and modified very easily before the end result is exported to an XML document. This means that it is possible to instantiate an object from another database table, use this object to obtain more data, and merge that data with the current object's data. This is demonstrated in the following code snippet:
function _cm_getForeignData ($fieldarray)
// Retrieve data from foreign (parent) tables.
{
if (!empty($fieldarray['foreign_key'])) {
$dbobject = RDCsingleton::getInstance('foreign_table');
$data = $dbobject->getData("primary_key='{$fieldarray['foreign_key']}'");
if (count($data) > 0) {
$fieldarray = array_merge($fieldarray, $data[0]);
} // if
} // if
return $fieldarray;
} // _cm_getForeignData
If there are two tables involved in a parent-child relationship as shown in Figure 6 then the controller will already be using separate objects for the PARENT and CHILD tables. The POST array will contain data for both tables, but these are easily distinguishable as the data for PARENT will not be indexed by row number whereas the data for each CHILD occurrence will be indexed by its row number. It is therefore quite straightforward for the controller to pass the unindexed array to the PARENT object and the indexed array to the CHILD object.
If the array which is passed to an object contains data which must be written to a different table then the process is no more complicated than reading from a foreign table. Let us take the example where the whole POST array is passed to an object for "table1", but part of this data must be written to "table2":
The controller passes the entire POST array to the object for "table1" using code such as:
$dbobject = new "table1";
$array = $dbobject->insertRecord($_POST);
Although this array contains data for fields which do not exist in "table1" no action needs to be taken as the object will only validate what it is told to validate - everything else will be ignored. When the array is passed to the DAO for the construction of the SQL query only those fields which exist in the table definition exported from the Data Dictionary will be included in that query.
Provided that there are no errors when inserting data into "table1" the _cm_post_insertRecord() method will be called. By default this is empty, so nothing will happen, but in this example we now wish to perform some additional processing, so we need to insert some custom code such as:
function _cm_post_insertRecord ($rowdata)
// perform custom processing after database record has been inserted.
{
$dbobject = RDCsingleton::getInstance('table2');
$data = $dbobject->insertRecord($rowdata);
if ($dbobject->errors) {
$this->errors = array_merge($this->errors, $dbobject->errors);
} // if
return $rowdata;
} // _cm_post_insertRecord
Note again that even though the whole data array is passed to the object for "table2" no action needs to be taken as anything which does not belong in that table will be ignored.
It may not be rocket science, but it works, and thus adheres to the KISS principle.
In-memory data structures offer much more flexibility than relational models, so to program effectively most people want to use the more varied in-memory structures and thus are faced with mapping that back to relations for the database.
I totally disagree. I have been building database applications for decades. I have built frameworks for building database applications in three different languages, and each of these frameworks has specifically targeted the database structure and not some airy-fairy, arty-farty "real world" conceptual representation which is as divorced from reality as it is possible to get. My latest web application framework has the following characteristics:
It was designed using the 3 Tier Architecture, which means that there are totally separate components for each tier or layer:
Presentation layer = User Interface, displaying data to the user, accepting input from the user.
Business layer = Business Rules, handles data validation and task-specific behaviour.
Data Access layer = Database Communication, constructing SQL queries and executing them via the relevant API.
The Data Access layer is comprised of a single object - Data Access Object or DAO - which communicates with a particular DBMS. There is a separate class for each supported DBMS - currently MySQL, PostgreSQL, Oracle and SQL Server - so it is possible to switch from one DBMS to another by changing a single line of code.
The Business layer is comprised of a separate object for each business entity, which has a corresponding table in the database. Each database table class is initially created from the Data Dictionary, but can but amended to include custom logic for business rules. Each table class inherits a great deal of common code from an abstract table class, which includes all standard data validation and communication with the data access object.
The Presentation layer is comprised of a small number of reusable page controllers which communicate with all business objects via a standard set of generic methods. Once each business object has completed its task its data is extracted, converted into XML, then transformed into HTML by an XSL stylesheet. The XML document is produced by a standard component, and all the XSL stylesheets come supplied with the framework.
Because each page controller does nothing more than receive a request from the user and pass that request on to a business object, with the construction of all HTML output being handled in a separate component, this is also an implementation of the Model-View Controller design pattern.
The page controllers are reusable because each of them implements a particular transaction pattern on an unknown table class, where the identity of a particular table class is supplied at runtime via a separate component script. Building scripts for new components is as easy as saying "implement this pattern on that table" and pressing a button.
Keeping each database table class synchronised with the structure of its corresponding database table is all achieved through the Data Dictionary. The database structure is imported into the dictionary, customised as necessary, then exported to the application. The first time a table is exported both the class file and structure file are created. The class file may be customised as necessary, but the structure file should not be touched at all. If the structure of a table is changed then all that is necessary is to re-import that table into the dictionary to deal with any changes, then re-export to the application. In this case the class file will not be overwritten, so no customisations will be lost, but the structure file will be replaced to reflect the new structure.
Customise those details as required. This includes defining all relationships with other database tables, and adding information which can be used by the presentation layer.
Decide which transaction patterns are required, then go into the Data Dictionary, select a table, select a pattern, then press a button to have the code generated for you. Details are also added to the menu database, so it is also possible to run the generated script straight away.
Using this framework it is therefore possible to generate a web application to maintain the contents of a number of database tables without having to write any HTML or SQL. Indeed, the initial maintenance screens do not require the writing of any code at all. The only time that it is necessary to write any code is to customise the screen layout, or to modify a database table class to include any business rules or to override the default behaviour.
All this and not an ORM anywhere in sight, so don't tell me that it cannot be done.
")
")
")