The method of generating a web page from a UNIFACE application has traditionally been to use the WEBGEN and WEBGET statements from within a UNIFACE Server Page (USP).
WEBGEN - Generate an HTML skeleton document from a skeleton file (ending in .hts), replacing any field values (marked by <X-SUBST> and <X-OCCURRENCE> tags) with the current values in the form. The generated document is then passed to the Web server.WEBGET - Load data sent from a client browser into the current form, reconnect any database occurrences to the database, and activate a <Detail> or <On Error> trigger if required.This particular method has the following drawbacks:
I have personally witnessed how much time can be wasted in tracking down a bug in a web page caused by an HTML tag being somehow misplaced between the time it was inserted into the UNIFACE component and the time the actual web page was generated. Too many decisions appeared to have been made 'behind the scenes' about which the developer had no knowledge and over which the developer had no control.
A more modern approach would be to use a combination of XML and XSL in order to generate HTML documents. The advantages are as follows:
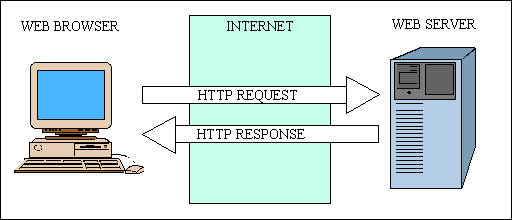
Here is a brief overview of how the internet works. A web browser running on a client device (such as a PC) communicates to a web server on a remote server device via the internet, or World Wide Web, using the Hyper Text Transfer Protocol (HTTP). The client sends a REQUEST, the server receives it, processes it, then sends back a RESPONSE.
Figure 1 - The Internet in a nutshell
The HTTP Request is sent from the client to the server. It consists of 3 parts:
http://www.stuff.com/product.php?id=123456With this method any data is visible in the URL, which means that the request can be bookmarked for retransmission at a later time.
The HTTP Response is sent from the server to the client. It consists of 3 parts:
As you can see from the HTTP response the language in which your web site is written is totally irrelevant as what is returned to the client is nothing more than a text file containing HTML tags and data. You can use any language, or combination of languages, that takes your fancy provided that the output is an HTML document.
Here is a sample HTML document:
<html>
<head>
<title>This is the document title</title>
<link rel="stylesheet" type="text/css" href="style.css">
</head>
<body>
<p>This is a paragraph...</p>
<table width="100%">
<tr>
<td>This is a table cell</td>
<td>This is another table cell</td>
</tr>
</table>
</body>
</html>
Within an HTML document there are a predefined set of tags which have predefined meanings which should be interpreted in a predefined way by whatever browser is running on the client. Be aware that some browsers may use additional 'extensions' to the HTML standard that may not be rendered correctly, if at all, in a different browser.
An HTML document contains tags, processing instructions and data, such as:
<html> and ends with </html>.<head> and </head> is part of the header.<title> and </title> will be used as the document title.<link rel="stylesheet"...> line points to an external Cascading Style Sheet (CSS) file that will be used for any formatting instructions.<body> and </body> forms the body of the document.<p> and </p> is treated as a paragraph.<table> and </table> is part of a table.<tr> and </tr> is a row within the current table.<td> and </td> is a cell or column within the current row.There are numerous other tags with other meanings, but if you want to know more I suggest you visit w3schools.com for a brief tutorial.
With this method an XML file contains nothing but data, while an XSL file contains processing instructions to transform that file into another document. This could be another XML file, an HTML document, a Microsoft WORD document, an Adobe PDF document, or any type of text-based document that you choose.
Here is a sample XML document:
<?xml version='1.0' ?> <!-- Created by UNIFACE - (C) Compuware Corporation --> <UNIFACE release="7.2.06.2(u-s602r1l)" xmlengine="1.0"> <TABLE xmlns:USOURCE="USOURCE.DICT"> <OCC> <USOURCE:UTIMESTAMP>1999-06-19T19:02:53</USOURCE:UTIMESTAMP> <USOURCE:USUB>M</USOURCE:USUB> <USOURCE:UVAR>USYS</USOURCE:UVAR> <USOURCE:ULABEL>M_90001</USOURCE:ULABEL> <USOURCE:ULAN>USA</USOURCE:ULAN> <USOURCE:MSGTYPE>M</USOURCE:MSGTYPE> <USOURCE:UDESCR>STORE</USOURCE:UDESCR> <USOURCE:UCONFIRM>F</USOURCE:UCONFIRM> <USOURCE:UAUDIO>0</USOURCE:UAUDIO> <USOURCE:UTEXT>90001: STORE failed - see Message Frame for more details</USOURCE:UTEXT> </OCC> <OCC> <USOURCE:UTIMESTAMP>1999-06-19T19:07:31</USOURCE:UTIMESTAMP> <USOURCE:USUB>M</USOURCE:USUB> <USOURCE:UVAR>USYS</USOURCE:UVAR> <USOURCE:ULABEL>M_90002</USOURCE:ULABEL> <USOURCE:ULAN>USA</USOURCE:ULAN> <USOURCE:MSGTYPE>M</USOURCE:MSGTYPE> <USOURCE:UDESCR>STORE</USOURCE:UDESCR> <USOURCE:UCONFIRM>F</USOURCE:UCONFIRM> <USOURCE:UAUDIO>0</USOURCE:UAUDIO> <USOURCE:UTEXT>90002: STORE successful</USOURCE:UTEXT> </OCC> </TABLE> </UNIFACE>
The only entry that MUST be contained in an XML document is the <?xml version='1.0' ?> which identifies it as an XML document, with the XML version number. All the others are user-defined, but they must adhere to the following rules:
xmlns:namespace="unique identifier" instruction. The namespace is then prefixed to the relevant elements with a ':' separator. In the above example USOURCE: is used as a namespace.attributename="attributevalue".<UNIFACE>.UNIFACE/TABLE/OCC/USOURCE:TEXT is such a path.<OCC> appears multiple times, and each occurrence has its own set of child elements and values.If you want to know more about XML I suggest you visit w3schools.com for a brief tutorial.
Here is a sample XSL document:
<?xml version='1.0'?> (1) <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0" xmlns:USOURCE="USOURCE.DICT"> (2) <xsl:template match="/"> (3) <html> <head> <title>Contents of Message File</title> </head> <body> <table border="1"> <thead> <tr><th>Library</th><th>ID</th><th>Message</th></tr> </thead> <tfoot> <tr><th colspan="3">end of messages</th></tr> </tfoot> <xsl:apply-templates select="UNIFACE/TABLE/OCC[USOURCE:UVAR]"/> (4) </table> </body> </html> </xsl:template> (5) <xsl:template match="UNIFACE/TABLE/OCC[USOURCE:UVAR]"> (6) <tr> <td><xsl:value-of select="USOURCE:UVAR"/></td> (7) <td><xsl:value-of select="USOURCE:ULABEL"/></td> <td><xsl:value-of select="USOURCE:UTEXT"/></td> </tr> </xsl:template> (8) </xsl:stylesheet> (9)
Here is an explanation of its components. Note that those tags that are prefixed with xsl: are XSL instructions; the remainder you should recognise as standard HTML tags.
xsl: namespace. Additional xmlns: statements are optional depending on the contents of the documents being processed.match="/". As there is only one root node the contents of this template are executed only once. This will start creating the HTML output where the body will contain a table with a predefined header and footer, with the contents being obtained by the instruction at line (4).UNIFACE/TABLE/OCC which has a child element named USOURCE:UVAR.match=".." part.USOURCE:UVAR, USOURCE:ULABEL and USOURCE:UTEXT elements respectively.If you want to know more about XSL and XSL Transformations I suggest you visit w3schools.com for a brief tutorial.
There are actually two ways in which an XML document can be transformed by an XSL document:
When a transformation takes place the same XSL file will perform different actions depending on what data is available. This can come from 3 sources:
<author>Tony Marston</author>Elements are referenced using code such as:
//author
<author age="21" hair="dark brown">Attributes are referenced using code such as:
//author[@age]
<xsl:param name="title">This is the title</xsl:param>Parameters are referenced using code such as:
$title.
If a parameter value is not included in the transformation process then the value defined in the <xsl:param ...> statement will be used as the default.
There is one important factor to note about this method of producing web pages - you do not have to wait until the programs that generate the XML data have actually been written before you can develop and test your XSL scripts. XML files are text files, therefore files with sample data can easily be constructed using any text editor. The only proviso is that your software generates XML files with the same structure and naming conventions as your test samples.
This is how the XML/XSL transformation process can be incorporated into a UNIFACE Server Page (USP) component:
Figure 2 - XSL Transformation within UNIFACE
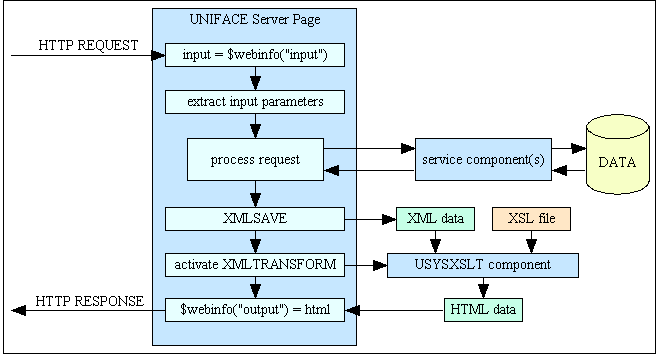
The processing flow is as follows:
$webinfo("input") command. Note that I do not use the webget command as this automatically reconnects occurrences to the database. You should be using the 3-Tier architecture for your web application, in which case no Presentation Layer component (such as a Server Page) should communicate directly with the database. This should be done indirectly through a service component in the Business Layer.$webinfo string and inserted into the component. As this is returned in the form of an associative list this should be a straightforward task.XMLSAVE command. This builds the XML stream (a single text string) using the structure defined in a DTD (Document Type Definition). This may also use optional mapping parameters to resolve any differences between entity and field names between the component and the DTD. Note that at present UNIFACE does not support the inclusion of user-defined attributes with values that are supplied at runtime. Such attributes will have to be inserted by editing the XMLSAVE output string.$webinfo("output") command will then pass the HTML document to the client's browser.Optional 'cookie' data can be retrieved using the $webinfo("cookiesin") command and set by the $webinfo("cookiesout") command.
I hope that in this article I have clearly demonstrated two things:
I am aware that the sample XML and XSL documents used in this article may not convince you that this method is actually capable of producing sophisticated dynamic web pages that are essential in a typical web site, so I have written a follow-up article showing what I have been able to produce in my own tests using PHP and MySQL running under the Apache web server. This article is available at 'Generating dynamic web pages using XSL and XML'.
Tony Marston
8th January 2003
mailto:tony@tonymarston.net
mailto:TonyMarston@hotmail.com
http://www.tonymarston.net
| 1st Feb 2003 | Amemded summary to inlude link to follow-up article 'Generating dynamic web pages using XSL and XML'. |