It never ceases to amaze me when, even in this day and age, I come across IT departments that still insist on designing components that are large and complex. They seem to think that it satisfies a user requirement, but does it? I discovered in the early 1980s that there was a better alternative, and all the experience I have had since then has done nothing but reinforce this view.
Consider the following business requirements:
The following functions are required for object 'A' (e.g. maintain customers or invoices)
Enter selection criteria.
List all occurrences that meet those criteria.
Create a new occurrence.
Display more details for a selected occurrence.
Update the details of a selected occurrence.
Delete the details for a selected occurrence.
Where does it say that all these functions MUST be provided in a single component? It does not. Users may expect to see all that functionality in a single component, but only because that is what they have been used to in the past, or because it is the only option proposed by inexperienced designers. Neither party may be aware that there is an alternative which is actually easier to implement and just as easy, if not easier, to use.
By 'easier to implement' I am taking into consideration the whole lifetime of an application, which includes:
The original construction.
Subsequent ongoing maintenance.
Upgrades to incorporate more modern technology or techniques.
The definition of efficiency is the ability to achieve a particular result with the minimum of effort. It is more efficient to:-
Achieve an objective with 10 lines of code instead of 100.
Achieve an objective with 1 hour of effort instead of 10.
Use an existing library routine instead of writing a new version.
Create a component from a template instead of building one from scratch.
I should point out that the quest for efficiency should NOT mean sacrificing quality for speed. If you implement a quick and dirty fix now instead of doing a proper job you will often find that the 'quick and dirty' fix requires a clean-up period which makes its total time greater than that of the 'proper job'. And believe it or not, the longer that you delay the clean-up process the longer it will take.
It has been my experience that the 'small & simple' approach to application design is more efficient overall than the 'large & complex' approach. If budgets and timescales are an issue for a particular project then the person who chooses the slower and more expensive method should be prepared to justify that choice and accept the consequences of that choice.
Several times in the past I have been forced to build software to the 'large & complex' method only to be told at a later date that what the user REALLY wanted was something that was less complex, less cumbersome, less costly and less late. These are the REAL requirements, so anything that interferes with their implementation should be treated as a mere whim and not a genuine need. Anything that increases the complexity and cost of a system without a corresponding increase in functionality or usability can be regarded as 'cosmetic bloat' and should be seriously questioned and preferably ignored altogether.
The following sections outline my experiences of the 'large & complex' and the 'small & simple' design methods and hopefully help to identify which is the more efficient of the two.
The reason why some people assume that a group of functions should be supplied in a single component is largely historic.
It is assumed that the complexity (and therefore cost) of a system is directly proportional to the number of components, so they try and pack as much functionality as possible into a small number of components.
In the days before Microsoft Windows, client/server and non-modal forms, only one program could be run at a time - it would always fill the whole of the visible screen area, and it would be a slow and cumbersome process to switch to another program. For these reasons it was common to say 'If I have the whole screen area at my disposal then I may as well use it' and 'If I cannot switch to a different program to perform this other function then I must add that functionality to the existing program'.
The 'large & complex' approach leads to problems in the following areas:
Program specifications
Writing program specifications can be quite interesting when a single document has to contain all the requirements and business rules for all those different functions. It is quite common to end up with a document that is littered with 'If mode = ADD then…' and 'If mode = UPDATE then…' and 'If mode = DELETE then…' If this is repeated for each field on the screen then just image how large that document could be. Take into consideration that some rules may only apply to a single mode while others may apply to two or more modes and the complexity increases. Then add the fact that there may be some fields on the screen that should only be accessible under certain conditions and the complexity increases yet again.
Program development
If producing a complex specification is difficult wait until you try to write a program from such a specification. When performing the validation for a field or occurrence you must be able to identify what the current mode is so that you can correctly implement all those 'If mode = X' rules. It can be quite tricky to ensure that individual rules are executed when they ARE needed, and not executed when they are NOT needed.
If you think that I am exaggerating then how would you answer the following question so that you would be able to write the code to execute the correct rule?
When entering data into a field is the user
Entering selection criteria for a new search?
Entering data for a new occurrence?
Entering changes for an existing occurrence?
It becomes apparent to the more experienced developer that a component’s propensity for bugs is directly proportional to the number of lines of code it contains plus the number of different conditions that have to be catered for. I have lost count of the times I have worked on a large complex component trying to track down an obscure bug that simply would not exist if the component had been broken down into smaller units to begin with.
Program maintenance
Creating the initial version of the program might be fun, but just wait until you try to make an amendment. The change may sound simple, but the developer has to put the right code in the right place. Not only has he to ensure that the new code is executed when it is supposed to and not executed when it is not supposed to, but he also has to ensure that he does not introduce a bug in any of the other functions.
Program testing
The more complexity that is contained within a single component then the more difficult it is to test that component. Every possible set of circumstances has to be tested for and the expected result verified. If there are three conditions that can be either TRUE or FALSE then there are eight possible combinations to test for. Add just one more condition to the list and this doubles the number of combinations. When testing a program after a small change has been made it is not sufficient just to test that the change works, it is also necessary to check that none of the other functionality has been accidentally broken. This means repeating ALL the tests for the component, so the more complex the component the more complex the testing.
Security requirements
It is usually after the component has been written that the user decides to reveal his security requirements. Even though a component may contain the ability to perform several functions it may be necessary to prevent certain users from performing some of those functions. This is usually implemented in the following way:
Maintain some sort of security matrix that identifies WHO is allowed to do WHAT function.
Add code into the form that asks: 'What are you trying to do? Are you allowed to do it?'
There may be several ways of implementing this level of security, each requiring different amounts of code to implement or having different levels of acceptability to the user.
Do you let the user make changes then wait until he tries to store them before saying no?
Do you wait until the user leaves the first changed field before saying no?
Do you wait until the user starts to make the first change before saying no?
Can you make all the fields NOEDIT so that the user cannot change any fields?
An added level of complexity might be to extend these security requirements to the field level rather than just the function level. This can be expressed as:
This user can view this set of fields but not that set.
This user can modify this set of fields but not that set.
User Acceptance
Although some users actually ask for large, complex components in the first place, their attitude often changes when presented with the finished article. Among the complaints I have heard in my long career are:
The screen is 'too busy', meaning that there is too much data on display.
The screen is 'too complicated'; meaning that there are so many different functions available that it can be difficult to learn how to switch from one function to another.
The screen is 'too slow'. This is as a direct result of the amount of data that has to be retrieved from the database into the component’s structure before it can be initially displayed, or the volume of changes that are held within the component’s structure before they are applied to the database.
I made the transition from large & complex components to small & simple ones out of necessity, not because of a desire to follow a new fashion set by some industry guru. Many years ago I was trying to add yet more functionality to a COBOL program that had been around for several years and which had already been modified many times. Unfortunately on this occasion the amendment could not be implemented because the newly modified component would not compile or run. There was a finite limit on the amount of data and program code that could be built into a single component, and the amendment had caused this limit to be exceeded. The only possible solution was to take out the code for at least one function and put it in a separate component. While building the mechanism to switch control from the original large component to the new small one we decided it would be just as easy to put every function in a separate component. Thus instead of having one large component that performed five functions we ended up with five small components that performed a single function each.
After a while all the developers involved came to the same conclusion – rather than being more difficult or more time consuming to produce a larger number of smaller components it was actually quicker and easier because each component was self-contained and with far less complexity. This brought into focus the meaning of the KISS principle – 'Keep It Simple, Stupid'.
Do not assume that such limitations do not exist in more modern languages such as UNIFACE. Just try building a form with 60+ entities and 1000+ lines of proc code and see how far you get.
Program specifications
As each program specification only contains the details for a single function then only the details for that particular function need be specified. Anything which does not pertain to that function is not relevant and should not be included, therefore all those 'if mode = X then…' statements simply do not appear.
Program development
If it is easier to produce a specification for a simple component then it is just as easy for a developer to produce the program. There are fewer lines of code to write, fewer conditions to test for, fewer places where the code can go wrong, therefore each component can be completed in a shorter amount of time. Each function can be released as soon as the code for that function has been completed – there is no need to wait for all the other functions to be coded before the component can be released.
As a component can only be worked on by a single developer at a time it is not possible for individual functions within that component to be worked on simultaneously by other developers. However, if the functions are contained within separate components then each component can be developed simultaneously, thus making it possible to speed up the development process by adding more manpower.
Program maintenance
You can now guarantee that making a change in one function will not accidentally introduce a bug in the processing of another function. Gone are the days when making a 'simple' change takes longer than expected due to the sudden appearance of peculiar bugs in peculiar places.
Program testing
After making a change to a component it is necessary to test the entire functionality of that component to ensure that what should have been changed has, and what should not have been changed has not. The simpler the component, the simpler the testing.
Security requirements
Dealing with basic security requirements such as 'User A can perform function A but not function B' is much simpler if each function is in a separate component. All security checking can be moved out of the component and into the menu system so that authorisation can be checked before calling the component instead of afterwards. In a system with dynamic rather than static menus it is even possible to remove unauthorised functions from the list of menu options before they are displayed so that the user only sees what he is authorised to use. In this way he never gets the chance to select a function only to be informed that the selection is not valid. Again, because the security checking has been moved out of individual components and into a single place within the menu system there is less code within each component, therefore less code to go wrong.
More sophisticated security requirements such as 'User A can access component B to amend details, but cannot amend field C' can also be relatively simple to implement if you make use of the standard functionality that is available within UNIFACE. One method I have seen is to allow each field to be modified, then as soon as the user starts to modify any field this executes some code which examines the security matrix then, if permission has not been granted, rejects the change. A simpler method is to make use of the field_syntax command and change all relevant
fields from 'edit' to 'noedit' in one pass after retrieving the data. This achieves the same result, but removes the need for any additional code in any <start mod> trigger.
User Acceptance
Regardless of what they ask for, users actually prefer small, simple components. Because they are not filled with any irrelevant fields or processing they are fast to learn, fast to load, and fast to run.
There are some other advantages I have come across over the years:
An advantage of using separate components for separate functions is that each function can have a screen that is customised for that function. A typical example is where an object contains a start date and an end date. If the select function shares the same screen as the display function and the user wants to select on a range of dates then you are forcing him to enter that selection criteria in a most unfriendly manner. It would be more acceptable to have separate fields for the 'from' and 'to' dates so that the user would not have to enter two dates in a single field with the 'GOLD<' and 'GOLD>' profile characters. Similarly, if you wish to edit out all those records where the end date is less than or equal to today it would be more convenient for the user if the selection screen contained a simple check box with the label 'Exclude expired entries'.
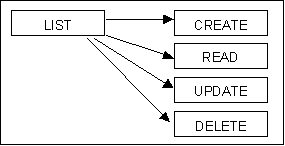
There is a feature of non-modal forms which is only available if they are small and simple. Instead of having the application window (screen) filled by a single form which performs several functions it is possible to have the screen split into several forms each of which performs its own individual function. If these forms communicate with each other in an intelligent manner they can provide the same overall effect as the multi-function component, but with some added extras. As an example take the following family of forms:
Figure 1 - a family of non-modal forms
In this example the LIST form is the parent which is activated first. From the parent it is possible to activate any of the child forms, CREATE, READ, UPDATE or DELETE. It is possible to have several of these forms visible in the same application window at the same time provided that each form is smaller than the total screen area. Only one of these forms can have focus at any one time, but it is possible to switch focus from one to another just by clicking the mouse within the boundaries of the desired form.
It is also possible for an event in one form to automatically trigger a change in another. For example, the user can activate the CREATE form, enter the details for a new occurrence and fire the <store> trigger. As well as adding the new occurrence to the database then clearing its screen ready for new input, details of the new occurrence can be sent to the parent LIST form so that it can update its current display. This gives the user visual confirmation that the new record has been added, which is especially useful if several new records are being created at the same time.
It is also possible to have multiple instances of the same form open at the same time, but showing different contents. This feature can be turned on when choosing an instance name whenever a component instance is created. It is possible to stick to a single instance name, usually the same as the component name, in which case only a single instance of that component will be allowed to exist at any one time. However, it is also possible to specify a different name for each instance so that multiple copies can exist at any one time. It is good practice to generate an instance name from the primary key of an occurrence to eliminate the possibility of creating several instances that attempt to lock and update the same occurrence.
Another example of communication between non-modal forms is where a selection is made in the LIST form, then the user clicks on an occurrence and activates the UPDATE form. Upon activation this automatically retrieves the selected occurrence and makes its details available for update. The user makes the desired changes then fires the <store> trigger. This updates the database and sends details of the changes back to the parent LIST form so that it can update its current display. Without terminating the UPDATE form the user switches focus back to the LIST form and selects a
different occurrence. The existing UPDATE form has its contents automatically refreshed to reflect the new selection, thus making its details immediately available for update. This is faster than in the days of modal forms when it was necessary to terminate the UPDATE form, make a new selection in the LIST form, then reactivate the UPDATE form.
This kind of communication can be built into any form that can logically be defined as a child to the LIST form. The code for this communication that allows the two forms to operate as a single unit is minimal and automatically inherited from the component template, thus reducing any development overhead. This allows for the LIST processing to be created once and then be shared by many components instead of having a private copy built into each of those components. This 'write once – reuse many times' concept is one of the principal features of the Object Oriented (OO) paradigm, and is a practice that every competent developer would do well to follow.
Having discovered the advantages of the 'small & simple' approach over the 'large & complex' alternative, this has been my preferred design method ever since. This served me well in my many years of COBOL development, and has served me just as well in the subsequent years of UNIFACE development. In fact, I have found it easier than my contemporaries to convert from one version of UNIFACE to the next simply because my components are small and simple.
When building applications in UNIFACE 6 I made maximum use of standard form skeletons. These were sample forms that could be copied to create new forms, but which required an amount of cutting, pasting and renaming before the new form contained the correct entities and fields. When upgrading to UNIFACE 7 I found it extremely easy to convert these form skeletons into component templates, then to rebuild each component from the new template. In this way I was able to quickly convert an entire application into pure UNIFACE 7 and make use of the capabilities of non-modal forms. By using the inheritance feature of component templates I was able to apply global changes very easily when new features, functions or statements became available.
Having experimented with the 3-tier architecture in UNIFACE I have begun to create a new set of component templates which will enable me to rapidly construct entire applications based on this architecture. It will also be a relatively straightforward process for me to convert any application based on my 2-tier templates into the new 3-tier alternative.
The 'small & simple' approach is also the preferred method when developing an application for the web. Those who try to convert large & complex components into a web pages quickly run into problems. Those who have applications with small & simple components have far fewer problems.
It is the purpose of the IT department to turn user requirements into usable software as quickly and efficiently as possible. If the 'small & simple' approach is easier to implement, easier to maintain and easier to upgrade, then how can anyone possibly justify using a less efficient methodology which comes with a higher cost but without a corresponding increase in benefits? Which method gives better value for money? Which method provides the result that the user REALLY wants?