This all started because of an article which I published on my website called Using PHP Objects to access your Database Tables (Part 1) and Part 2 which describes how I have used the OO capabilities of PHP 4 to construct objects to handle the business rules and data handling for all entities/tables in my application database. My development environment allows me to quickly construct the individual transactions within each of my web applications, and by maximising the utilisation of reusable modules I am able to build new components very rapidly.
For the record I must state that I have never been trained as an OO programmer, nor have I used any language with OO capabilities until PHP. I have been a software engineer for over 25 years and have developed in a variety of 2nd, 3rd and 4th generation languages on a mixture of mainframes, mini- and micro-computers. I have worked with flat files, indexed files, hierarchical databases, network databases and relational databases. The user interfaces have included punched card, paper tape, teletype, character mode, block mode, CHUI, GUI and web. I have written code which has been procedural, model-driven, event-driven, component-based and object oriented. I have built software using the 1-tier, 2-tier and the 3-tier architectures. I have created development infrastructures in 3 different programming languages. My latest achievement is to create an environment for building administrative web applications using PHP that encompasses a mixture of 3 tier architecture, MVC, OOP, and where all HTML output is generated using XML and XSL transformations. You can get other details by following the links on my About Me page.
Before I start listing the complaints against my article let me explain how I designed and built the code which was the subject of that article. But even before that let me explain how I acquired my knowledge of OOP as I have already admitted that I have never received any training. I have bought several books on OO and browsed the web for suitable articles, but I found them extremely uninspiring.
One thing that really annoys me about articles and tutorials on OOP that I have found on the web and in books - they all talk about creating a class called 'shape' with various subclasses for 'square', 'circle', 'triangle' etc. This is of absolutely no use when I want to build a system to deal with real-world objects such as 'customer', 'product' and 'sales' which have corresponding database tables. This has often led me to believe that OOP is therefore unsuitable for building common-or-garden business systems as it appears to have been designed for nothing but graphical applications.
Bear in mind that unless you are developing software which directly manipulates a real-world object, such as process control, robotics, avionics or missile guidance systems, then some of the properties and methods which apply to that real-world object may be completely irrelevant in your software representation. If, for example, you are developing an enterprise application such as Sales Order Processing which deals with such entities as Products, Customers and Orders, you are only manipulating the information about those entities and not the actual entities themselves. In pre-computer days this information was held on paper documents, but nowadays it is held in a database in the form of tables, columns and relationships. An object in the real world may have many properties and methods, but in the software representation it may only need a small subset. For example, an organisation may sell many different products with each having different properties, but all that the software may require to maintain is an identity, a description and a price. A real person may have operations such as stand, sit, walk, run, eat, sleep and defecate, but these operations would never be duplicated in an enterprise application. Regardless of the operations that can be performed on a real-world object, with a database table the only operations that can be performed are Create, Read, Update and Delete (CRUD). Following the process called data normalisation the information for an entity may need to be split across several tables, each with its own columns, constraints and relationships, and in these circumstances I personally think that it would be wiser to create a separate class for each table instead of having a single class for a collection of tables.
This caused me to ignore all the verbosity in those books and articles and concentrate on the principles of OOP which I obtained from the chapter on Object-Oriented Programming Concepts from the Java Tutorial which is available on the Sun Microsystems website. As Sun Microsystems are the authors of the Java language, the most popular Object Oriented language in the world (according to TIOBE Programming Community Index), I think that what they have to say on the matter is worthy of some consideration.
Each real-world entity is modelled with its own class containing properties (variables or data) and methods (functions or operations which act upon, or change the 'state' of, those properties).
A 'class' is not an 'object', it is the blueprint, pattern or prototype that defines how an object will look and behave when it is created or instantiated from that class. Software must create an object (an instance of a class) before it can access any of its methods (functions) or manipulate any of its properties (data).
'Encapsulation' means that the class must define all the properties and methods which are common to all objects of that class. All those properties and methods must exist inside a single container or 'capsule', and must not be distributed across multiple locations.
Reference: encapsulation The localization of knowledge within a module. Because objects encapsulate data and implementation, the user of an object can view the object as a black box that provides services. Instance variables and methods can be added, deleted, or changed, but as long as the services provided by the object remain the same, code that uses the object can continue to use it without being rewritten.
'Implementation Hiding' means that the outside world may know about the properties and methods that exist within a class, but it does not know how each method is actually implemented. This allows the implementation to be changed at any time without the outside world being affected or even knowing that the implementation has changed. Note that this is often confused with 'information hiding', but that is a totally different concept altogether.
'Inheritance' is where the properties and methods of one class (the 'superclass') are shared by another class (the 'subclass'). The subclass may choose to override any properties or methods defined in the superclass with its own specific variations, or it may choose to add extra properties and methods of its own (i.e. 'extend' the superclass). Inheritance is the mechanism whereby common code is shared between one class and another.
An 'abstract method' is one which is defined in the superclass (such as an abstract class) as nothing but an empty placeholder for code that will be provided later. The actual implementation is defined within a subclass. Different subclasses may have different implementations of the same abstract method. Whenever a subclass inherits from an abstract class it must define any abstract methods in order to provide the implementation for each abstract method.
Note that if a class contains at least one abstract method then the entire class must be declared as abstract. It is not allowed to have an abstract method in a non-abstract class.
A 'non-abstract (concrete) method' is one which contains a default implementation which may be overridden in a subclass. If it is not overridden then the default implementation will be executed at run-time. If it is overridden then the implementation in the subclass will be executed instead of the implementation in the superclass. Note that the superclass may be an abstract class.
'Abstraction' is the process of separating the abstract from the concrete, the general from the specific, by examining a group of objects looking for both similarities and differences. The similarities can be shared by all members of that group while the differences are unique to individual members. The result of this process should then be an abstract superclass containing the shared characteristics and a separate concrete subclass to contain the differences for each unique instance.
An 'abstract class' is one which cannot be instantiated into an object as it may contain one or more abstract methods which do not have any implementation details. These missing details must be supplied via a subclass so that the combination of the two, the superclass and the subclass, is then capable of being instantiated into an object. The subclass provides the missing implementation details by overriding methods and/or properties defined within the superclass. Different subclasses may therefore provide different implementation details.
Reference: abstract class, A class that contains one or more abstract or non-abstract methods, and can never be instantiated. Abstract classes are defined so that other classes can extend them and make them concrete by implementing the abstract methods.
Note that an abstract class may contain a mixture of abstract and non-abstract methods, or even nothing but non-abstract methods. Non-abstract methods may define a default implementation which is inherited as-is without having to be duplicated within the subclass, but which may be overridden in any subclass. If a class contains at least one abstract method then the class itself must be declared as abstract.
'Polymorphism' is where different classes may have methods with the same signature as other classes, but where the response obtained from those methods is determined by the object itself. In other words: same interface, different implementation; or the ability to substitute one class for another.
Note that this does NOT require the use of the keywords "interface" and "implements" as these are totally optional in PHP. All that is required is that different classes implement the same method name with the same signature.
In my previous language I successfully implemented the 3 tier architecture which meant that the application code was split into 3 tiers or layers:-
Presentation logic = User Interface, displaying data to the user, accepting input from the user.
Business logic = Data Validation and the processing of all business rules.
Data Access Logic = Database Communication, accessing tables and indices, packing and unpacking data.
The purpose of the 3 tier architecture is to delegate tasks to particular layers so that any one layer can be changed without having any effect on the others. In this way it should be possible to switch from one database to another just by making a change to the data access layer, or to switch from one user interface to another just by making a change to the presentation layer. All the complicated code, the processing of the business rules, is maintained within the business layer which should be able to withstand any change in the other layers without missing a beat, thus preserving all the investment that went into its construction. It should even be possible to run two different user interfaces at the same time (such as client/server and web, or front-end website and back-end administrative application) which share the same components in the business layer.
In order to deal with such real-world entities as 'customer', 'product' and 'sales' each entity had its own component in the business layer. Each business layer component contained all the processing rules for an entity, and any component in the presentation layer which wanted to deal with an entity had to communicate with that entity's business component. Business components would access the physical database by communicating with a database driver in the data access layer. It seemed reasonable to me that all I had to do was transfer all the logic and functionality of my business layer 'component' into an 'object' and my first foray into the mystical world of OOP would be complete.
As I said earlier, I do not write software which interfaces directly with real-world objects, only with information about real-world objects, and this information exists in a relational database in the form of tables, columns and relationships. Instead of all the data that a real-world object may have, the application is only required to store the subset of data that it actually needs. Regardless of what operations may be performed on or by a real-world object, in a database application the only operations that can be performed are Create, Read, Update and Delete (CRUD). This is why my entire design is centered around database tables, and why each table has its own class.
One aspect of this previous language was that it utilised an Application Model (aka data dictionary), and each real-world entity had a corresponding entry in the application model, also known as an entity, which identified the data requirements and default program logic for the real-world entity. Each entity in the application model translated directly to a table in the database, so I am used to treating the term 'entity' as being any one of 'real-world entity', 'application model entity' and 'database entity'.
The principles of OOP do not include a data dictionary or application model, but they do recognise that you need somewhere to hold an object's variables when it no longer resides in memory. Using OO terminology this is known as a persistent data store. Each instance of an object can be translated into a corresponding instance (row or occurrence) in that object's persistent data store. It is obvious to me that a object must have knowledge of it persistent data store in order to communicate with it. It is also obvious to me that an object is useless without its persistent data store, and a persistent data store is just as useless without an object to maintain its contents. As an object and its persistent data store are therefore intertwined, interwoven, interchangeable, inseparable, indivisible and interdependent, when I talk about one I am automatically including the other. So when I talk about creating a class for a database table I do not mean just the database table on its own, I mean a class for the-entity-with-its-properties-and-methods-and-business-rules-and-its-persistent-data-store-which-is-known-as-a-database-table. As I don't like using such long words I have shortened it to 'class for a table' or 'table class'.
My biggest problem with 'proper' OO programmers is that they use Object Oriented Design (OOD) to design their classes, and they do this without any regard to the fact that there is a relational database in the background. They have little or no knowledge of database theory and SQL, so are unable to design a properly normalised database. They insist on designing their classes first and leave the database till last, shrugging it off as a mere 'implementation detail'. As a result the class structure often ends up by being out of step with the database structure, which results in a condition known as object-relational impedance mismatch. This does not bother these poor deluded souls as they think that employing an Object-Relational Mapper (ORM) will solve all their problems. This to me is not part of the solution, it is part of the problem. My approach is totally different - instead of deliberately ignoring the fact that my code will be using a relational database, I actually embrace that fact and design my classes around those database tables. I design my database structure first using data normalisation, I skip that useless step known as Object Oriented Design (OOD) and build my classes direct from my database structure, thus avoiding the need for that abomination known as an ORM. Some people call this 'heresy' whereas I call it 'effective'.
Having identified that I need a different object for each real-world entity and that each object will have its own table in the database I set about building my first OO class. In my previous language each service component in the business layer had two operations (methods) called getData and putData. The way that data was interchanged between the presentation and business layers was through XML streams, and the putData operation could handle a mixture of insert, update and delete at the same time as each occurrence (row) contained a status attribute which identified what action was necessary. Both the getData and putData operations could handle XML streams containing any number of occurrences in any number of entities in any structure.
PHP does not have the same powerful commands to handle XML streams, so I decided to stick with simple associative arrays. This was not actually such a retrograde step as PHP's array handling functions are very flexible and very powerful, and I found that anything I wanted to do could be done, and in a lot of cases with surprising ease. I decided to stick with my getData method which would be capable of receiving an array containing any number of rows, but as my putData method could not work I changed it to insertRecord, updateRecord and deleteRecord. I have subsequently added other methods to deal with other circumstances, such as working with multiple records, but these four were all I needed to begin with.
One feature I have observed in examples in books and on the web is that some OO programmers like to have method names which are tailored to the object. Thus for objects such as 'customer', 'product' and 'order' they would have a 'getCustomer', 'getProduct' and 'getOrder' method. I would never ever dream of doing such a thing simply because such a requirement does not exist when you access a table's data using SQL. You do not have a separate function name which is tied to a particular table, you have a generic query string which contains constructs such as the following:
SELECT ... FROM <table> WHERE ...
INSERT INTO <table> (<columns>) VALUES (<values>)
UPDATE <table> SET <column>=<value>, ... WHERE ...
DELETE FROM <table> WHERE ...
This means that regardless of what operation you wish to perform on which table, you construct a query string which you then send to the DBMS using the same <dbms>_query($connection, $query) function. It therefore makes sense, at least to me it does, to design the software around the idea of performing one of those four standard operations on one of the tables in your database, of which there may be dozens or even hundreds. OOP is supposed to enable you to write more code which is reusable as the more code you can reuse the less code you have to write, and this in turn enables you to become more productive. The code that is required to deal with each of the four standard operations is pretty much the same except for the table and column names, so it seemed obvious to me to put the common code into an abstract table class and to have the table and column names supplied at runtime from a concrete table class which deals with the business rules for a specific database table. By having the methods which execute thegetData(), insertRecord(), updateRecord() and deleteRecord() operations defined within the abstract table class this means that they are automatically available to every concrete table class and do not have to be duplicated. By having the same method names available in multiple objects I am therefore embracing the principle of polymorphism.
Another common OOP feature that I deliberately chose to ignore is having a separate 'getter' and 'setter' for each of my entity variables (column values). Why should I waste my time in feeding an object one item of data at a time when I can feed all data in a single associative array? Why should I waste my time in retrieving data from an object one item at a time when I can retrieve all data items in a single associative array? Not only does this enable my generic code to use common methods on any object, it also means that my generic code does not even have to concern itself with the names of any data items which are in the inbound/outbound array. Thus even the data structure being used by the object is irrelevant to my generic code. This I believe is acceptable in the world of OOP as it embraces the principle of implementation hiding.
I then set about writing a class that dealt with one of the database tables in my sample application, and tested it to make sure that it could read, insert, update and delete data correctly. I then created a duplicate of this class for another database table. I was then in a position to compare the two classes to see what code was similar and what code was different, the objective being to isolate the code that was similar and make it sharable in some way so that I could use it without having to duplicate it each time.
How do you share code in OO systems? Through inheritance. How does inheritance work? Through subclasses.
So I created an abstract superclass to hold the sharable methods and properties, and converted each existing class into a subclass so that it could share those methods and properties through inheritance. Then I began the painstaking process of moving code out of each subclass into the superclass, then testing to check that nothing had been broken. Remember that I was dealing with different classes with entirely different database tables, different data structures and different business rules, so I needed one set of code that could deal with any set of circumstances.
I used a similar technique when building the scripts in the presentation layer which communicate with my objects. I discovered that the only difference between one component and the another was the entity name and the XSL file name, so I split my scripts into two:
Unique component scripts which contain the bare minimum of information.
Sharable controller scripts which do standard 'stuff'.
Each of the four initial methods which I identified as common to each class needs to generate its own SQL/DML statement in order to communicate with the database. When I searched through various books and websites for examples of how other programmers dealt with the generation of sql statements all I saw was code in which the field names were hard-wired. I did not like this idea as it would mean having to write specific code within each class to deal the class variables, and specific code for each of the insert, update, select and delete operations. What I wanted was a generic mechanism whereby I could throw some data at it and it would generate the necessary sql statement for me. As one apparently did not exist I set about building one.
Those of you who are familiar with PHP will know that when the client presses the SUBMIT button in his browser all the data from the HTML form is made available to the receiving script in the form of the $_GET or $_POST array. This is an associative array of 'name=value' pairs. Bearing in mind that values for $this->tablename and $this->dbname have already been supplied in the class constructor, how easy would it be to turn the contents of the $_GET/$_POST array into a fully functioning sql statement? Answer: very, very easy.
This is when the first obstacle appeared. The $_POST array also contains an entry for the SUBMIT button, and if this is included in the sql INSERT statement you will hit a brick wall. So, I needed a generic mechanism in which items which did not belong in the table were automatically excluded from any sql statement. Notice that I still wanted a generic method - I did not want to create a list of names to be excluded as I had no idea at this stage as to the possible variations of non-database items that could appear in the $_POST array. I chose instead to have another class variable called $this->fieldlist to contain a list of all the column names that were valid for that particular table. That single decision proved to be the start of something which grew to be a very useful and powerful feature in my table class.
The second obstacle appeared when I wanted to perform an update. In order to identify the row that you wish to update it is necessary to supply values for the primary key fields in the WHERE clause, and as some of you may be aware each database table has its own primary key. A simple and generic solution came to mind very quickly - simply extend my $fieldlist array in the class constructor to indicate which field(s) in that table formed the primary key. This meant a small change from this:
This also helped with the construction of the DELETE statement where I also need the primary key details for the WHERE clause.
The next area where I wanted to use generic code instead of custom code was in data validation. Any experienced programmer will tell you that you cannot simply take what the user has entered and write it to the database 'as is'. It has to be cleansed (filtered, fumigated, sterilized, disinfected, sanitized, purified, decontaminated). At the very least you have to check that the data is of the correct type for the field so that numeric fields only contain numbers, date fields only contain dates, and so on. I have used several languages which have incorporated a data dictionary which has allowed this primary validation to be handled automatically.
In case you do not know what a data dictionary is (also known as an application model), let me offer a brief explanation. It is a facility built into the language which allows the layout of each database table and the specifications of each field within the table to be described. Some languages allow you to import table definitions from the database schema into the dictionary, others do the reverse by allowing you to export table definitions in the form of CREATE TABLE scripts. Thus you can either build you application model from an existing database schema, or you can create your database schema from your application model.
Because the data dictionary describes the type and size of each field this allows the language to perform primary validation before control is ever passed to any program code that the developer may have written. Fields marked as required will generate an error if they are empty. It is also usual for data dictionaries to identify primary keys, candidate keys, indices, relationships and sometimes even delete constraints. Some also allow a field's display format to be defined, some allow a field's label or heading to be defined. Most also allow descriptive comments to be stored for each field and table in order to provide a central repository for documentation.
I have subsequently added a data dictionary into my own development environment which allows me to import the structure of a database table, then export those details to my PHP application in the form of a table class and a table structure file. Not only does this allow me to generate the basic class for each database table at the touch of a button but also it allows me to generate the transactions to maintain the contents of each table at the touch of another button using my own library of Transaction Patterns.
It should be fairly obvious that PHP does not come with a data dictionary, or anything closely resembling a data dictionary. Those of you with sharp minds may have noticed that my $fieldlist array could easily be extended to provide most of the information that can be found in a data dictionary, which is exactly what I did. By adding more detailed specifications for each field I turned a simple field list into a comprehensive array of field specifications, which is why I renamed it $fieldspec in Part 2 of my article. It was now a fairly straightforward step to write a routine which took the contents of my $fieldspec array and use it to perform primary validation against the contents of the $_POST array.
The $fieldspec array does not contain application data but information about that data. As such it can be referred to as meta-data.
This is also an example of declarative programming (opposite to imperative programming) as it involves the definition or creation of a set of rules or conditions, but leaves the execution or implementation of those rules to another process or module. Thus a rule may be defined in many places but executed in only one. This avoids the duplication of code required to implement the rule, and allows the same rule to be executed in a consistent manner across the whole application. It also means that should the implementation of a rule need to be changed or enhanced then the code need only be changed in a single place.
Primary validation is good enough to check that each field contains valid data, but what if it is necessary to implement a business rule to check the contents of one field against another? For example, primary validation will ensure that fields start_date and end_date both contain valid dates, but to check that end_date is not earlier than start_date you need an additional layer of validation which I call secondary validation. I sometimes refer to primary validation as generic to denote the fact that it can be used by any and all tables whereas secondary (or custom) validation is specific to a single table. Where and how is this secondary validation specified? Rather than waste time trying to hold these rules outside the class and having to invent some mechanism to feed them into the object at runtime I decided to create a non-abstract method in the processing cycle into which any and all such custom validation could be inserted. In case you do not know how to implement a non-abstract method then take a look at the internals of my getData method which contains calls to additional internal methods called pre_getData and post_getData. Both of these methods are defined in the abstract class, but they are empty. It is therefore possible for each subclass to contain its own implementation of these methods. This is an example of using the Template Method Pattern and its hook methods.
Here, for example, is the code I would have to validate my two dates:
function _cm_commonValidation ($fieldarray)
// perform validation that is common to INSERT and UPDATE.
{
if ($fieldarray['start_date'] > $fieldarray['end_date']) {
$this->errors['start_date'] = 'Start Date cannot be later than End Date';
$this->errors['end_date'] = 'End Date cannot be earlier than Start Date';
} // if
return $fieldarray;
} // _cm_commonValidation
This is an example of imperative programming (opposite to declarative programming) as it provides the actual instructions which are to be executed.
As I had managed to find a way to duplicate most of the functionality of a data dictionary within my code I wondered what I would have to do to fit in the remainder. As my test application included a table with a candidate key I thought I would tackle this problem next. For those of you unfamiliar with database theory every table must have one unique key in the form of a primary key, but it may also have any number of other unique keys which are known as candidate keys. There may be several candidates for the position of primary key, but only one can be chosen. Just as with the primary key these candidate keys may consist of more than one field, so I needed a mechanism to represent such a structure. My solution was to create a $unique_keys array, and the code I built to process it is documented at Changing Candidate Keys.
If a table is the ONE in a ONE-to-MANY relationship (sometimes known as a PARENT-CHILD relationship) there may be some rules to apply before a row can be deleted. For instance, you might want to prevent a parent row from being deleted if any child rows still exist, or you may want to allow the deletion but process the child rows in some way, perhaps by deleting them or by replacing the foreign key with nulls. This is another area that I wanted to automate in some way rather than have to hard-code it each time. Thus I create a $relationship array to hold the necessary rules, with the code to process this array being documented at Deleting Rows.
The end result of all this work gave me a class hierarchy with two levels:
An abstract superclass containing generic code to deal with any table of any structure in any database.
A subclass for each individual database table containing the specific details of that table.
The subclass inherits all the code from the superclass while at the same time providing the missing details which allow an object to be instantiated. These missing details are:
The database name.
The table name.
The table structure.
The identity of the primary and any additional unique keys.
Any delete constraints.
All business rules.
You should notice that my superclass matches perfectly the description given for an abstract class, and as such it is perfectly legitimate, nay obligatory, that it can only be instantiated into an object via a subclass. Accordingly I have a separate subclass for each entity/database table which contains the implementation details for that particular entity/table. When I instantiate a subclass into an object the end result is a merging of the generic code from the superclass and the specific code from the subclass.
You may be worried that my database table class has code which generates SQL queries, but I have subsequently split that out into a separate Data Access Object (DAO) which is capable of dealing with any SQL query for any database table.
When retrieving data from the database it is possible to retrieve more rows than can be comfortably displayed within a single screen, therefore it is customary to split the database result into more manageable chunks or 'pages'. The display starts at page 1, and the user is given options on his screen, usually as hyperlinks, to jump to other pages that are currently available. This is called 'pagination'. In order for this to work successfully you need the following variables somewhere in your code:
$rows_per_page - the maximum number of database rows to be displayed on each page.
$pageno - the page number required by the user. This is combined with $rows_per_page to calculate the values for LIMIT and OFFSET in the sql SELECT statement.
$lastpage - the total number of pages available from the current query. This is so the user can be informed 'you are currently on page X of Y'.
My software is written using the 3 tier architecture, which means that I have totally separate components dealing with the presentation, business and data access layers.
The presentation layer (user interface) receives the HTTP request and outputs the response.
The business layer is made up of separate objects which contain all the business rules for individual entities/tables.
The data access layer handles all communication with the database.
There is no direct communication between the presentation and data access layers. The presentation layer passes the request to the business layer which in turn passes it (with possible modifications) to the data access layer. The data access layer gives its result to the business layer which in turn passes it (with possible modifications) on to the presentation layer. Clean and simple.
In order for the pagination as described above to work you have to consider the following:
The request for a particular $pageno comes in via the user interface.
The value for $rows_per_page may also be supplied by the user interface, or a default value may be determined by the business layer.
It is not up to the business layer to calculate the value for OFFSET as it does nothing with the results of that calculation. In some circles it is not considered 'good practice' to perform a calculation until you actually need the result. That is why I delay performing that calculation until I am in the data access layer. Once the calculation has been performed I pass the result back to the other layers so that they do not have to repeat the calculation which, again, would not be 'good practice'.
The Data Access Object (DAO) requires the values in $pageno and $rows_per_page so that it can calculate the correct values for LIMIT and OFFSET, These are then combined with the current SELECT, FROM and ORDER BY values into the SQL query string which is then sent to the database for processing.
Note that the value for OFFSET can only be calculated within the DAO because other users may have deleted records which causes the requested page to be unavailable. The value for $lastpage is determined, and if $pageno is greater than this value then it has to be adjusted downwards. This means that the value for OFFSET will be lower than if it were calculated using the original value for $pageno. If you issue an SQL query with an OFFSET which is greater than NUMROWS the result set will be empty, so you must ensure that OFFSET is still within bounds.
Note also that some databases do not support LIMIT and/or OFFSET, therefore the DAO for that database may have to perform some other processing to achieve the desired result. As it is only the DAO which knows what processing is to be performed (there is a different DAO for each database engine, remember) it must be left up to the DAO to carry out whatever calculations it requires to support that processing. Performing any calculations within the business layer would therefore not only be premature, they may even be redundant as different DAOs may require different calculations.
The response returned to the business layer will therefore contain the rows belonging to the requested page plus a value for $lastpage. This value is then passed back untouched to the presentation layer.
You should notice here that the request for a particular page comes from the presentation layer but can only be processed by the data access layer, therefore it must pass through the business layer to get there. Similarly the value for $lastpage is generated by the data access layer, but has to pass through the business layer before it can be presented to the user by the presentation layer. This is the most efficient way I have found to achieve the desired result. It seems to me that some of these so-called OO experts are unfamiliar with the concept of "efficient programming", and this is the main reason consistently I reject their "advice".
These are the arguments and criticisms I received about my article. It was initially focussed on one small area but quickly spread to cover my whole approach to OOP.
1. These are formatting things and do not belong in the class
I received this comment from someone who is supposed to be a senior and well-respected member of the PHP community (he used to be the technical editor for Zend Technologies but is no longer in that position for some reason) which stated that my class broke the rules of OO programming and would therefore be rejected by serious OO programmers. This is what he wrote about my section on class variables, specifically the variables $rows_per_page, $pageno and $lastpage.
How are these three possibly related to the DATA inside the table? They're just formatting things and therefore should not belong in the data itself. That's the whole point of OO. They have nothing to do with your object 'Database_Table'. They do not belong in the class, and are quite inflexible. The whole idea is encapsulation and inheritance. It's all about delegating responsibilities to the specific objects. If you want to write about OO Data Objects then that should definitely be in.
My response came in several parts:
These variables are not for data formatting, they are for data selection. They do not determine how the data is presented to the user, they help determine which rows will be selected from the database and passed back to the presentation layer for display to the user.
For pagination to take place there must be something in the presentation layer which allows the user to select values for $pageno and $rows_per_page, and something in the data access layer which uses these values in the LIMIT and OFFSET parts of the sql SELECT statement. The presentation layer does not communicate directly with the data access layer - it can only communicate with the business layer, and it is only the business layer which can communicate with the data access layer. This means that these values have to pass through the business layer, which in turn means that they must be defined in the business layer.
There is no logic in the Business layer which processes these variables, they are simply passed down to and processed within the Data Access layer.
To say that the use of these variables is "quite inflexible" is entirely bogus. Their purpose is to aid in pagination, and they allow the user to jump to any available page - first, last, or anywhere in the middle - in the current set of pages. How is this inflexible?
OO is about encapsulation, inheritance and polymorphism. It has absolutely nothing to do with delegating different responsibilities to different objects, it only requires that I have a separate object for each entity. The splitting of responsibilities is the subject of design patterns such as the 3 Tier Architecture or Model-View-Controller, and is thus an entirely different subject altogether.
There is nothing in any OOP literature I have read that says what I am doing is wrong, therefore how can it be wrong?
The language allows me to do it, therefore it cannot be wrong.
It works, therefore it cannot be wrong.
My solution is simple, therefore it adheres to the KISS principle and cannot be wrong.
Despite me asking him what he considered to be the *right* way of achieving my objective he failed to respond, probably because he didn't have an answer. It was at this point I decided to ask the wider PHP community for their views and initiated the thread in the PHP newsgroup.
I believe that his argument shows a fundamental flaw in the thinking of too many of today's programmers - they do not understand the difference between logic and data:
logic is fixed in program code as a series of instructions, with different sets of instructions grouped together in a series of functions or class methods. Each function/method performs a distinct operation on whatever data is made available to it at run time.
data is transient as it may have different values at different moments in time. While the program code might refer to different pieces of data with particular data names, these data names simply refer to places in memory which contain current data. This data may be loaded into memory from an external source, such as a database, which can contain an infinite number of different values for the same data name.
Logic is a series of instructions, and data is not an instruction. Just because a piece of data is used by or generated within a function does not mean that it is part of that function's logic. It may be processed by that logic, but that does not make it part of that logic. The same data name (variable) might be passed through any number of different functions in its lifetime but it does not "belong" to just one of them.
Having identified that "data" and "logic" are separate things, the next step is to differentiate between presentation logic and data access logic:
formatting/presentation/display logic is that program code which generates the HTML output and sends it to the client's browser.
data access logic is that program code which generates the SQL query and sends it to the database server.
My implementation is built around the 3 Tier Architecture, which means that all my presentation logic is confined to a component which exists within the presentation layer, and all data access logic is confined to a different component which exists within the data access layer. This means that:
All presentation logic (the generation of HTML documents) exists within, and only within, the presentation layer.
All data access logic (the generation of SQL queries) exists within, and only within, the data access layer.
All application logic (the processing of business rules) exists within, and only within, the business layer.
Various pieces of data may move freely between any or all of those layers, but that data does not become part of the logic of any layer. Logic is code while data is information. Data is not logic.
As my data access component does not generate any HTML and send it to the client device it is totally wrong for anyone to say that my data access component contains presentation logic. It may generate data which is eventually used in the presentation layer, but that is not the same thing. Data is not logic.
Have you heard about Content Management Systems (CMS) for which there are many different frameworks? These allow users to define sections of text which are stored in the database and then added into web pages. These pieces of text may contain strings which can be recognised as HTML markup, but does this mean that these strings are now part of the presentation layer and should not pass through the data access layer to the database? HTML markup is nothing but data, and it is only when these pieces are assembled and transformed into a final HTML document and sent to the client device that you have presentation logic, and this logic exists only within the presentation layer. Until that transformation takes place these pieces of HTML markup are nothing but data. Data is not logic.
You have put *pagination* information into the DB-class, and that is what I react to. You could insert two variables, $offset and $numRows, and that would be ok. But the pagination belongs in the presentation layer.
For your information the two variables I use are called $rows_per_page and $pageno, so telling me to use different names is utterly pointless.
Pagination cannot be handled in the presentation layer alone - part of it MUST be in the presentation layer, but part of it can ONLY be done in the data access layer:
The presentation layer is limited to the interface with the user which in this case is 'get me page X of the current result set' with the option to 'set page size to Z rows' if the current (or default) value for 'Z' needs to be changed.
The value for 'X' is passed down through the business layer as $pageno, while the value for 'Z' is passed down as $rows_per_page,
Before constructing the full query the data access layer must obtain the number of rows which currently satisfy the query. This count is used in a calculation with $rows_per_page to produce the total number of pages currently available ($lastpage). If $pageno becomes greater than $lastpage due to records being deleted it must be reset to $lastpage otherwise the full query will fail.
The data access layer then calculates the values for LIMIT and OFFSET to use in the sql SELECT statement which it then executes.
As well as the required page of data the data access layer also returns the value for $lastpage and the count of rows ($numrows).
It is quite clear to me that it is physically impossible to handle every part of the pagination process within the presentation layer as part of it can only be done within the data access layer. I hope it is now clear to you.
As an application will contain multiple presentation layer components but only a single data access component, then surely it would not be considered 'best practice' to have that code duplicated in multiple places when it could just as easily be defined within a single place? Or do you have a different definition of 'best practice'?
Let me put it another way:
When $pageno and $rows_per_page are used in my Data Access Object to construct the values for LIMIT and OFFSET in the SQL query then they are accessed by data access logic.
When $pageno, $rows_per_page and $last_page are used in my presentation object (XSL stylesheet) to construct the HTML output then they are accessed by display logic.
There is nothing in my DAO which outputs any HTML, so to say that my DAO contains presentation/display logic would be clearly erroneous. Similarly there is nothing in my presentation object which outputs any SQL, so to say that my presentation object contains data access logic would be just as erroneous.
If you are implying that a piece of information that originates in one layer cannot appear in another layer then you are seriously wrong. A user request comes from the presentation layer but the result comes from an entirely different layer. When the user requests a particular page of details from the database it is up to the data access layer to determine which actual rows are within the desired page, and in order to do this it needs to turn $pageno and $rows_per_page into LIMIT and OFFSET. If the requested page no longer exists (due to database records being deleted or updated) it may need to adjust the value for $pageno and return the adjusted value back to the user. If you are saying that this technique is against your rules then I can only say that your rules are wrong.
In the context of the 3-Tier Architecture the presentation/display logic in the Presentation layer is responsible for transforming the data obtained from the Business layer from its internal format, which is a PHP array, into a different format which is more presentable to the user, such as HTML, CSV or PDF. There is no code in the Business layer which performs this transformation, so it is completely wrong to say that there is presentation logic in the Business layer. The "formatting" logic in the Business layer does not transform the PHP array, it does nothing but format dates and decimal numbers within the array according to the user's language preferences.
Pagination is only concerned with the selection of data and has absolutely nothing to do with the formatting of that data. Pagination is only required when the output format is HTML and, following the rules of the 3-Tier Architecture, it cannot be handled in a separate class as it requires activity in two separate layers:
It requires HTML controls in the presentation layer so that the user can identify both the page number and the page size. That is presentation logic.
It requires code in the data access layer in order to calculate the values for OFFSET and LIMIT to be inserted into the SQL query. That is database logic.
These two outer layers are separated by the middle business layer, therefore the values for page number and page size are set in the presentation layer, then pass through the business layer to the data access layer where they are actioned. The data access layer then retrieves the data for the selected page number, calculates the number of the last page, then returns that information to the business layer and subsequently to the presentation layer where the user can view the data which he has selected.
Well, in a way, they are for formatting really. Your layer doesn't need any concept of a page per se since it really has nothing to do with actually doing anything with the data. I certainly wouldn't call it 'wrong' that's for sure. You've simply added a small bit of presentation logic to your class. If you took what you have and moved the 'formatting/presentation' bits into a separate class leaving just the data manipulation bits in your class it might squash that criticism. Personally I'd probably do it exactly the way you have since it's rare that data manipulation and presentation are totally separate things (IMO).
While you are correct in saying that the data access object does not actually do anything with the data (apart from converting them to values for OFFSET and LIMIT is the SQL query), it does have the responsibility to retrieve the correct data. When it is required to retrieve page N from a data source which currently holds thousands of pages it would not be efficient programming to retrieve all available rows and leave it to the presentation object to work out for itself which of those rows belong in the requested page. It is considered 'best practice' to retrieve only those rows which belong in page N, which means that the data access object must be given the values for $pageno and $rows_per_page so that it can calculate the values for LIMIT and OFFSET which are then used in the SQL query.
I wouldn't go so far as to say BAD, but I would consider it to be ill-suited to the problem. I agree with him entirely that it's strictly formatting info, and therefor has no place in a db abstraction layer. It does, however, have a place in a DbTableRenderer, e.g., or a layer which builds off of the db layer. Consider that a PAGE is a layout convention, and layout is formatting. Data selection has no unambiguous concept of 'page'. I am of the opinion that SELECT data, for example, is in essence a formatting option (the WHERE clause, on the other hand, is specifically a logic operation), and that shoe-horning such things as paging into the db layer isn't necessary. I would first write the db layer and then make another layer which includes the selection/limitation code.
Rubbish. If the instruction from the user is 'give me the database rows that belong in page N' then it is up to the data access layer to retrieve only those rows which belong in page N, which means that it must incorporate values for LIMIT and OFFSET in its SQL query. This can only be done in the Data Access layer and can never be done in the Presentation layer. This is called 'efficient programming', a concept with which you are obviously unfamiliar. As you seem to be totally ignorant as to how pagination works I consider you to be "ill-suited" to give me instructions on how it should be done.
The information is typical formatting information. The organization of data into pages belongs in presentation code. From a purist perspective, SQL operates on sets, and so operations like 'get me item 1 through 10' makes no sense since sets have no intrinsic ordering. But the second one applies the SORT operator, the result is no longer a set, but a list -- a structure with a defined order, and hence the retrieval of rows 1 through 10 suddenly makes sense.
I do not agree with that opinion. When you issue an SQL query the selected data is returned as a number of rows in a result set. It does not matter whether that set is ordered or not, or whether it contains all the rows in that table or just a subset, it is still a result set. By giving that result set different names in different circumstances you are showing that you do not understand simple concepts and try to make them more complicated than they need be just to prove how clever you are. To me the effect is the exact opposite.
Some people seem to have a bit of a problem distinguishing the difference between the selection of data and the formatting or presentation of data. First let me provide some definitions from the dictionary:
selection n
The action or an act of selecting something or someone; the fact of being selected
A particular choice; a thing or person selected; a number of selected things or persons; a range of things from which one or more may be selected
somebody or something chosen from among others
the range from which somebody or something can be selected
an act of choosing somebody or something from a wide variety of others
format n
a style or manner of arrangement
the way in which something is presented, organized, or arranged
the layout and presentation of a publication, including its size, and the type of paper and type used
the structure or organization of digital data for storing, printing, or displaying
format vt
arrange or put into a format; impose a format on
to arrange the layout or organization of something
presentation n
the style or manner in which something is presented, described, or explained
the manner in which something is shown, expressed, or laid out for other people to see
In the 3 Tier Architecture all data formatting is performed within the presentation layer, and all data selection is performed within the data access layer. In my code data is selected by the data access layer when it issues the sql SELECT statement, as in:
SELECT <columns> FROM <table> WHERE <conditions> LIMIT <row count> OFFSET <offset>
If I were not allowed to use the LIMIT/OFFSET clause on the SELECT statement the only other option would be to retrieve ALL possible rows and pass them ALL back to the presentation layer which would then have the task of filtering out the chunk that it wanted to display. That would be an extremely inefficient way to implement pagination, and anyone who advocates such a level of inefficiency is not qualified to lecture me about 'best practice'.
Data is formatted or presented to the user by the presentation layer which takes whatever has been returned by the data access layer (via the business layer) and generates the necessary HTML output. I do not show any code from my presentation layer here as all my HTML output is generated not by any PHP script but via XML and XSL transformations, as discussed in the following articles:
My variables $rows_per_page and $pageno originate in the presentation layer but are passed to the data access layer where they are used to construct the sql SELECT statement.
My variable $lastpage is generated by the data access layer after it has determined how many rows would satisfy that query without being restricted by the LIMIT clause. It is then passed back to the presentation layer so that it can be included in the 'page x of y' display.
They all appear in the business layer simply because they are passing through between the other two layers.
I cannot conceive of any way to achieve my objective without having those variables pass through the business layer, therefore I cannot accept any arguments that say they should not be there.
An offshoot of this technique means that my generic PHP code does not even have to deal with field names in order to generate the HTML output. How is this possible? Simply because my code passes the entire array, whatever it contains, to a standard function which turns it into an XML file. A second function then turns this into HTML output by performing an XSL transformation.
In my original implementation I had a separate XSL stylesheet for each screen as the table and column names were hard-coded within each stylesheet. I have subsequently found a way to supply the table names, column names and column labels within the XML data itself, which means that my library of XSL stylesheets is now much smaller but more re-usable. This is described in detail in Reusable XSL Stylesheets and Templates.
If it serves the purpose, great, and that makes it good for it's purpose. However, that almost inherently makes it less flexible for later adaption into other contexts. What if I wanted to use your db layer but didn't want the paging code? Is the class designed in such a way that I am forced to use it?
If you don't supply values for $pageno and $row_per_page then no pagination will be performed and you will be given *ALL* the rows that satisfy the current query. If you only want a subset then you *MUST* provide that data. The choice is yours - all the data, or just a subset. How you use the values for $pageno and $lastpage in your presentation layer is entirely up to you.
My code currently has the following levels of flexibility:
On an HTML page where pagination is in operation there will be hyperlinks available to allow the user to select other pages. The area containing these FIRST/PREVIOUS/NEXT/LAST hyperlinks also shows 'Page X of Y' so that the user knows exactly where he is.
Currently these links are limited to FIRST, PREVIOUS, NEXT and LAST but could easily be changed to include a range of specific page numbers if so desired as all the relevant HTML code is generated by a single XSL template which is shared by all component stylesheets. The only input required by this template is $curpage and $lastpage.
The hyperlinks generate a request for an absolute page number, not a relative one, so my getData() method only has to deal with one possible value. I do not need additional methods such as getPreviousPage() or getNextPage() as my existing method can cope with all possible circumstances.
If the value for $pageno is less than 1 it will be reset to 1.
If the value for $pageno is greater than $lastpage it will be reset to $lastpage.
When a table object is instantiated and no value for $pageno is provided it will automatically default to 1.
The table object will be maintained in the session data until it is no longer required. In this way it will continue to use whatever value it has for $pageno until it is changed.
Other requests from the client, such as using the hyperlinks in the column headings to sort the data, will refetch the data but retain the current page number.
The value for $row_per_page is not hard-coded anywhere (although a default value is defined with the class constructor), therefore it is possible for it to be changed at any time. I have added hyperlinks to the middle line of my navigation bar which allow the user to change the page size at will.
All pagination can be tuned off simply by setting $rows_per_page to zero.
My code was later enhanced to allow the pagination area to contain a greater selection of page numbers in the 'google' style. This did not affect the data access layer in any way as the changes were confined to the presentation layer. Does this qualify as 'flexible' or not?
Why not? What problems does it cause? Where are these problems documented? What are the alternatives?
Surely the whole idea behind OOP is that for every entity in the real world that you are attempting to model you must have a separate class which defines the properties, methods, data validation and business rules which are relevant to that entity. So if you are modelling the sales of products to customers you end up with separate classes for PRODUCT, CUSTOMER and SALES. As the details of these entities are not held in memory but in a persistent data store you have a different database table for each entity, which gives you a PRODUCT table, a CUSTOMER table and a SALES table. This gives you the following:
real world entities
Products, Customers, Sales
software classes
Products, Customers, Sales
database tables
Products, Customers, Sales
So if I have a separate class for each entity and a separate database table for each entity, how is it wrong to say that I have a separate class for each database table? I do not store the details for products, customers and sales in the same database table so it would not be logical to have a single class to deal with all database tables. Unless of course you are talking about having a single Data Access Object which does nothing but handle the generation of all SQL queries for any table in the system, but guess what? I have one of those already.
This code leads to a problematic dependency between the DB and the class.
That is a meaningless statement as whenever you write a piece of software which communicates with an object in the outside world then there is always a dependency between the software and the external object. To suggest otherwise would be incredibly naive.
All software I have ever written which communicates with a database table has to have some knowledge of the structure of that table within its code. It has to know which tables exist in which database, which columns exist on each table, and the specifications for each column. Without that knowledge the software would not be able to write to nor read from the database. You cannot add a field to a table, or remove a field from a table without making a corresponding change to some part of your code. The database table and the software which accesses it must always be kept synchronised otherwise there will be big problems. This is not a unique failing in my design, it is a common feature of all programs in any language.
In order to model a real world entity you need the following:
A clear definition of each entity, its data requirements, and the operations that can be performed on it.
A database that stores the data required by that entity.
Program code that performs operations on that data.
It should be obvious that both the database and the program code are there to model the needs of the real world entity, therefore there must be a high degree of interaction and inter-dependence, otherwise the results would not be as expected. The software component must work hand-in-glove with its data store, and any change in the software must be reflected in its associated data store, and vice versa. To suggest otherwise shows a complete lack of understanding of how software works.
When you create a software component to maintain the contents of a database table then the two must be kept synchronised otherwise they will not work properly. Each is dependent on the other in order to work effectively, so there has to be a certain amount of dependency between the two. In what way can this dependency considered to be "problematic"?
I understand the point of reusing code to generate SELECT/INSERT/UPDATE/DELETE statements, but you can do that without having to create a class for every table you have. Say I wanted to talk to the table 'cars'. I'd compose an object by creating an instance of a Table class and add rules represented as objects to it. I think that if you ask some good designers they will tell you that an approach which uses instances of a single Table class is better than one which requires the declaration of a new class for each new table.
What you are talking about is called object composition, and when I eventually discovered what it meant I discarded it as a clumsy and inefficient method of constructing an object. Creating an empty object and then injecting the business rules for a particular database table into it requires you to have all those business rules defined somewhere so that you can inject them into somewhere else. If this "somewhere" is a class which defines the business rules for a specific database table then surely it would be more efficient to simply instantiate that "somewhere" class into a fully-fledged object instead of creating an empty "somewhere else" object and then moving those rules into it.
There is a tried and tested technique of taking a base class and adding rules to it in order to create a concrete class - it is called inheritance. In this example the base class Bicycle is extended into subclasses for MountainBike, RoadBike and TandemBike. All I am doing is following this example so that my base class Table is extended into subclasses for OrderTable, ProductTable and CustomerTable. How is that wrong?
What you seem to be proposing is a structure like this:
In this structure CLASS A contains the definition of the generic table class while SCRIPT B1, B2, B3...Bn contain the physical implementation details for individual database tables, one per table. At runtime SCRIPT Bn would create an instance of CLASS A then load the object with those implementation details. If CLASS A has been defined as an abstract class then this cannot possibly work as the rules of OO prohibit an abstract class from being instantiated into an object, or don't you follow the rules? You *MUST* extend the abstract class into a concrete subclass through inheritance, and only then can you instantiate the subclass into an object.
In this structure CLASS A is never instantiated into an object directly. Where you had SCRIPT Bn I now have SUBCLASS Bn which extends CLASS A and therefore includes its entire contents through that mechanism called inheritance. This means that I do not require any extra code to transfer details between SCRIPT Bn and OBJECT A as they are already there. The problem of primary validation is solved by each subclass loading in its own particular set of field specifications, as generated by the data dictionary. The problem of secondary validation is solved by placing whatever code is required in the relevant custom hook method within the subclass, which overrides the non-abstract method which is defined in the superclass.
If you examine these two methods closely you will find that mine is more successful than yours. My implementation demonstrates that I understand the principles of OOP whereas your implementation demonstrates that you and your so-called 'good designers' do not.
In my implementation all generic code goes into an abstract superclass, while all non-generic code goes into subclasses, one subclass per database table. The generic code is therefore shared through inheritance. In addition, the generation of all SQL queries is handled in a totally separate Data Access Object. Your method, and that of your so-called 'good designers', of instantiating an instance of what is clearly an abstract class to create working objects does not adhere to the principles of OOP. If I added the keyword abstract to the definition of my superclass the language would physically prevent it from being instantiated into an object, therefore the method that both you and your so-called 'good designers' use is totally at variance with the principles of OOP. It is YOUR method which is wrong, not mine.
He also wrote:
Abstract concepts are classes, their instances are objects. IMO The table 'cars' is not an abstract concept but an object in the world.
You are getting lost in your own interpretation of the terminology. You cannot create an object for 'cars' without having a class for 'cars', just as you cannot write a 'cars' record into the database without having a 'cars' table. As far as I am concerned there is a one-to-one relationship between 'entity', 'class' and 'database table', so if 'entity=class' is correct and 'entity=table' is correct, how can 'class=table' be incorrect?
According to OOP Principle #2 a 'class' is the blueprint while an 'object' is a working instance of that blueprint. If you look at the CREATE TABLE script for a table is this not a blueprint? Is not each row within the table a working instance of that blueprint? Is it therefore not unreasonable to put the table's blueprint into a class so that you can create instances of that class to manipulate the instances (rows) within that table?
He also wrote:
Classes are supposed to represent abstract concepts. The concept of a table is abstract. A given SQL table is not, it's an object in the world.
If you examine this person's statement you will see that it is his interpretation of that statement which is questionable:
The concept of a table is abstract.
This is why I have an abstract table class which identifies every operation which can be performed on any (as yet unspecified) database table.
A given SQL table is not, it's an object in the world.
If a given SQL table is an object in the world, and I can only instantiate a software object from a class, then it surely follows that each SQL table requires its own class. This is why I have a concrete table class for each physical database table which defines the specific characteristics of that database table. These characteristics include the table name, a list of all the columns in that table, the data types and sizes of each column so that the input data can be validated before it is passed to the Data Access Object, plus any other business rules or task-specific behaviour. There is a vast amount of code which is common to all database tables which I inherit from the abstract table class. Note that the table class does not generate any SQL statements as this is the sole responsibility of the Data Access Object for which there is a separate class for each DBMS engine (MySQL, PostgreSQL, Oracle and SQL Server). Thus my "table" object is not the same as my "database" object.
He also wrote:
You wouldn't model people by creating a Person class and subclass it for each new person would you? The concept of a Person is abstract, a given person is not.
Only an idiot would suggest creating a separate subclass for each instance of an entity. This would create subclasses which would be absolutely identical to the superclass, so there would be no point in having them. That's just as stupid as suggesting that each database record should be held in its own table. The Person entity requires a Person class from which any number of instances can be created. It also requires a Person table which can hold any number of Person records. Each different entity in the real world requires its own separate class just as each entity requires its own separate database table. As you can see the relationship between my Person class and Person table is one-to-one, which is why I say that I have a separate class for each database table. Why do you keep insisting that this is wrong?
Each table in a database is a different entity and not just a different instance of the same entity. There is a standard concept called "table" but each physical table has a different implementation - its name and its structure. That is why each concrete class simply identifies its name and its structure while all the standard code is inherited from the abstract class.
In a system with 12 database tables, having a different class for each table? That's not good. Having a separate class *instance* is good OO, having a separate *class* is bad OO, since you lose all the potential benefits of low maintenance, etc.
How can it possibly be bad? If each database table has its own structure and business rules then those details must be defined somewhere, and it makes sense to me to define each table's details in its own class. What other options are there?
If I have 12 database tables it is obvious that I am dealing with 12 different entities with different properties and business rules, and it is a fundamental principle of OO that each different entity is required to have its own class. Each different entity also requires its own database table, therefore there is a one-to-one relationship between entity, class and table. Having a separate class for each database table most certainly does NOT lose the potential benefit of low maintenance. In my class hierarchy I have identified the following distinct levels:
An abstract superclass containing generic code which can be applied to any as yet unspecified database table/entity.
A concrete subclass for each individual database table/entity containing the specific information required to process that entity, which includes all the data validation and business rules.
A separate data access object (DAO) which can generate the SQL query for any table in any database. I have a separate class for each DBMS so I can easily switch from one DBMS to another.
Thus all the information required to process any individual entity is contained within its own class. This is called encapsulation. Every piece of code that is common to all entities is held within a single superclass and shared through inheritance. These are two principles of OOP that were specifically designed to promote low maintenance, and unless you can find any fault with my implementation of these two principles I think you will find it extremely difficult to come up with ANY design that could possibly offer less maintenance.
This means you write the same code for each table - select, insert, update, delete again and again. But basically its always the same.
If you think that my implementation contains a lot of duplicated code then you obviously have not been paying attention. Any code which needs to be executed for any database table has been defined once in an abstract table class and which is then inherited by every concrete table class, so there is no duplication whatsoever. In some cases the code has been moved into a separate sharable object. For example, none of my table classes generates any sort of SQL query and sends it to the database - that is the sole responsibility of my Data Access Object (DAO). It does not matter how many table classes I have, or what query needs to be executed, it *ALWAYS* goes through the DAO. I have a separate DAO for each DBMS (MySQL, PostgreSQL, Oracle, SQL Server) to ensure that the query is constructed in the correct manner for each DBMS. So if there is only one object in my entire system which constructs and issues SQL queries, where exactly is the duplication?
If having a separate class for each database table is not considered to be good OO, then can you please explain why Martin Fowler, supposedly an expert in this field, in his book Patterns of Enterprise Application Architecture has a pattern called Table Module? This contains the following text in its description:
A Table Module organizes domain logic with one class per table in the data-base, and a single instance of a class contains the various procedures that will act on the data.
There is another pattern called Class Table Inheritance which has the following in its description:
Class Table Inheritance represents an inheritance hierarchy of classes with one table for each class.
In PHP it is possible to break encapsulation by directly referencing a class variable, rather than getting the value through an accessor method. If you teach people why this is stupid, then only the stupid people will continue to do it. Thus, preserving encapsulation, even when a language allows it, is clearly a practice of such merit that we can without reservation call it a 'best practice'.
If this is supposed to be an example of 'best practice' that everyone knows, then I'm afraid that everyone has been seriously mis-informed. This whole idea is based on one inaccurate statement after another leading to a false conclusion. Take the following:
Encapsulation is the same as Information Hiding.
Information Hiding is the same as Data Hiding.
Data Hiding means not using public variables.
Therefore: Encapsulation is the same as not using public variables.
If it can be demonstrated that any of the leading statements is false, then it must follow that the conclusion in the final statement is also false.
Consider these articles I found after a quick search of the internet using google and the word 'encapsulation':
The idea of implementation hiding is to do with the hiding of critical design decisions, such as whether a particular piece of data is obtained directly from the database or derived at runtime using some magical algorithm or even plucked out of thin air. Thus the implementation of an operation is nothing more than the code behind that operation, and not the data on which it operates.
Data hiding is a characteristic of object-oriented programming. Because an object can only be associated with data in predefined classes or templates, the object can only 'know' about the data it needs to know about. There is no possibility that someone maintaining the code may inadvertently point to or otherwise access the wrong data unintentionally. Thus, all data not required by an object can be said to be 'hidden'.
I find this definition to be a little confusing and misleading. It divides data into two categories: data that the object needs to know about (the "right" data), and data that the object does not need to know about (the "wrong" data). By saying that the "wrong" data is hidden implies that the object has access to this data, but does not provide the mechanism by which you can see it. It would make more sense to me to ensure that the object only has access to the "right" data and no access at all to the "wrong" data. This would make the "wrong" data invisible because it is "not there" rather than "there but hidden". For example, if you have a Customer object and a Product object I cannot see any reason why you would make the "right" data in one of these objects accessible in the other object but hidden from view. To say that the "right" data should be hidden seems nonsensical to me - if the purpose of the Customer object is to maintain customer data then surely you must be able to both insert and retrieve that data otherwise it will be impossible to maintain that data.
Encapsulation means the placing of data and the operations that perform on that data in the same class. Breaking encapsulation therefore means to NOT put the data and associated operations in the same class. It has nothing to do with variables, public or otherwise.
This is just a case of misassociation, misconception, misinformation, misunderstanding, misinterpretation and misrepresentation being marketed as truth which most of you seem willing to accept without question. I seem to be one of the rare individuals who is not so gullible, probably because in my many years of experience I have encountered many so-called 'truths' which have crumbled under close scrutiny. I do not accept anything as 'true' until is has been proven to my satisfaction.
As this so-called 'rule' regarding encapsulation and public variables has been proven to be totally without merit I do not see that it is a rule worth following. It is a non-rule. It has ceased to be. It is deceased. It is defunct. It has met its demise. It has expired. It has become extinct. It has snuffed it. It has gone belly-up. It has passed away. It is bereft of life. It is a late rule. It is an ex-rule. It does not exist. It has bought the farm. It has been deep-sixed. It has departed this life. It has popped its cloggs. It has kicked the bucket. It has shuffled off this mortal coil. It is pushing up daisies. It has gone to meet its maker. It has joined the celestial choir. It has been carried away by the Grim Reaper. R.I.P.
Even more off the wall is the idea being touted around in some quarters that inheritance breaks encapsulation (refer to the third paragraph). OOP was founded on three basic principles, and these people have the nerve to say that one of these principles should be discarded because it interferes with one of the others? Puh-lease! Do you people use your brains for anything other than keeping your ears apart?
This type of blanket statement always raises warning bells with me because I have encountered many of them in my long career and without exception they have proved to be full of holes. I do not accept such a rule until I see definitive proof and justification. If no proof is available then as far as I am concerned it falls into the same category as myths, legends and old wives' tales.
I was once told by someone 'You can't use that technique because it's inefficient'. When I asked him to provide some sort of proof to justify that statement he could not. His only response was 'I read it somewhere'. After a lot of digging I discovered that the statement was written about a much earlier version of the development tool running on much slower hardware, but when tested on the current versions the difference had completely disappeared. That statement had passed its sell-by date and was no longer relevant, yet that particular developer was still sticking to it, which meant that his method was now the least efficient.
Sometimes a so-called problem can be greatly exaggerated, or claimed to be applicable to every situation when in fact its scope is actually quite limited. Take the case of the COMPUTE verb in a COBOL project which I documented here.
Too few programmers today are able to judge the seriousness of a problem. They cannot tell whether it is major or minor, just that there is some kind of problem. What you need is a series of structured questions to help you gauge the scale of a problem:
How serious is the problem?
It causes the whole system to crash.
It causes the program to crash.
It produces the wrong results.
It is very inefficient.
It is slightly inefficient.
It looks wrong, therefore it must be wrong.
How often does it occur?
Always, under all circumstances.
Always, under some circumstances.
Sometimes, under all circumstances.
Sometimes, under some circumstances.
Rarely.
If it is wrong then it must be causing a problem somewhere, but I don't know where.
What is the solution?
A major rewrite of the whole system.
A minor rewrite of the whole system.
A major rewrite of a single program.
A minor rewrite of a single program.
Programmer education and training.
Follow a different set of "best practices".
If you have a problem that scores mostly a's, then you have a real problem. But if it scores mostly e's then you are making a mountain out of a molehill. Using this scale it is quite obvious that the so-called problem with the COMPUTE verb was just a minor problem in education and training which the team leader was just too lazy to implement. He found it easier to impose an outright ban. When I published my own standards in 1984 I chose a different approach. Which do you think is the more professional?
People sometimes impose blanket bans because they are either unable or unwilling to investigate the problem in any depth and therefore cannot judge whether a particular instance is beneficial or harmful. For example, there are some instances where using a technical primary key on a database table avoids certain problems. Certain people of a limited mentality have expanded this to mean that you MUST use a technical primary key on ALL database tables WITHOUT QUESTION. This is absolute nonsense as there are circumstances where a technical primary key can actually cause problems, as I have documented in my article Technical Keys - Their Uses and Abuses.
As far as I am concerned there are two ways of applying a rule - intelligently or indiscriminately. Whenever I see a rule applied indiscriminately I immediately suspect a lack of intelligence on the part of that rule's author. The following rules are prime candidates for rejection:
Thou shalt not use the COMPUTE verb. Period.
Thou shalt not use public variables. Period.
Thou shalt not create a database table without a technical primary key. Period.
The following rules show that the author has thought about the problem and is attempting to educate rather than dictate:
The COMPUTE verb can be inefficient in some circumstances such as .....
Public variables may cause problems in some circumstances, such as .....
Technical primary keys may prevent problems in some circumstances, such as .....
I have searched the web trying to find actual examples of how the use of public variables causes problems, and I have concluded that the scale of this problem is nowhere near as large as people would have you think. There are times when making a variable private instead of public, thus forcing you to use a 'getter' or a 'setter' is a good thing. In this way should it ever be necessary to adjust the data before it is input or output you only have to change the code inside the 'getter' or 'setter' rather than all those places which reference the 'getter' or 'setter'. If a variable is only used by internal functions then there is no reason to make it accessible to the outside world, in which case it should be declared private and not public.
There are circumstances where accessing a public variable cannot cause any problems, therefore there is no advantage in banning its use. Even the authors of Java agree. The Java Tutorial in its chapter Controlling Access to Members of a Class says the following:
Declare public members only if such access cannot produce undesirable results if an outsider uses them.
Here are some examples from my article which fall into this category:
In this example all the variables I am writing to are immediately processed by code within the getData method. These variables are not used by any other methods, therefore there is no harm in leaving them public.
$dbobject->numrows will return the total number of rows which satisfied the selection criteria.
$dbobject->pageno will return the current page number based on $rows_per_page.
$dbobject->lastpage will return the last page number based on $rows_per_page.
These variables are set by code within my getData method and are destined to be output, therefore there is no harm in accessing them directly instead of via a getter.
There is an old saying in the engineering world: "If it ain't broke don't fix it". So, if my use of public variables does not cause a problem why do I need a solution?
In general I think your design is bad because you have to create a new class for every table you create, and you have to recode both the table and the class every time you change the table, which obviously doubles the chances of bugs. I can't really see how this can save you very much work I guess. So when you add a field to your DB, you also have to change the class, this sort of dependency can quickly lead to maintenance problems, especially if someone else is supposed to use the classes.
You are wrong on both counts:
If I create a new table all I do is import the table structure into my Data Dictionary, then export the table's details to generate the class file for that table. This concrete class inherits all the standard code, including data validation, from my abstract table class, so I do not have to write a single line of code.
If I change a table's structure all I do is repeat the import/export process in order to regenerate the table's structure file. I do not have to regenerate or even amend the table's class file as no properties or methods are affected.
Having a separate class for each individual database table is supposed to be a GOOD idea in OOP as it encapsulates all the information required to process that particular database table. This includes a list of all fields and their individual characteristics so that primary validation can be done by the generic code which is inherited from the superclass instead of having to write separate code to validate each table, plus the inclusion of custom code to process business rules which are specific to that table or entity.
In the 20+ years that I have been programming I have never come across a case where software which communicated with a file or database table did not have knowledge of the structure of that file or table built into it. If you amend the file's structure without amending the software's view of that structure then you quickly run into trouble. If your software tries to write to a column that no longer exists the whole operation will fail. If you add a column without amending your software then how can it possibly supply any value for that column? This principle holds true even for software which is built around a data dictionary or application model (and I have used several in the past 20 years) - if you change the database without making a corresponding change in the dictionary/model you *will* have a problem. So when you say that my software poses a maintenance problem and doubles the chance of bugs because each table class must be kept synchronised with the structure of its table then you could not possibly be any more wrong. My software incurs no more of a maintenance problem and causes no more bugs than any other software.
As an example let me compare my techniques with those contained within Building Database Interfaces which is supposed to demonstrate how things *should* be done according to the rules of OOP.
This is supposed to be the *right* way using 'setters':
<?php$dbobject = new Client;
$dbobject->insertRecord($_POST);
$errors = $dbobject->getErrors();
?>
Why should I waste effort in unpacking the $_POST array and feeding the data in one field at a time when I can provide it all in one single step? It is just as easy for code inside the class to address each field as $array['field'] as it is by $this->field.
Whose method will require the most changes if the structure of that table changes?
In this code $fieldarray is the array that was input via the updateRecord method, and $this->fieldspec (described in Using PHP Objects to access your Database Tables (Part 2)) is my array of field specifications for the table. My validateUpdateArray routine (which is contained within the superclass and automatically inherited by all subclasses) will examine each field in $fieldarray and where a field is specified as 'type' => 'string' it will automatically perform trim(addslashes()). Using other settings in my $fieldspec array I am also able to perform the following standard data checking:
That any required field is not empty.
That any numeric field contains a number (with checks for minimum/maximum values).
That any date field contains a valid date.
Whose method will require the most changes if the structure of that table changes?
Let us look at yet another area within the same article. Take this code which generates an sql UPDATE statement:
Here I am using a separate object to construct and execute all my SQL/DML statements. Notice here that both the database name and the table name are passed in as arguments. They are standard member variables within each table subclass and are assigned actual values within the class constructor. The WHERE clause of the UPDATE statement is easy to deal with as my $fieldspec array identifies those fields which are part of the primary key. For details on how this is actually implemented please refer to updateRecord Method.
Whose method will require the most changes if the structure of that table changes?
If you look closely at the code I think you will find that not only does my code NOT produce more of a maintenance problem when compared with what is supposed to be the *right* way, you should observe that it actually produces LESS of a problem as there are far fewer lines of code that would need to be modified if the structure of that table ever changed.
He also wrote:
In your approach a change in the abstract superclass could potentially wreak havoc on existing code. You can't know, all you know is that you have an enormous amount of dependency, and that's a bad thing. It could be as simple as you adding a variable for some purpose, forgetting that in one of the hundreds of derived classes you have shadowed this variable, and before you know it parts of your applications starts behaving randomly. That's no fun.
One of the benefits of reusable code is that you an write it once and share it many times. One of the drawbacks of reusable code is that you can screw up that one copy and you effectively screw up every place where it is shared. You simply have to weigh up the benefits and risks of a particular implementation, make a choice, then live with the consequences. My design has the same ratio of risk/benefit as any other design, so your statement has no value (IMHO). It is possible that my design can be broken by a fool, but then so can everybody else's. It is simply not possible to make a design foolproof - as soon as you think you've cracked it the universe will promptly respond by inventing a better class of fool.
If you say that these variables are in fact selection criteria, then certainly you must agree that seeing as $where is a collection of selection criteria, and it's being passed to getData(), it would be much more consistent to pass them as parameters!
I disagree entirely. The $where string may contain any number of variables, but I do not see any reason why I should unpack it into its component parts, pass in each part individually, then reassemble the parts into a string which can be used as the WHERE clause in an SQL query. I pass it in as a single string and use it to send out as a single string, so all that unpacking and re packing is totally unnecessary. A competent programmer would not suggest writing code to perform something which is not necessary.
You could say that a word is a collection of letters, so using your logic would you suggest that each individual word be handled as a collection of separate letters instead of a simple string? No? I thought not.
Also used loosely to mean 'irrelevant to', e.g. 'This may be orthogonal to the discussion, but ...', similar to 'going off at a tangent'.
I know that I am not the one who keeps going off at a tangent and losing the plot.
The claim that my validation code cannot be used in other places is completely bogus for one simple reason - I have a single class in my framework which handles primary validation, and this can be used on any database table in the application by virtue of the fact that it compares the field values contained in the common variable $fieldarray with the field specifications contained in the common variable $fieldspecs. These variables are available in ALL table classes, so my validation code can work on ALL database tables. How much code to YOU have to write to achieve the same thing which each new database table?
Your design is less reusable, because the validation code cannot be used in other places where it makes sense due to the lack of orthogonality. The design is inherently more static, and static designs are always less resistant to change.
I don't think you understand my design at all. The code which performs primary validation by comparing the contents of the $_POST array with the field specifications in the $fieldspec array is automatically invoked on every insert and update operation. The contents of the $fieldspec array is provided in the <table>.dict.inc file which is exported from the data dictionary, and the inherited code will take care of all the data validation. The programmer does not have to write any code to perform primary validation, so what is less reusable about that?
My validation code is used in every place where it makes sense. I have built several web applications using 48 tables spread across 4 databases, and which are utilised by over 200 components, so my design has been tested quite thoroughly and has met every challenge.
UPDATE: As of January 2021 my ERP application, which I built using my framework, contains 20+ databases, 400+ tables and 3,500+ user transactions, so please do not waste my time in telling me that my design is clumsy, inefficient, difficult to maintain and difficult to extend.
I don't understand the accusation that my design is too static and therefore less resistant to change. Each field/column in a database table is of a particular type and size, therefore the primary validation is limited to checking that the data input by the user conforms to these specifications. As the number of data types is quite static the code I need to validate each data type is just as static, but it is flexible enough to deal with every combination of data type and size that is thrown at it. Where is the problem with that? Tell me, is your validation code contained within a single reusable object, or do you have to write it separately for each column in each table?
When it comes to secondary or custom validation I have provided the following non-abstract methods in my superclass which are automatically called at the relevant point in the processing cycle:
_cm_validateInsert for records being inserted.
_cm_validateUpdate for records being updated.
_cm_commonValidation for records being either inserted or updated.
_cm_validateDelete for records being deleted.
I think I have covered all the bases. Do you think you can do any better?
Say I wanted to talk to the table 'cars'. I'd compose an object by creating an instance of a Table class and add rules represented as objects to it. Of course, the business rules should be taken care of by the DBMS, not your application code, but unfortunately that is not completely possible in current SQL systems.
Business rules belong in the application, not the database. If I put the business rules inside the database instead of the class then won't this break encapsulation? Also, no DBMS can handle business rules in a 'user friendly' manner, they can either accept an insert/update or reject it. In the case of a failure the error message may not be very useful. That is why it is necessary to write program code to validate the user's input before it gets sent to the database. It has been this way for decades, and will still be this way for many more decades.
The approach which you describe above shows that you do not fully understand how to use the basic OO features OO features which are provided in PHP.
Instead of creating an instance of a table class and inserting objects for each rule I use an abstract table class which contains all the code which is common to every database table. This class is then inherited by every concrete table class which provides the details which are unique to that particular table. According to Erich Gamma, one of the authors of the GoF book, this is the correct way to use inheritance, and is far easier to implement and easier to understand than object composition.
Secondary validation is handled by custom code which the developer can insert into any of the available hook methods within each table's subclass.
So let's take a simple rule like 'the name of the car should be at least 1 character, and no more than 32'. To model this I'd create a String object that has this limitation built in, and link it to the 'name' field in the Table object.
I do not like this idea for the following reasons:
PHP does not include such ridiculous things as objects to handle strings.
Why should I create an entire object just to hold one simple rule?
How do you link an object to a field?
I can already implement that rule very simply with the following code inside my class constructor:
Other common data types are Number, Date, File, Time, Creditcard etc. These are fairly simple type validations, but they should go a long way. You'll probably also want to have some sort of generic Rule object for rare cases where none of the available objects suffice, and you don't want to create a new class. It is of course very important that these things are implemented separately, so that they can be reused whenever you need to validate any data.
If you are suggesting that I have a separate object for each piece of data validation or business rule then you are wasting your time. All my data validation rules go into a single validateField() method in my validation class which compares the contents of a data array with the field validation rules in a $fieldspec array. All the business rules for an entity go into the appropriate validation method within that entity's class. This approach is simple and it works very effectively, so I won't waste any time investigating your method.
But the database can enforce a lot of constraints, and one should really put as much business logic into the database as possible because:
* It's less work
* It's safer from bugs, because the DBMS developers have (hopefully) tested it properly.
* It's most likely faster.
I do not like this idea for the following reasons:
Moving data validation/business rules to a place outside the class breaks encapsulation. (Gotcha!)
It is not less work because it still has to be defined somewhere.
I do not use separate DBMS developers because they will want to follow their own set of stupid rules for designing databases. When a database is being used by MY application then I insist on designing that database according to MY rules.
DBMS developers are just as capable of screwing up as any other kind of developer.
Speed is lower down the list of priorities than maintainability. Hardware is dirt cheap compared with the cost of a developer.
I see that you among other things have code to enforce foreign key constraints, but wouldn't it be much better not to need that code at all?
The code has to go somewhere, and I prefer to have it all in one place where it is easy to get at and easy to maintain. I have worked on a system where half the code was in program modules while the other half was spread around a multitude of database triggers and stored procedures, and I can only describe it as a 'mucking fess' (if you catch my drift). Besides, foreign key constraints in the database will only work in the way that the database designers allow them to work, but if the constraints are handled in my code then I have total control and total flexibility over how they work. For example, if I cannot delete an entry from a parent table if any associated entries currently exist on a child table your method would require that I issue the DELETE FROM parent WHERE pkey='whatever' query which would then fail. In my method I have code to check this (which is provided in my abstract table class), which means that I can detect this error *before* I issue the DELETE query and issue a totally customised error message. This in turn means that any database error can be treated as a fatal error and terminate the application immediately rather than passing it back to the calling module which then has to decide what to do with it.
There is a very common error which people do the first time they do OO, and that is to overuse inheritance. It's not that strange really as there's always a lot of fighting over inheritance. But object composition is a second technique that frequently applies. Where you see only inheritance, I see inheritance and composition.
You have totally misunderstood my design as there is no way that I overuse inheritance. All my concrete table classes, and I have hundreds, inherit from a single abstract class. My inheritance hierarchy is only one level deep, so how can this be described as "overuse"?
I have investigated this thing called 'object composition' and found the following references:
Object composition allows you to group components together, creating a new component. Composition of visual components requires a container component, that acts as a parent window for its subcomponents.
As this is talking about graphical/visual components I find it of no use whatsoever.
Most designers overuse inheritance, resulting in large inheritance hierarchies that can become hard to deal with. Object composition is a different method of reusing functionality. Objects are composed to achieve more complex functionality. The disadvantage of object composition is that the behavior of the system may be harder to understand just by looking at the source code. A system using object composition may be very dynamic in nature so it may require running the system to get a deeper understanding of how the different objects cooperate.
The same article also says the following:
However, inheritance is still necessary. You cannot always get all the necessary functionality by assembling existing components.
In the first place I do not have a large inheritance hierarchy as all my concrete table classes inherit from a single abstract table class, therefore I am not overusing inheritance by any stretch of the imagination. If I don't have a problem then why do I need a solution?
In the second place I am not going to change a method which is simple and effective for one that introduces another level of complexity for absolutely no discernible benefit. This is another one of those loony OO ideas that I shall consign to the khazi.
Interestingly enough the same article also contains this:
The disadvantage of class inheritance is that the subclass becomes dependent on the parent class implementation. This makes it harder to reuse the subclass, especially if part of the inherited implementation is no longer desirable. ... One way around this problem is to only inherit from abstract classes.
Where it says the subclass becomes dependent on the parent class implementation makes it blindingly obvious that you are inheriting from a class which contains an implementation which you may not want. This either means that you are inheriting from a concrete class, or you have mistakenly put a concrete implementation inside an abstract class. Both of these are signs of poor programming practices.
Guess who's method is following "best practice" by only inheriting from an abstract class? Answers on a postcard to .....
Another advantage of having a single abstract table class which is inherited by every concrete table class is that it enables me to make extensive use of the Template Method Pattern where common sharable code is defined in the abstract class while changes in behaviour can be specified within each individual subclass by overriding the implementation defined in the variable/customisable methods in the template.
I have written more on this topic in the following:
In response to my statement The language allows me to do it, therefore it cannot be wrongAndré Næss wrote:
It depends on your usage of the word wrong. C allows me to write code that generates random segmentation faults, and assembler allows me to write self-modifying code.
Any programmer who writes code that causes such problems has obviously not been trained correctly. If he has been trained but still does it then he is an idiot. If I ever come across such problem code I investigate it to find out the seriousness of the problem - does it happen always or only in some circumstances - then I document it so that my findings can be passed on to others.
The ability to write self-modifying code sounds like the ALTER verb in COBOL. I wrote about that in my COBOL Programming Standards way back in 1984.
If the language has a statement/command/verb which does not cause problems, or my usage of it avoids any such problems, then I do not see any reason why I should not use it. If you have a problem with that then the problem is yours, not mine. As a software engineer my task is to write code that performs its task reliably and efficiently, and I will use any command or function that the language provides in any way I see fit to achieve that objective. Any command or function which is proven to be unreliable or inefficient I will avoid like the plague, as any competent programmer should. Notice the requirement for proof, not the acceptance of unsubstantiated opinion.
Each language has it's collection common of knowledge known as best-practices. If you want to write good software in whatever language you choose there are basically two approaches:
I'm so much smarter than all the people who have worked with this language before, I can do it better, because I *really* know how it should be done. Screw the best-practices and the knowledge they have collected through decades of experience, I'll do it my way.
I'll better listen to the masters if I want to be an expert in this language.
But who exactly are my 'masters'? Where is this 'best practice' documented?
When something is described as "best" it is supposed to be "better than the alternatives", but has anybody bothered to identify these alternatives and evaluated which one is actually better than all the others? Too many people regard something as "common practice" when as a matter of fact it is the "only practice" that they know. Then they have the audacity to elevate it to "best practice" when those who are actually aware of the alternatives have a different opinion. Different groups of programmers have different opinions as to what is best, so what is best for one group may not be the best for another. Not only do I have the right to hold an opinion which is different from yours, I also have the right to express it. I am not demanding, or even suggesting, that you should change your opinion to match mine, so why do you keep insisting that if I don't change my opinion to match yours that I am an idiot? The practices which I follow have enabled me to become far more productive than you could ever be, so if my results are better than yours how can you possibly claim that your practices are better than mine?
The project leader who decided that the COMPUTE verb was bad was clearly not a master of anything as I eventually ignored his project standards, his idea of 'best practice', and produced software that was praised as being the most well written, well structured and well documented in the whole project when audited by a senior consultant.
I ignored his development standards and began to create a set of my own. Several years later when I was a senior programmer in another company my personal standards were adopted as the company standards. Some time later, after my standards had been used successfully on several projects, I received praise from 2 quarters. My fellow workers came to me with their questions and their problems, so to them I was the master, the guru.
Several years later the company switched to a new language for which I developed new standards. Again I was able to produce a development environment that was unrivaled in its productivity. I was still the master.
In 1999 I joined a team of clowns who attempted to implement the 3 tier architecture in Uniface, my primary language at the time. They had a team of 6 developers who took 6 months to design and build a development infrastructure, but when it came to building live components they found that it was taking weeks instead of the estimated days. When I told them that their entire methodology was wrong they said 'It cannot be, we are following all the rules!' They asked me how I would do it, but when I told them they said 'You cannot possibly do it that way because it is the wrong way.' The client found their implementation schedule to be totally unacceptable, so the whole project was cancelled. As I had time on my hands I set about converting my existing 2-tier development infrastructure into 3-tier, and in a space of two weeks the conversion was complete and I was able to create working components in less than an hour apiece. Only someone of questionable mental ability could possibly conclude that their methodology, which took weeks to build a single component, was *right* whereas my methodology, which took hours to build the same components, was *wrong*. I found their approach and their attitude so laughable that I documented their failure in an article on my website called UNIFACE and the N-Tier Architecture and later in Disaster #3. I followed it by documenting my success in 3 Tiers, 2 Models, and XML Streams.
By this time I was getting extremely frustrated with other people's attempts at defining their version of 'best practice' so I wrote Development Standards - Limitation or Inspiration? which highlighted all the areas where their techniques were actually slowing down the development process instead of helping to speed it up.
Later on I joined another company who called themselves 'innovators' and who boasted that they had successfully implemented the 3 tier architecture. Although it worked it was extremely inefficient compared with what I was used to. I found so many places where their standards created obstacles to speedy development that I wrote them a 17 page 9,000 word document which highlighted all the deficiencies which I found. They seemed content with their development environment which took 1½ days to build a simple component until I showed them that using my own techniques I could create the same component in under an hour. I documented their 'success story' in How not to implement the 3 Tier architecture in UNIFACE.
The last article I wrote on this particular language was called UNIFACE is not a Rapid Application Development tool in which I stated that although the language had the potential for being a RAD tool every implementation I had ever seen was so ineffective and inefficient that it had obliterated that potential and turned the 'R' in RAD from 'rapid' to 'retarded'.
If the term 'masters' is supposed to identify those of superior knowledge and ability then I can only say that I have not met anyone who fits that description for over 20 years. The only thing that others seem eager to teach me is how to slow down development instead of speed it up, how to create obstacle courses for developers instead of smooth paths. This only has the effect of teaching me which practices to avoid like the plague.
If all the programmers using one language adopt some practice because it seems great then that becomes a 'best practice' for the language. Look around and you'll see dozens of examples of this everyday. 'Do not break encapsulation' is a good example of a 'best practice'. We are talking about those practices that programmers tend to pick up and imitate. If a company (or, more likely, individual programmer) develops a practice and it catches on worldwide, and most of the programmers using that language adopt it as one of the loose rules to live by, the it can be considered a best practice for that language. If a company comes up with a rule and the rule does not catch on worldwide, then the rule is not a best practice for the language.
Just because a lot of programmers follow a particular practice does not necessarily make it 'best', just 'most imitated'. Some follow a practice because they don't know any better. Others follow a practice because they are told to by people who are supposed to be their 'superiors', and they dare not disobey. I have already taken your don't break encapsulation rule and shown it to be a pile of pooh, and I have also shown that the method of using abstract classes by so-called good designers goes totally against the principles of OOP.
In response to my questions 'Who creates these best practices? Where are they published?' André Næss wrote:
Nobody creates them, they emerge by the collective work of thousands of developers.
But somebody must write them down and publish them, otherwise how are the rest of us mere mortals supposed to know about them? Have these standards been published anywhere?
No and yes. There is no bible, but there is a large body of books and articles and newsgroup discussions that all taken together is the collected knowledge.
Knowledge that is scattered far and wide and is not readily accessible is of no use to anyone. There is just not enough time to read every book that has been printed, every article that has been published, every posting in every newsgroup. The novice programmer expects to go to the library of knowledge and pick out one or two volumes he can read and digest and not have to search through every document in the entire building. Even among all this collected knowledge you will find disagreement, different interpretations and conflicting opinions. How is the novice programmer supposed to separate the wheat from the chaff? The pragmatic from the dogmatic? The awesome from the awful? The beneficial from the barmy? The creditable from the crap? The definitive from the defective? The excellent from the excrement? The fact from the fiction? The great from the grotesque? The harmonious from the hazardous? The important from the irrelevant? The joyous from the jaded? The knowledge from the sewage? The laudable from the lamentable? The meritorious from the mediocre? The notable from the naff? The obvious from the obfuscated? The praiseworthy from the pathetic? The quintessential from the questionable? The ripe from the rancid? The sweet from the sour? The truth from the tripe? The useful from the useless? The veritable from the vomitable? The worthy from the worthless?
Certain books becomes classics, classics are considered such because a large number of people view them as such. They might of course all be wrong, which is why we have the occasional paradigm shift :)
For every book you find which advocates one particular theory or method you will find others which support a contradictory theory or method. They cannot all be right, and they cannot all be wrong. Each theory will find its own group of supporters, and each group may have success while following their chosen path. If there is room in the universe for all these different methods and theories to co-exist, then why cannot I be allowed to choose my own method of implementing the principles of OOP?
All I can say that I assume nobody comes up with practices because they want to be *worse* programmers, so I think it's safe to assume that they do so to produce better software, to be better at their craft.
Nobody deliberately publishes a document of 'worst practice' (unless they have a sense of humour, in which case take a look at How To Write Unmaintainable Code and PHP The Wrong Way), but you have to remember that each document is not the best that the entire universe of programmers has to offer but the best that a particular individual (or group of individuals) has to offer. It will be limited to his/their experiences and abilities, and not the sum total of experience and abilities of the entire universe of programmers. It is therefore highly probable that someone of greater experience or ability will eventually come along and produce something that is even better. This is called progress. When I was teaching myself PHP I took a look at some of the methods and techniques that had been published and I said to myself 'I can do better than this.' And I have.
Most of the examples of 'best practice' that I have encountered in my long career have been nothing more than brain dumps from people recently promoted to team/project leader. Instead of saying 'this is the best way to do it' their approach is 'this is the way that I do it, and I want everybody to do it the same way'. These people do not like their opinions being questioned and so refuse to discuss the possibility that there may be a better way. They do not experiment with various ways and evaluate the results to find out what is best, they simply pick an idea out of a hat (or so it seems to me) and stick with it regardless of how effective and efficient it is. Because they cannot be bothered to look for better ways they will never improve and will therefore always be second-rate.
In all the years that I have been programming I have never stopped looking for a better way, a quicker way, a more flexible way. Most of the time it has been down to a little change here, a little tweak there. Individually the changes may appear to be insignificant, but taken collectively there is a big difference. I regularly ignore the advice of those who consider themselves to be masters and I regularly outperform their feeble efforts. I did it in COBOL, I did it in UNIFACE, and it looks like I've done it again with PHP.
If I was to code this I'd probably write a sort of PagedPresentation thingy, which is meant for this sort of situation. PagedPresentation should just supply a framework for creating paged presentations, and it has to be coupled with a data source. The data source supplies the PagedPresentation with data, and the PagedPresentation transforms these data as defined by the developer using some sort of template (a simple HTML/PHP mix is sufficient).
But there obviously has to be a connection between the data source and the presentation, because the presentation outputs stuff which in the end has to result in $_GET variables which define what page to display. And this data then has to be used to figure out what rows to fetch.
So, we have to figure out how to implement this as clean as possible. Let us start by considering the purist solution, which is to fetch *all* the rows and supply them to the presentation layer, which outputs the rows in question. How do we achieve this? Well, presumably we have a structure where a presentation module must request data from it's data source, so in the presentation module we have something like this:
$collection = $source->getData();
The source defines *what* the data are, of course. In most cases a data source is just an abstraction of a particular SQL query. getData() returns an collection, because after all, we are requesting a (possibly empty) collection of data.
So now the presentation layer is about to begin it's work, what we in a PagedPresentation would expect is something like this:
So does this interface make sense? It does IMO, and it can be implemented in a fashion that makes it as efficient as a solution which supplies the offset and the number of items per page at an earlier stage. Why? Because we don't have to actually perform the query until the data are accessed, and they aren't really accessed until applyTemplate() is called! In this case range() is a selection utility which defines a certain subrange of the collection, but it doesn't really have to do it, nor does $source need be an actual query result, they are just a facade designed to make the interface coherent and highly reusable, the implementation can be made as efficient as possible using any trick in the book.
So let me stress that this was the *implementation* of PagedPresentation, to use PagedPresentation we would expect an interface like this:
$source = new DataSource('SELECT ALL RED CARS FROM 1998');
$presentation = new PagedPresentation($source, $templateFile, $itemsPerPage);
$presentation->display();
All highly simplified, of course.
Well, umm, that may ring your bell (ding dong), but it sounds like *dung* to me.
A part of your solution is Object Oriented but I have some considerations: Tables are part of a database, your approach only leaves room to work with one database.
Wrong. Each class constructor provides a database name along with the table name, and each call to my db_connect function passes this in as $this->dbname. It is therefore possible to access multiple databases in the same application, which I do quite regularly, or even in the same transaction, which I do almost as regularly.
If you create a database class (as in: $db = new dataBase('server', 'username', 'password') you could have your table class make use of this dataBase class as in $table = new table($db). Then you can distanciate yourself from the whereabouts of the tables and only worry about their data.
What would be the benefit in that?
Considering your getData() - this requires you to have insight into the inner mechanics of your class (you have to set your desired pagesize, and you have to go through trouble if you don't want to get the standard subsequent pages, set by pagesize).
You do not need to know the mechanics of the class, just the fact that there is a variable called $rows_per_page. If you can't be bothered to set it then it will use the default value. If you really want to change the page size then how is it so much trouble to issue the single command $dbobject->seRowsPerPage(n)? It is hardly rocket science.
I suggest you have a method $table->getData(selection_criteria), which gives you every result there is.
No way, José I would never retrieve thousands of rows if all I wanted to display was 10. Do you have any idea how inefficient that would be?
Then you could have a method $table->getPage(selection_criteria, pagesize='defaultvalue', pagenumber='1'). (the '=' will use a defaultvalue, if you don't pass that parameter).
I could, but I won't. In my method I only need to specify pagesize and pagenumber when I actually want to change the current values. See You should use arguments, not variables for other reasons.
Now you can make a getNextPage(), getPrevPage(), ... which do what you can guess... :).
No thanks. I prefer using a single method that can get ANY page rather than multiple methods that can only get a particular page. It is simple, efficient and elegant. These are concepts that you would do well to learn.
I don't know anything about error-handling with php, ...
Now why does that not surprise me?
... but you might want to consider tying mysql-specific errors to your mysql-classes.
$results = $table->getPage(...);
if ($table->hasError())
$table->printError();
That way, with delegation (and overriding) your $db errors can be delegated to $table...
And what exactly do you find wrong with my present error handler? What does your technique do that mine does not?
I hope this has been of any help.
Absolutely no help whatsoever.
ps: This is not written out of arrogance and I don't think I know it better than anyone else. I'm just a student, and also was pondering about a nice oo-approach to php/mysql scripting.
Here's my advice (for what it's worth):
Don't give up your day job.
If you are paying for lessons then ask for your money back.
If you are teaching yourself then you need a new teacher.
If you are reading books then they are the wrong books, or they have some pages missing.
This is just a mere braindump.
It is certainly a 'dump' of some kind, but I suspect from a part of your anatomy which is nowhere near your brain.
I think I have demonstrated that by simply following the principles of OOP and by using the OO capabilities within PHP I have managed to produce software that is truly object oriented and which enables me to create new components very quickly. Most of the criticisms I have received have been along the lines of 'you must not do it that way because it breaks the rules.' What rules? There is no rule in the principles of OOP which says I *must* create a class for *this* and not for *that*. There is no rule that says I *must* use inheritance in *this* way and not *that* way. There is no rule that says I *must* use variables in *this* way and not *that* way. These 'rules' may have been formulated by various individuals to show how they personally have chosen to implement the principles of OOP, but they are in addition to the principles, not part of them. They do not identify the only way that the principles can be implemented, just one way out of a myriad of possibilities. I just happen to have chosen a different method.
My method is right for me, your method is right for you, and Tom/Dick/Harry's method is right for Tom/Dick/Harry. Provided that these different methods are capable of producing workable and maintainable software each should be allowed to exist and be judged by the results it produces rather than being slammed simply for 'being different' or 'not invented here'. As the French would say, 'Vive la Difference'. If everybody always did things the same way there would be no progress made, ever. I choose to do things differently because I have a creative streak. I choose to innovate, not imitate. I don't like relying on other people's methods when I reckon that I can do better.
Instead of reviewing my work and saying 'It is different, but it works' you have chosen 'It is different, therefore it is unacceptable'. That shows that you have closed your minds to the possibility that there may be different and better ways. Just like a religious fanatic you seem to think that your way is the only way, that yours is the only 'true' religion, and anyone who refuses to kowtow at the alter of your religion is an unbeliever, a heretic, a nonconformist and a renegade. To that charge I plead guilty.
I have met people like you before, people who take a perfectly good set of principles and make them totally unworkable by adding on layer upon layer of extraneous rules and regulations. This crowd of clowns tried to create a development infrastructure based on the 3 tier architecture, but after spending 3 man-years designing and building their monstrosity they discovered that it was taking weeks to build each live component. I took my own 2-tier infrastructure and converted it into 3-tier, and within 2 man-weeks I was able to create working components in under an hour each. So how did I manage to succeed where they had failed? Simply because I ignored their petty rules and regulations and stuck to the basic principles. I used my knowledge of the language to write code that fulfilled the principles as efficiently as possible.
You have taken this concept of orthogonality[1] too far and wandered off at a tangent. You have strayed so far from the path of righteousness that you have ended up in a place which is sticky, smelly and downright unpleasant. Yet you have the audacity to tell me that I am wrong! Pull the other one chaps, it's got bells on.
As far as I am concerned you bunch of tragicians [2] have taken a reasonable (note that I do not go so far as to say 'brilliant') concept called OOP and turned it into POOP (as in pooh, bowel movements, buffalo chips, compost, cow pats, crap, doo-doo, doggy-doo, droppings, dung, effluent, excrement, excreta, faeces, fertilizer, guano, jobbies, manure, muck, number twos, road apples, sewage, turds [3]). Your petty rules are a hindrance to productivity rather than a help, so I suggest you take them away and flush them down the toilet where they belong. Instead of being OOPers you are POOPers [4].
In his article Object Oriented Programming Oversold! the author devotes a section to Cult Oriented Programming in which he identifies two types of zealotry - ideological and practical. The ideological zealot will follow a methodology to the letter without regards to the effect it has on the result ('I have followed all the rules therefore it cannot be wrong!') whereas the practical zealot will use his skills and abilities to get the best results in the shortest possible time, even if it means ignoring any aspects of the methodology that get in the way. I prefer to worship at the alter of pragmatism, not dogmatism.
Computer programming is an art, not a science, therefore you will never be any good unless you have some artistic skill. The purpose of all these different methodologies with their different rules is to offer the budding artist a sort of 'painting by numbers' kit. A true artist will quickly see beyond the limitations of any particular kit and experiment with different rules, methodologies and techniques in order to produce a bigger, better and brighter picture. Those without any worthwhile talent will struggle blindly along and complain 'I am following all the rules, so why is the result not very good?'
It I were to write my code according to your rules then I would be no better than you. But I believe that your best is simply not good enough, not by a long chalk, and rather than work down to your level I prefer to seek better ways. The only way to improve something is to try a different approach, a different angle, a different way. Inevitably this means adopting a different set of rules. I have been disregarding other people's views of 'best practice' for over 20 years and I have regularly and consistently produced work of a higher quality. I see no reason to take any of your advice and reverse that trend. My long experience has given me the ability to tell the difference between excellent and excrement, between magic and tragic, so I know which category your advice falls into.
In general I think it takes something like 10 years to become a good programmer .....
I've been working with OO for something like 5 years, so I feel that I have a fairly good grasp on it.
So by your own admission you are only halfway there. Or does it mean that you are only half as good as you think you are?
Of course, there's also a bit of designer's gut-feeling here.
I have been designing and building software for over 25 years and I have learnt to tell the difference between something that works and something that fails, something that aids productivity and something that obstructs it. I may only have been programming with objects for a relatively short time, but I have been programming with components (which are not that much different) for the past 10 years. I found it relatively easy to take a successful design from my previous component-based development language and implement it equally successfully in PHP using OOP techniques. It is not just my gut that tells me that the infrastructure I have created is a neat piece of work, it is the fact that I have used it to create over 200 components which deal with a wide range of database structures (one-to-many, many-to-many, even tree structures). I can create new components faster than most people can draw their silly UML diagrams. For example, I can create a database table and write a family of six components (list, search, add, update, enquire, delete) in under a hour, making an average of one component every 10 minutes. Can you match that?
I regard myself as a well-rounded 'software engineer' and therefore a breed apart from most of today's narrow-minded OO programmers who have only been taught one discipline, and judging by the comments I have received regarding my article, taught very badly at that. I am only interested in building practical solutions to real-world problems, not in playing around with impractical theories which have been misinterpreted and mangled beyond all recognition. In the story The Engineer vs the IT Consultant I always side with the engineer's point of view, not the IT nerd.
If you think my ideas and views are total rubbish then don't bother to try out my sample forms which are documented in A Sample PHP Application. And please don't bother to run them online from here or download the code from here as you won't like what you see. The fact that it works, and works rather well thank you very much, should be irrelevant to people who are quite content in writing crap code provided that it follows all their stupid rules and regulations.
Here endeth the lesson. Don't applaud, just throw money.
 One thing that really annoys me about articles and tutorials on OOP that I have found on the web and in books - they all talk about creating a class called 'shape' with various subclasses for 'square', 'circle', 'triangle' etc. This is of absolutely no use when I want to build a system to deal with real-world objects such as 'customer', 'product' and 'sales' which have corresponding database tables. This has often led me to believe that OOP is therefore unsuitable for building common-or-garden business systems as it appears to have been designed for nothing but graphical applications.
One thing that really annoys me about articles and tutorials on OOP that I have found on the web and in books - they all talk about creating a class called 'shape' with various subclasses for 'square', 'circle', 'triangle' etc. This is of absolutely no use when I want to build a system to deal with real-world objects such as 'customer', 'product' and 'sales' which have corresponding database tables. This has often led me to believe that OOP is therefore unsuitable for building common-or-garden business systems as it appears to have been designed for nothing but graphical applications.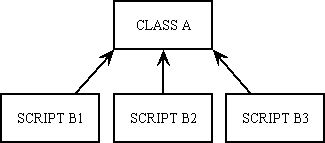
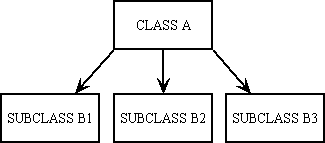
 As this so-called 'rule' regarding encapsulation and public variables has been proven to be totally without merit I do not see that it is a rule worth following. It is a non-rule. It has ceased to be. It is deceased. It is defunct. It has met its demise. It has expired. It has become extinct. It has snuffed it. It has gone belly-up. It has passed away. It is bereft of life. It is a late rule. It is an ex-rule. It does not exist. It has bought the farm. It has been deep-sixed. It has departed this life. It has popped its cloggs. It has kicked the bucket. It has shuffled off this mortal coil. It is pushing up daisies. It has gone to meet its maker. It has joined the celestial choir. It has been carried away by the Grim Reaper. R.I.P.
As this so-called 'rule' regarding encapsulation and public variables has been proven to be totally without merit I do not see that it is a rule worth following. It is a non-rule. It has ceased to be. It is deceased. It is defunct. It has met its demise. It has expired. It has become extinct. It has snuffed it. It has gone belly-up. It has passed away. It is bereft of life. It is a late rule. It is an ex-rule. It does not exist. It has bought the farm. It has been deep-sixed. It has departed this life. It has popped its cloggs. It has kicked the bucket. It has shuffled off this mortal coil. It is pushing up daisies. It has gone to meet its maker. It has joined the celestial choir. It has been carried away by the Grim Reaper. R.I.P. In 1999 I joined a
In 1999 I joined a 
 As far as I am concerned you bunch of tragicians
As far as I am concerned you bunch of tragicians {kind=link}