
What is Domain Driven Design (DDD)? If you read this Wikipedia article, which is based on the contents of Domain-Driven Design Reference (PDF) which was written by Eric Evans, you will see that it talks about DDD consisting of a number of high-level concepts and practices such as those which I have itemised in Table 1 below:
| Feature | My implementation | |
|---|---|---|
| 1 | DDD is against the idea of having a single unified model; instead it divides a large system into bounded contexts, each of which have their own model. | Refer to A system of subsystems |
| 2 | The structure and language of software code (class names, class methods, class variables) should match the business domain. For example: if software processes loan applications, it might have classes like "loan application", "customers", and methods such as "accept offer" and "withdraw". | Refer to Class names
Refer to Method names Refer to Class variables |
| 3 | Domain-driven design is based on the following goals:
|
Refer to A separate class for each table |
| 4 | Of primary importance is a domain of the software, the subject area to which the user applies a program. Software's developers build a domain model: a system of abstractions that describes selected aspects of a domain and can be used to solve problems related to that domain.
These aspects of domain-driven design aim to foster a common language shared by domain experts, users, and developers - the ubiquitous language. The ubiquitous language is used in the domain model and for describing system requirements. Ubiquitous language is one of the pillars of DDD together with strategic design and tactical design. |
Refer to domain
Refer to ubiquitous language Refer to Abstraction |
| 5 | In domain-driven design, the Domain layer is one of the common layers in an object-oriented multi-layered architecture. | Refer to A layered architecture |
| 6 | Domain-driven design recognizes multiple kinds of models:
|
Refer to Object classification |
| 7 | Models can also define events (something that happened in the past). A domain event is an event that domain experts care about. Models can be bound together by a root entity to become an aggregate. Objects outside the aggregate are allowed to hold references to the root but not to any other object of the aggregate. The aggregate root checks the consistency of changes in the aggregate. Drivers do not have to individually control each wheel of a car, for instance: they simply drive the car. In this context, a car is an aggregate of several other objects (the engine, the brakes, the headlights, etc.). | Refer to Domain events
Refer to Aggregates Refer to Compositions |
| 8 | In domain-driven design, an object's creation is often separated from the object itself.
|
Refer to Repositories
Refer to Factories |
| 9 | A bounded context is analogous to a microservice. In software engineering, a microservice architecture is an architectural pattern that arranges an application as a collection of loosely coupled, fine-grained services, communicating through lightweight protocols. One of its goals is to enable teams to develop and deploy their services independently. This is achieved by creating components which exhibit loose coupling instead of tight coupling. | Refer to Coupling
Refer to Loose coupling (good) Refer to Tight coupling (bad) |
| 10 | Although domain-driven design is not inherently tied to object-oriented approaches, in practice, it exploits the advantages of such techniques. These include entities/aggregate roots as receivers of commands/method invocations, the encapsulation of state within foremost aggregate roots, and on a higher architectural level, bounded contexts.
As a result, domain-driven design is often associated with Plain Old Java Objects and Plain Old CLR Objects, which are technically technical implementation details, specific to Java and the .NET Framework respectively. These terms reflect a growing view that domain objects should be defined purely by the business behavior of the domain, rather than by a more specific technology framework. Similarly, the naked objects pattern holds that the user interface can simply be a reflection of a good enough domain model. Requiring the user interface to be a direct reflection of the domain model will force the design of a better domain model. |
Refer to A separate class for each table
Refer to Inheritance Refer to Subclassing Refer to Aggregates Refer to Compositions Refer to Class hierarchies |
| 11 | While domain-driven design is compatible with model-driven engineering and model-driven architecture, the intent behind the two concepts is different. Model-driven architecture is more concerned with translating a model into code for different technology platforms than defining better domain models.
However, the techniques provided by model-driven engineering (to model domains, to create domain-specific languages to facilitate the communication between domain experts and developers,...) facilitate domain-driven design in practice and help practitioners get more out of their models. Thanks to model-driven engineering's model transformation and code generation techniques, the domain model can be used to generate the actual software system that will manage it. |
Refer to A standard design process |
| 12 | Command Query Responsibility Segregation (CQRS) is an architectural pattern for separating reading data (a 'query') from writing to data (a 'command').
Commands mutate state and are approximately equivalent to method invocation on aggregate roots or entities. Queries read state but do not mutate it. While CQRS does not require domain-driven design, it makes the distinction between commands and queries explicit with the concept of an aggregate root. The idea is that a given aggregate root has a method that corresponds to a command and a command handler invokes the method on the aggregate root. The aggregate root is responsible for performing the logic of the operation and either yielding a failure response or just mutating its own state that can be written to a data store. The command handler pulls in infrastructure concerns related to saving the aggregate root's state and creating needed contexts (e.g., transactions). |
Refer to CQRS |
| 13 | Event sourcing is an architectural pattern in which entities track their internal state not by means of direct serialization or object-relational mapping, but by reading and committing events to an event store.
When event sourcing is combined with CQRS and domain-driven design, aggregate roots are responsible for validating and applying commands (often by having their instance methods invoked from a Command Handler), and then publishing events. This is also the foundation upon which the aggregate roots base their logic for dealing with method invocations. Hence, the input is a command and the output is one or many events which are saved to an event store, and then often published on a message broker for those interested (such as an application's view). Modeling aggregate roots to output events can isolate internal state even further than when projecting read-data from entities, as in standard n-tier data-passing architectures. One significant benefit is that axiomatic theorem provers are easier to apply, as the aggregate root comprehensively hides its internal state. Events are often persisted based on the version of the aggregate root instance, which yields a domain model that synchronizes in distributed systems through optimistic concurrency. |
Refer to Object Relational Mappers
Refer to Aggregates Refer to Compositions |
Although domain-driven design does not depend on any particular tool or framework, there are various open source frameworks available which can help design the data model and possibly offer code generation abilities. RADICORE is an open source framework specifically designed to help build and then run web-based database applications for the enterprise which are also known as Enterprise Applications.
A more detailed definition can be found on this wikipedia page.
In a large system which is comprised of a number of small subsystems, is the system a single domain, or is each subsystem a separate domain?
If each bounded context is a separate subsystem it means that the users of each subsystem may use terminology or jargon which is unknown to users of other subsystems. While this may be important in the design phase to help ensure that it meets the requirements of its users it should have no effect on the implementation as software engineers have their own jargon.
According to the wikipedia page a bounded context is analogous to a microservice.
In software engineering, a microservice architecture is an architectural pattern that arranges an application as a collection of loosely coupled, fine-grained services, communicating through lightweight protocols. One of its goals is to enable teams to develop and deploy their services independently. This is achieved by reducing several dependencies in the codebase, allowing developers to evolve their services with limited restrictions, and hiding additional complexity from users. Consequently, organizations can develop software with rapid growth and scalability, as well as use off-the-shelf services more easily.Services in a microservice architecture are often processes that communicate over a network to fulfill a goal using technology-agnostic protocols such as HTTP.
A microservice is not a layer within a monolithic application (for example, the web controller or the backend-for-frontend). Rather, it is a self-contained piece of business functionality with clear interfaces, and may, through its own internal components, implement a layered architecture.
As explained in Designing Reusable Classes this leads to a style of programming known as programming-by-difference in which you define the similar in some sort of reusable module and the different in a unique module which has some sort of communication with the similar module. For example, if you have several entities which share the same protocols (methods) you can define those methods in an abstract class which can then be inherited by every concrete class.
This topic is explained in more detail in The meaning of "abstraction".
While working for various software houses where our job was to design and build bespoke systems for our clients I became very familiar with the steps needed to convert a set of requirements into a working system. Regardless of the business area involved - order processing, invoicing, stock control, shipments, timesheets, etc - these steps were always the same.
One the design has been signed off by the customer, meaning that they are satisfied that it will meet their requirements, the designers can produce an implementation schedule which shows the projected start and end dates for each piece of work. Resources for each piece can also be identified and costed. As each piece of work is completed, the actual dates can be compared with the planned dates to see if the project is on schedule, ahead of schedule or, more often than not, behind schedule.
The gather-analyse-design cycle is undertaken without reference to what structure the software will finally take as that is nothing more than an implementation detail. It is vitally important that the designer(s) know what needs to be done before they start defining how it can or will be done. The design of the database is far more important than the design of the software, or, as Eric S. Raymond wrote in his book The Cathedral and the Bazaar:
Smart data structures and dumb code works a lot better than the other way around.
The objective of the gather-analyse-design cycle is to avoid the situation depicted in the following cartoon:
This is why it is vitally important that the customer provides detailed and exact descriptions of their needs. Anything which is assumed or implied must be converted into an exact, precise and unambiguous statement so that if an issue arises as a later date it can be traced backwards through UAT, the design phase, all the way up to the SRS/SOR.
Those developers who are taught OO theory before they have any experience in working with databases can very easily fall into the trap of assuming these OO theories were carved in stone by some god-like beings and brought down from the mountain top. I have examined lots of these theories, and I can see very little evidence that the authors have ever worked on an enterprise application with large numbers of database tables and input/output screens, so I take everything they say with a pinch of salt (and sometimes a bucket of disinfectant and a scrubbing brush). Refer to Advice which I ignore for details.
I have been designing and building enterprise applications for four decades, with the last two being dedicated to web-based enterprise applications using an object oriented language, and I do not follow the "advice" given in Domain Driven Design. I say "advice" because I cannot accept them as "rules which must be obeyed".
When I started programming with COBOL it was standard practice to use the monolithic 1-Tier architecture, then when I switched to UNIFACE I was exposed to first the 2-Tier and then the 3-Tier Architecture which has the following layers:
When I switched to PHP I decided to keep using the 3-Tier Architecture, but because I separated out the construction of all HTML documents into a separate component in the Presentation layer I discovered that I had also implemented the Model-View-Controller (MVC) design pattern, but this was by accident, not by design (pun intended). This has the following components:
The combined architecture is shown in Figure 1 below:
Figure 1 - MVC plus 3 Tier Architecture
")
Objects in the RADICORE framework fall into one of the following categories:
An Entity's job is also mainly holding state and associated behavior. Examples of Entities could be Account or User. In a database application each table is a separate entity in the database, with its own business rules, so its methods and properties should be encapsulated in its own class. That class will typically have several public methods which allow the state to be loaded, updated and queried.
Entities will exist as objects in the Business layer shown in Figure 1 above.
A Service performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). It usually performs its operation on data obtained from an entity. Examples of Services could include a parser, an authenticator, a validator and a transformer. The class for a service will typically have a single public method so that it will produce a single output from a single input.
Services will exist as objects in the Presentation and Data Access layers shown in Figure 1 above, but there may also be some in the Business layer.
While Value Objects may exist in other languages they do not exist in PHP. Instead all variables/properties are held as primitive data types (aka scalars).
The components in the RADICORE framework fall into the following categories:
It should also be noted that:
When I started to use PHP with its OO capabilities it was obvious to me that I would need to use a layered architecture and that I would need a separate class/object in the Business layer for every entity that was of interest to the business. By the time the implementation stage is reached all these entities have been identified as tables in the database. This is why I create a separate class for each table. This simple practice leads to the following:
The idea of creating a separate class for each database table is actually recommended in the principle of Information Expert (GRASP) which states the following:
Assign responsibility to the class that has the information needed to fulfill it.
I interpret "responsibility" to mean code and "information" to mean data, so because each database table is responsible for a different set of data it follows that I should have a separate class to control access to that data, and that class should also contain all the methods which can act upon that data.
Note that while some programmers regard aggregates or compositions, which deal with several tables in a hierarchy, as being a single entity and therefore requiring its own class, I do not. I regard a single object being responsible for more than one table as being a violation of the Single Responsibility Principle (SRP).
A large system, such as an Enterprise Resource Planning (ERP) system is often comprised of a number of interconnected subsystems. If they are built using the same framework or toolset then a user will be able to move through one subsystem to another without noticing the difference.
The RADICORE framework itself is comprised of four subsystems:
Each subsystem has its own database, its own directory in the file system for all its files, and its own entries in the MENU database.
A single logon screen gives access to all these subsystems which makes them appear as one unified system.
Additional application subsystems can be developed as add-ins whenever the need arises. For example, the GM-X Application Suite contains the following subsystems:
Each of theses subsystems is optional so that client organisations need only pay licence fees for those subsystems they actually need. They are also customisable as the RADICORE framework has built-in facilities which allow different screen and report layouts to be supplied at runtime, and even different versions of the business logic for individual table classes.
If the definition of a domain is A sphere of knowledge and activity around which the application logic revolves
does it mean that in a large system which is comprised of a collection of smaller subsystems that the system is the domain, or is each subsystem a separate domain? If each subsystem is a separate domain then this would imply that each would require its own separate and unique design process. In this I would have to disagree. While each of the subsystems mentioned previously has its differences there are also a large number of similarities.
When a novice looks at the requirements for different subsystems/domains he/she should immediately notice that there are significant differences, such as the following:
While those differences appear to be significant an experienced developer will be be able to spot areas in the eventual implementation which are similar enough to be satisfied by reusable modules. Among these similarities are the following:
There are also some similarities which are common to each domain which can be supplied from a single central source, commonly known as a framework, such as:
An event is something that happened which caused an entity to change its state. An event is triggered by a user by activating a task (user transaction) which changes the state of one or more entities.
Eric Evan's article Domain-Driven Design Reference has this to say on the subject:
An entity is responsible for tracking its state and the rules regulating its lifecycle. But if you need to know the actual causes of the state changes, this is typically not explicit, and it may be difficult to explain how the system got the way it is. Audit trails can allow tracing, but are not usually suited to being used for the logic of the program itself.
...
Domain events are ordinarily immutable, as they are a record of something in the past. In addition to a description of the event, a domain event typically contains a timestamp for the time the event occurred and the identity of entities involved in the event. Also, a domain event often has a separate timestamp indicating when the event was entered into the system and the identity of the person who entered it.
The RADICORE framework deals with this "requirement" in the following ways:
Note also that there may be business rules which identify which status changes are valid and which are not, or that certain status changes can only be performed by users with the appropriate level of security (which are known as ROLES in the framework).
My standard practice is to create a separate Model class for each entity in the Business/Domain layer, which equates to a separate class for each table in the database. I do not play around with object aggregations or object compositions.
Once the logical design has been completed and the database has been designed, with all its tables and columns, I then proceed to use my Data Dictionary to build the subsystem's class files to mirror the database structure. I import each table's structure into the Data Dictionary, adjust the details if necessary, then export them into the file system. This function will produce the following files in the <document_root>/<subsystem>/classes directory:
This technique makes it very easy, should the need arise, to change the structure of a table, then redo the import/export process to recreate the <tablename>.dict.inc file. The <tablename>.class.inc file is never overwritten as it may have been amended to include some "hook" methods. Because no table names or columns names are built into any APIs there is no ripple effect by such a change.
This is in contrast to suggestions which I ignore.
As each entity in the business/domain layer exists in the outside world as a database table, and each table, regardless of its contents, is subject to exactly the same set of CRUD operations, it made sense to me to translate each of there operations into equivalent methods which are as follows:
These are documented in common table methods. Note that for each of these operations the identity of the database table in question will be obtained from the $tablename property within that table's object.
Because each table class has exactly the same method signatures this provides a significant amount of polymorphism which I can utilise using that mechanism known as dependency injection. This is why I ignore DDD's "suggestions" for method names as they destroy any hope of polymorphism and the reusability which it provides.
These are also known as properties, and in a database application there is usually one for each column in the database. It is usual practice to give each of these properties the same name as its column as to do otherwise would lead to confusion.
These properties can be accessed either directly or using getters and setters (also known as accessors and mutators):
| Access | Directly | Indirectly |
|---|---|---|
| Writing | $object->foo = 'bar'; | $object->setFoo('bar'); |
| Reading | $foo = $object->foo; | $foo = $object->getFoo(); |
Note that is also possible to specify these properties as arguments on a method/function call.
For reasons explained in Getters and Setters I do not have a separate property for each column as that produces tight coupling. I prefer to pass all column data around as a single $fieldarray argument as that produces loose coupling which in turn produces components which are more reusable.
Inheritance is a method of sharing code whereby a subclass can share the methods and properties of a superclass. The subclass may override (modify) any of the inherited methods, it may add new methods of its own, but it cannot remove or "un-inherit" any of those methods. A superclass may be inherited by any number of subclasses.
While building a small sample application as a prototype before building the RADICORE framework I had decided to create a separate class for each database table. After creating another class for a second table I noticed a great deal of duplicated code, so I decided to move this code to an abstract table class so that it could be inherited by every concrete table class. I ended up with lots of code in the abstract class, namely a set of common table methods and a set of common table properties, and nothing in each concrete class except for the constructor. Notice that unlike some developers who employ separate methods such as load(), validate() and store() I learned back in by COBOL days that when a group of functions always had to be called in a specific sequence that it was more efficient to put that group into separate function which could act as a wrapper, thus replacing several functions calls with a single call.
While the abstract class could provide all the standard code required by each concrete class, even the primary validation, it quickly became obvious that I sometimes needed to inject some non-standard code into the processing sequence for certain user transactions. My knowledge of inheritance told me that I could add some calls to some dummy methods within the existing wrapper methods in the abstract class which I could then override in any concrete subclass. These dummy methods were defined in the abstract class but did nothing, but if they were redefined in a subclass then they could be programmed to do whatever was necessary in that subclass. I discovered later that I had actually implemented the Template Method Pattern and that my dummy methods were called "hook" methods.
When I was later informed that I should be using composition instead of inheritance I thought it was a joke as nobody could explain why inheritance was bad and why "object composition", whatever it was, was supposed to be better. Nobody could supply me with any examples which demonstrated that what I had achieved with inheritance could be better achieved with "object composition". I later discovered that the so-called "problems" with inheritance were caused by inheriting from one concrete class to create a different concrete class which meant that some of the inherited methods could be completely inappropriate for the subclass. As I never encountered any of these "problems" I saw no reason to stop using inheritance. I later read in the Gang of Four (GoF) book on design patterns that the recommended way to avoid problems was to only ever inherit from an abstract class. This meant that what I had been doing all along was correct and that it was everybody else that was wrong.
My principle of creating a separate class for each database table was a step in the right direction as it enabled me to share the common methods and properties by inheriting them from an abstract class. As I now have a single set of methods which are shared by hundreds of subclasses this produces a large amount of polymorphism which I can utilise using dependency injection in my library of reusable Controller scripts. The abstract class has also enabled me to use the Template Method Pattern so that I can easily inject custom code into any table subclass.
As far as I am concerned inheritance has provided me with zero problems and bucket loads of benefits.
It is quite possible that it some circumstances you may wish to perform some processing in a particular hook method for a particular task that is totally different from the code used in the same method for a different task. In this situation I use a standard OO technique called subclassing. I create a subclass of the table class with a name such as <table>_sNN where "s" denotes a subclass and "NN" is an incrementing number. This automatically inherits all the methods in the superclass but allows me to override any of those methods with a different implementation. Note that the subclass deals with the same table as the superclass, it just provides different business rules for that table. I then change that task's component script to point to this subclass. You can see working examples of this in the Data Dictionary subsystem of the framework where you will find the following class files:
In my early days as a developer when I was working with COBOL it was common practice to create a program called "Maintain XXX" where "XXX" was a particular entity (table) which was of interest to the business. This could handle all the CRUD operations which could be performed on that entity, so it needed a mechanism to switch from one operation to another. A typical set of operations was List, Create/Add, Read/Enquire, Update and Delete where each had its own screen and its own business logic. The difference between "List" and "Read" is that "List" can display multiple rows on the screen whereas "Read" (and all the others) can only deal with one row at a time. We called each of there operations a "mode" and had function keys (with labels) on the each screen so the user could switch from one mode to another. The program would always start in "List" mode, and the functions for the other modes were always available.
This practice was continued until the mid-1980s when a customer came up with the requirement for access to individual modes to be denied to certain users, and for the function labels to disappear when access was denied. This had be configurable on the database rather than in code so that it could be modified more easily. Creating a new database table, then modifying the code to act upon the contents of this table proved to be rather tricky, so after a while I decided that the best solution would be to break apart each multi-mode/multi-screen program and create a separate sub-program for each mode. This meant that instead of a large complex program I ended up with a collection of smaller but simpler subprograms each of which dealt with a single mode and a single screen. This resulted in the structure shown in Figure 2 below:
Figure 2 - A typical Family of Forms
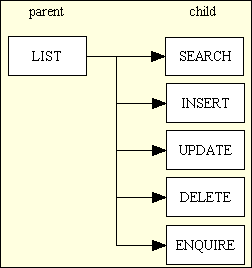
In this collection, which I now call a "family" because of the parent-child relationships, The LIST1 form is usually activated from a menu button, although the LIST2 variant is usually activated from a navigation button. All the child forms are activated from navigation buttons. This means that the user has to go through the parent form in order to get to a child form. The advantage of having all the members of this family being separate tasks (user transactions) with their own entries on the TASK table is that their positions in any menu bar or navigation bar is not hard-coded, it is completely dynamic. The features of the Role Based Access Control (RBAC) system which is built into the framework means that access to individual members of the form family can be turned ON or OFF at will without the need for any code changes.
An additional advantage of having a separate component for each member of the forms family, coupled with the fact that each Model (table) class shares the same set of common table methods, thus providing polymorphism, is that once a Controller has been built to perform a series of method calls on its table class(es) it can be made to call exactly the same methods on a different table class through that mechanism known as dependency injection. This mechanism means that each Controller script can be used with any table class.
It should also be noted that in aggregate compositions I do not have a single class for the aggregate to handle all the use cases (user transactions) for that aggregate. No matter how many tables are in that aggregate all I see are a number of pairs of tables which are joined in a parent-child relationship, and each pair is dealt with using its own family of forms.
Please also refer to Transaction (use case) similarities and Transaction (use case) differences.
Before I started using the OO capabilities of PHP I asked myself "why I should bother? What's so great about OOP?" I found the answer in the following statement:
Object Oriented Programming involves programming which is oriented around objects, thus taking advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
This rang a bell with me as the frameworks which I had developed in my two previous languages had helped increase the productivity of the whole development team by replacing the need to write chunks of identical or similar code with pre-written and reusable code. The less code you have to write to get the job done then the less time it takes to get the job done and the more productive you can be. I therefore set out to use these features of PHP to increase as much as possible the amount of reusable code I could have at my disposal.
While using a layered architecture is a step in the right direction, it is how you construct each of the different components in that architecture which indicates if you are taking proper advantage of the features which OOP has to offer. By following my own version of "best practices", and ignoring those which have a dubious pedigree, I have been able to provide the following amounts of reusability which help reduce development times and increase my rate of productivity:
| Models | Each table class inherits all its standard code from a single abstract table class while any non-standard code can be inserted into the available "hook" methods. |
| Views | There is a single reusable component for each type of View:
|
| Controllers | Each of the reusable Controllers calls a predetermined series of methods on an unknown Model (or Models) where the identity of those Model(s) is passed down at run time from a component script. There is a separate version of this script for each user transaction (task). Each Controller is paired with no more than one View, as documented in Transaction Patterns, but there are some which have no View at all. |
| DAOs | Each of the reusable Data Access Objects generates the queries for the common CRUD operations for a particular DBMS. Each method will build its query based on the information passed to it by the Model, then call the API which is specific to that DBMS. |
You should notice here that every Model class supports the same set of methods as every other Model class, and every Controller communicates with its Model(s) using those methods. This is a prime example of polymorphism, and it allows any Model to be used with any Controller.
You should also notice that as much standard code (often referred to as boilerplate code) as possible is supplied by the framework, which means that the bulk of the developer's time can be spent on the important code which deals with the business rules.
While DDD contains many principles and practices, I regard these as "suggestions" and not "rules", which means that I am free to either follow them, in whole or in part, or ignore them altogether. Where I find a simpler way to achieve an objective then I will follow the KISS principle and ignore the KICK alternative.
While some of these topics are not explicitly mentioned as being part of DDD I have included them because they are part of the OO family of practices and therefore may be implied.
When I first encountered the term association in various newsgroup postings all I saw was a complicated way of dealing with relationships. It does not matter to me how many tables are linked together in a hierarchy, that hierarchy is nothing more than a collections of tables where different pairs of tables are linked together in a parent-child relationship, and each relationship can be dealt with by standard code in the framework and not custom code in any table class.
You can read more of my thoughts on this topic in Object Associations are EVIL.
OO afficionados like to use the "HAS-A" test to help them recognise things called "object compositions". The wikipedia article contains the following description:
Has-a is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership. In simple words, has-a relationship in an object is called a member field of an object. Multiple has-a relationships will combine to form a possessive hierarchy.
An Aggregation implies that the contained class can exist independently of the container. If the container is destroyed, the child is not destroyed as it can exist independently of the parent.
It does not matter to me how many objects are linked together in some sort of hierarchy, at the end of the day it is just a collection of tables which are arranged in a number of one-to-many/parent-child relations, and in the RADICORE framework there are standard patterns for dealing with parent-child relationships which do not require any custom code in any table class.
I have written more on this topic in Object Associations - Aggregations and A single class for an Aggregation is a mistake.
A Composition is a type of aggregation in which the contained class cannot exist independently of the container. If the container is destroyed, the child is also destroyed.
I have written more on this topic in Object Associations - Compositions.
There is a different type of composition which is supposed to be an alternative to inheritance which I have written about in Composition is a Procedural Technique for Code Reuse.
I have seen where more than a few developers use the "IS-A" test to identify the existence of class hierarchies. They make statements such as "a CAR is-a VEHICLE", "a BEAGLE is-a DOG" and "a CUSTOMER is-a PERSON", and this causes some developers to ask the question:
If object 'B' is a type of object 'A', then surely 'B' must be a subclass of 'A'?
This can lead to statements such as: A Car and a Train and a Truck can all inherit behavior from a Vehicle object, adding their subtle differences. A Firetruck can inherit from the Truck object, and so on.
which would produce hierarchies of classes which are multiple levels deep.
This is not how it is handled in a database, so it is not how it should be handled in the code.
Expanding on the "a BEAGLE is-a DOG" statement from above someone who has been trained to think in the "object oriented way" would identify dog_type as the differentiator and create a separate subclass for each possible value, as shown in Using "IS-A" to identify class hierarchies.
If dog_type is identified as the differentiator then it should become a column on the DOG table which can be used as the foreign key to an entry on the DOG_TYPE table. In this way it is possible to introduce as many different types of dog that you can think of without having to create a separate class for each.
In database applications every entity in the Business/Domain layer IS-A database table, and because every table shares the same CRUD operations every table class shares the same table methods which are inherited from the same abstract table class. This means that I do not have any deep inheritance hierarchies, with the only exception being when I need subclasses to deal with different implementations for the standard "hook" methods.
This is what it says in the wikipedia page:
Command Query Responsibility Segregation (CQRS) is an architectural pattern for separating reading data (a 'query') from writing to data (a 'command'). CQRS derives from Command and Query Separation (CQS), coined by Bertrand Meyer.Commands mutate state and are approximately equivalent to method invocation on aggregate roots or entities. Queries read state but do not mutate it.
This is the description for Command Query Responsibility Segregation (CQRS):
In information technology, Command Query Responsibility Segregation (CQRS) is a system architecture that extends the idea behind command-query separation to the level of services. Such a system will have separate interfaces to send queries and to send commands. As in CQS, fulfilling a query request will only retrieve data and will not modify the state of the system (with some exceptions like logging access), while fulfilling a command request will modify the state of the system.Many systems push the segregation to the data models used by the system. The models used to process queries are usually called read models and the models used to process commands write models.
The idea that I should have one model for reading and another Model for writing is unacceptable to me. As far as I am concerned this violates the principle of encapsulation which states that ALL the methods and ALL the properties for an entity should be maintained in the SAME class. This means that you do not split those methods and properties across multiple classes, nor do you put methods and properties for multiple entities in the same class.
In a database application each entity in the Business layer IS-A database table, and the only operations which can be performed on a database table are Create, Read, Update and Delete (CRUD). This is why I created a set of methods to perform these operations, and because they are common to every table I make them available in every table class by inheriting them from an abstract class.
In this paper Domain-Driven Design Reference Eric Evans wrote the following:
When creation of an entire, internally consistent aggregate, or a large value object, becomes complicated or reveals too much of the internal structure, factories provide encapsulation.
I do not use object aggregations, therefore I do not need any factories.
I do not need a method of creating objects with different configurations as each of my table objects has only one possible configuration, and that is dealt with in the class constructor.
While learning how PHP worked I saw that it was common practice to create classes with separate properties for each table column, and to access them using separate getters and setters. I did not like this idea as it would mean that each table (Model) class would require its own set of properties with their getters and setters and that each of these classes would then require its own Controller with the necessary code to access these unique properties. This would therefore make each Controller tightly coupled to a particular Model and throw out of the window any opportunity of having reusable code. I had already noticed that data being sent in from an HTML form was presented in an associative array, and that data read from the database was also presented in an associative array (actually an indexed array of associative arrays), so I decided not to unpick this array into its components parts but to pass it around in its array form as a single argument on every method call. This is shown in the common table methods as the $fieldarray argument. This simple idea provided several benefits:
Note that each table class "knows" what columns belong in its table as they are list in the $fieldspec array.
By "interfaces" I mean object interfaces which require the use of those keywords interface and implements. These did not exist in PHP4 so I could not use them. They were introduced in PHP5, but after reading their description in the manual I decided that as I was already using an abstract class to great affect I had no need for them.
I later discovered that they were added to other languages to provide a way of allowing polymorphism without inheritance in certain strictly typed languages. They were added to PHP just because some not-so-bright programmers said Other OO languages support interfaces, so PHP should support them as well.
This is a ridiculous argument as PHP is not strictly typed, nor does it require any mechanism to support polymorphism other than several classes containing the same method signatures. This means that they are totally redundant in PHP and a complete waste of time as they serve no useful purpose.
This topic is covered in more detail in the following:
I have seen many examples where method names are constructed to reflect an action which has been identified in the design process, such as "createCustomer", "SignUpForMagazineSubscription", "accept offer" and "withdraw", but I never followed this practice. My aim of switching to an OO language was to use the facilities offered by encapsulation, inheritance and polymorphism to create as much reusable code as possible. I therefore creating my own convention for naming methods.
I also knew two things from my previous experience:
This means that names such as "createCustomer", "SignUpForMagazineSubscription", "accept offer" and "withdraw" I consider to be nothing more than labels which may be beneficial to the user but which are irrelevant details in the software. By stripping away the irrelevant and concentrating on the essential I make it easy for the developer to quickly understand the effects of each user transaction and to identify the components that will produce that effect. The labels made available to users are nothing more than names held on the TASK table in the MENU database.
| OO purists | effect on the database | the Tony Marston way |
|---|---|---|
| createProduct($_POST) | insert a record into the PRODUCT table |
$table_id = 'product'; .... require "classes/$table_id.class.inc"; $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); |
| createCustomer($_POST) | insert a record into the CUSTOMER table |
$table_id = 'customer'; .... require "classes/$table_id.class.inc"; $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); |
| createInvoice($_POST) | insert a record into the INVOICE table |
$table_id = 'invoice'; .... require "classes/$table_id.class.inc"; $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); |
| payInvoice($_POST) | insert a record into the PAYMENT table |
$table_id = 'payment'; .... require "classes/$table_id.class.inc"; $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); |
In my method the value for $table_id is provided in a component script and this is instantiated into an object in the controller script.
The use of an abstract class also provides the means to have methods for standard processing interspersed with methods for custom business rules. This is called the Template Method Pattern and involves a mixture of invariant/fixed methods and variable/customisable or "hook" methods which can have different implementations in different concrete classes. Every public method in the abstract table class is an example of a Template Method.
In this paper Domain-Driven Design Reference Eric Evans wrote the following:
Query access to aggregates expressed in the ubiquitous language. Proliferation of traversable associations used only for finding things muddles the model. In mature models, queries often express domain concepts. Yet queries can cause problems. The sheer technical complexity of applying most database access infrastructure quickly swamps the client code, which leads developers to dumb-down the domain layer, which makes the model irrelevant.
I do not deal with aggregates in the DDD way.
Abstraction is a process whereby you separate the abstract from the concrete, the similar from the different, with the aim of putting the similar into a reusable object and the different into unique objects. This section identifies what I recognise as "different" and how I have isolated them from the "similar".
While each database can contain any number of tables each one will have its differences which can be categorised under the following headings:
These have been implemented as a set of common table properties which are inherited from an abstract table class. Each of these properties will be loaded in when the class file is instantiated into an object.
Having abstracted out all the similarities in every HTML document I am left with the differences. While the XSL Stylesheet contains the necessary instructions to construct all the standard elements on the HTML page I am left with the one variable which is the zone which handles the application data. This is where I have to identify which piece of table data goes where in that zone. Because I have to copy all the necessary framework and application data to an XML document I discovered, after a bit of experimentation, that I could also include a description of this application zone in this XML. This meant that instead of having a separate version of an XSL stylesheet for each different screen I could use a standard stylesheet and load data from an external screen structure file like the one shown below:
<?php // this identifies which XSL stylesheet to use $structure['xsl_file'] = 'std.detail1.xsl'; // this identifies which XML data is to go into which XSL zone $structure['tables']['main'] = 'person'; // this specifies the width of each column $structure['main']['columns'][] = array('width' => 150); $structure['main']['columns'][] = array('width' => '*'); // the following may also be used $structure['main']['columns'][] = array('class' => 'classname'); // this identifies the label and field which is to be displayed in each row $structure['main']['fields'][] = array('person_id' => 'ID'); $structure['main']['fields'][] = array('first_name' => 'First Name'); $structure['main']['fields'][] = array('last_name' => 'Last Name'); $structure['main']['fields'][] = array('initials' => 'Initials'); $structure['main']['fields'][] = array('nat_ins_no' => 'Nat. Ins. No.'); $structure['main']['fields'][] = array('pers_type_id' => 'Person Type'); $structure['main']['fields'][] = array('star_sign' => 'Star Sign'); $structure['main']['fields'][] = array('email_addr' => 'E-mail'); $structure['main']['fields'][] = array('value1' => 'Value 1'); $structure['main']['fields'][] = array('value2' => 'Value 2'); $structure['main']['fields'][] = array('start_date' => 'Start Date'); $structure['main']['fields'][] = array('end_date' => 'End Date'); $structure['main']['fields'][] = array('selected' => 'Selected'); ?>
Note that for input and update screens I will need to include for each application column the identity of the HTML control (textbox, radiogroup, dropdown, checkbox, etc) which should be used. This information is obtained from the $fieldspec array which has been loaded into the object's memory from the table structure file.
As explained in Transaction (use case) similarities each user transaction (task) will require a Model, a View and a Controller to act in unison to carry out the task required by the user.
While each subsystem will require its own set of user transactions (tasks) these can be generated by the framework by linking a table class with any of the Transaction Patterns which are supplied by the framework. Each user transaction which then have its own component script in the file system which looks like the following:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
As you can see this is a simple script whose purpose is to identify the following:
$table_id identifies the Model part of MVC. This is one of the generated database table classes.$screen identifies the View part of MVC. This is one of the generated screen structure scripts which identifies the HTML differences.include identifies the Controller part of MVC. This is one of the pre-written controller scripts.Each Controller is designed to work with only a single View, but a small number of Controllers do not have a View at all. For a complete list of the available Controllers and the Views which they support please refer to Transaction Patterns for web applications.
Note that each Controller can work with any Model, but it does not know which one until it is given a value for $table_id at run-time. It also means that each Model can work with any Controller.
Use these links for the validation similarities and validation differences.
While the similarities can be handled by a standard component within the framework it is often necessary for a particular operation on a particular table to be interrupted at a particular point in order to execute some custom code, either for some non-standard data validation or to apply a particular business rule. This can be done in the RADICORE framework by locating the relevant customisable method which has been been into the processing flow for that operation, then copying that empty method into the subclass so that it can be filled with the necessary code. Various methods are available, such as:
There are also other customisable methods with names such as the following:
_cm_pre_<operation>() - for processing "before" the operation, such as _cm_pre_insertRecord()._cm_post_<operation>() - for processing "after" the operation, such as _cm_post_insertRecord().Note that these customisable methods are available because of my implementation of the Template Method Pattern which was made possible because of my decision for all concrete table classes to inherit from an abstract table class.
Abstraction is a process whereby you separate the abstract from the concrete, the similar from the different, with the aim of putting the similar into a reusable object and the different into unique objects. This section identifies what I recognise as "similar" and how I have turned them into reusable components.
Although each database table holds different data they are all subject to exactly the same set of operations which are Create, Read, Update and Delete (CRUD). These have been implemented as a set of common table methods which are inherited from an abstract table class. Instead of having separate methods for load(), validate() and store() I have grouped them together into wrapper methods as they always have to be called in the same sequence, and it is more efficient to write a single call to a wrapper method instead of a number of calls to the low-level methods. It also makes it easier to modify the contents of a wrapper method without having to modify any code which calls that method.
The advantage of being able to inherit these methods from an abstract class is that they do not have to be defined in each concrete class as they are automatically there when the class is instantiated into an object. This is why each table class file can be generated from the same template, as shown below:
<?php require_once 'std.table.class.inc'; class #tablename# extends Default_Table { // **************************************************************************** // class constructor // **************************************************************************** function __construct () { // save directory name of current script $this->dirname = dirname(__file__); $this->dbname = '#dbname#'; $this->tablename = '#tablename#'; // call this method to get original field specifications // (note that they may be modified at runtime) $this->fieldspec = $this->loadFieldSpec(); } // __construct // **************************************************************************** } // end class // **************************************************************************** ?>
The loadFieldSpec() method is responsible for transferring the contents of the table structure file into the object's common table properties which configures the object with all the knowledge it requires so that it can deal effectively with that particular table.
Note that the table class file, when it is first created, does not contain any methods other than the constructor as all the standard processing is performed by the common table methods which are inherited from the abstract table class. The use of an abstract class enables the Template Method Pattern to be implemented. This involves the use of invariant/fixed methods to be defined in the superclass which can be interspersed with variable/customisable "hook" methods which can be overridden within each subclass to provide custom behaviour.
Communicating with a relational database is very straightforward. It is a simple matter of constructing an SQL query, which is a string of text, and sending to the database using the relevant <dbms>_query() function. There are only four basic methods for manipulating data, part of the Data Manipulation Language (DML), and they are:
The query string which is constructed for each of these operations/methods follows the same pattern regardless of what data is being processed.
| Operation | Code |
|---|---|
| Create |
INSERT INTO <tablename> (column1, column2, column3) VALUES ('value1', 'value2', 'value3');
|
| Read | simple: SELECT * FROM <tablename> [WHERE <condition>] advanced: SELECT <select list> FROM <tablename> [JOIN <tablename2> ON (...)] [WHERE <condition>] [GROUP BY ...] [HAVING ...] [ORDER BY ...] [LIMIT ... OFFSET ...] |
| Update | UPDATE <tablename> SET column1='value1', column2='value2', column3='value3' WHERE <condition> |
| Delete | DELETE FROM <tablename> WHERE <condition> |
Note that the Create, Update and Delete operations function on only one table at a time whereas the Read operation can obtain data from several tables.
As you should see the table names, column names and column values are nothing more than pieces of text which appear in the query string along with various keywords, so none of these names have to be specified in separate arguments on the function call to the DBMS. As PHP has excellent string handling functions I found it very easy to create a single Data Access Object (DAO) which can handle the generation and execution of any query for any table in any database. Each of the four methods - one for each of the above operations - is fairly basic as it responds to the instruction "take this data and construct and execute an SQL query for the DBMS". All I have is a separate DAO class for each supported DBMS (MySQL, PostgreSQL, Oracle and SQL Server) as the query strings may be similar but the function calls are not.
I have seen other people's implementations where they have a separate DAO for each table, but my method is far easier as I can add, remove or modify tables at will without having to add, remove or modify any DAOs.
Unlike in my previous languages where each screen had to be built using a special tool and then compiled, I knew that each web page was nothing more than a text file, with a mixture of tags and values, that had to be constructed from scratch before it could be sent to the client device. I also knew that I did not want to follow the examples I encountered in various books and online tutorials and build each HTML document by spitting out little fragments one piece at a time during the execution of each script.
Because in my previous languages I had built hundreds of different screens for dozens of different applications I had already begun to spot a number of similarities between them. While each screen had different values they each had a structure that was common to other screens, so I looked for a way to hold each different structure in some sort of template so that at run time all I needed to do was fill that template with values. I did not bother searching for templating systems as I had already encountered XML and XSL Transformations in UNIFACE. I played with these on my home computer and discovered that I could easily transform XML into HTML, so after confirming that PHP had the ability to create XML documents from SQL data and perform XSL Transformations, I decided to build all my web pages in this way.
For this I built a standard service object which took as its input one or more entities from the Business/Domain layer and the identity of an XSL stylesheet. Its function was to copy each entity's data into the XML document, add various framework data into that document, load the nominated XSL stylesheet into memory, then perform the XSL transformation. The output from this process was then sent to the client device. In my initial version, which is described in Generating dynamic web pages using XSL and XML, I had a separate XSL stylesheet for each screen as I had to specify which piece of data went where. After some experimentation and refactoring I found a way to replace these custom-built XSL stylesheets with a smaller collection of Reusable XSL Stylesheets and Templates which make use of a separate screen structure file to identify which piece of application data goes where.
The areas of each web page which area common and can be supplied by the framework without any intervention by the developer are as follows:
Each screen has its own Data area which is supplied by each table class.
I had observed earlier that after building a user transaction which did something to a particular database table that I often needed to produce another transaction which did the same thing to a different table. On closer examination I was able to split each transaction into three categories - structure, behaviour and content - where the structure and behaviour were the same with just the content being different. I first documented this idea from my experience with Component Templates in UNIFACE which, for my PHP implementation, I later updated to What are Transaction Patterns? This collection of patterns works as follows:
Note that each screen structure is documented in the RADICORE library of Transaction Patterns for web applications where it is coupled with a reusable Controller script to provide a standard pattern for user transactions (tasks). Note that any Controller script can be used with any Model (table) class as they all use the same set of common table methods. This provides vast amounts of polymorphism which is a vital ingredient of Dependency Injection.
Note that when I use the word "transaction" I mean user transaction (to differentiate from a database transaction). In the RADICORE framework I also use the name "task" (because it's nice and short) as details of each task are stored in the framework's TASK table.
Using the structure shown in Figure 1 it follows that every task in the system will need one component from each of those component types, and each of these components will be provided from different sources as follows:
Note that it does not matter how much data is submitted on the HTML form or what the column/field names are, it is all made available in the $_POST variable which is an associative array. In order to remove the need for code to deconstruct this array and feed in the data one piece at a time, which would automatically produce tight coupling, I leave this array intact as pass it around as a standard $fieldarray argument on all method calls, as shown in common table methods.
Note that a particular Controller scripts and a particular View are paired together to form a Transaction Pattern.
The identity of each of these components is documented in the Transaction (use case) differences.
Each of these user transactions (tasks) will require entries in the framework's MENU database as follows:
Each user of the system will require the following entries in the framework's MENU database:
It is only necessary to construct one set of Menus and Navigation buttons as it is a function of the Role Based Access Control (RBAC) software which is built into the framework to filter out any task to which the user does not have access. If the user cannot see a button to activate the task then it cannot be activated.
Use these links for the similarities and differences in the validation and business rules.
There is one universal rule that every developer SHOULD follow when writing software which takes input from a user and adds it to the database and that is to check that each piece of data is compatible with its column specifications BEFORE it is sent to the database otherwise the query will not execute and the software will come to a grinding halt. The correct behaviour is to check each column's value against its specifications, and if this check fails in any way it should be sent back to the user with a suitable error message so that the mistake can be corrected so that the operation can be tried again.
Because this is a universal requirement it should be possible to perform this checking in a standard component. This can be done within the RADICORE framework because of two simple design decisions:
Note that the use of separate class properties for each column leads to tight coupling (which is bad) whereas a single array property leads to loose coupling (which is good)
The existence of these two arrays then makes it a simple process to write a standard validation object which can compare the contents of the two arrays to verify that each column's value matches its specifications.
I have designed and built numerous enterprise applications from scratch using totally different languages over several decades, so I have more than a passing knowledge of the steps which are required to undertake such a task. The iterative Gather-Analyse-Design cycle is always the same, it is only the results of those iterations, the database design, the business rules, and the tasks required to maintain the contents of that database which are different. The deciding factors for a successful implementation are always the same - the accuracy of the design closely followed by the ability of the development team to implement this design using the tools at their disposal. These tools will include the programming language, the DBMS, the code editor, the debugger, and the framework. If any of these is not up to par - either the design, the developers or the development tools - then the result will also not be up to par.
An experienced developer should realise that, despite the differences in the databases, every table is subject to exactly the same operations and can therefore be handled in the same way. Despite the differences in the business rules they can all be handled in the same way. Because these differences can be handled in similar ways it should be possible to reduce these patterns of similarities into reusable code.
I have encountered numerous formalised design methodologies over the years, but neither I nor my fellow developers could ever be persuaded to commit ourselves 100% to a single methodology. We have always chosen the pick-and-mix approach whereby we picked the parts that we liked, ignored the parts that we didn't like, and mixed them together in a way that suited us. I particularly dislike those parts of DDD which are biased towards the way that OO thinkers are taught to build their solutions, such as associations, aggregations, compositions, factories and repositories. Those are implementation details and should have no effect on the design process.
A large Enterprise Application often has to cover a collection of different business areas, but it would be wrong to think of each of these areas as a separate domain as they have their similarities as well as their differences. It is precisely because of the volume of similarities that I think of this collection of business areas to be a complete system while each member of this collection is just a subsystem. The domain/system is therefore a database application while each subdomain/subsystem is just an implementation of that domain which deals with its particular differences.
I designed and built the RADICORE framework specifically to deal with the domain of database application, which means that it has standard ways of dealing with database tables and their relationships, and each subsystem/subdomain can deal with its own set of tables and relationships using these standard ways. The framework also has standard ways of generating HTML pages, CSV files and PDF reports. Once the database has been designed and built the framework's Data Dictionary can be used to generate both the table classes and, using its library of Transaction Patterns, the user transactions necessary to maintain the contents of those tables. While each of these transactions can be run immediately from the framework's system of menus they do not contain any business rules, but the developer can add these later by inserting the necessary code into the "hook" methods which are available in every table's class. Each subsystem is therefore generated by the framework as an add-on and run from the framework as just another part of an integrated system.
The current RADICORE framework is actually the third iteration of a framework which I first developed in the mid-1980s in COBOL and in the 1990s in UNIFACE, and each iteration has improved my levels of productivity. For example, the time taken to implement this family of forms for a single database table has been reduced as follows:
No matter what the OO afficionados say I ALWAYS start writing code AFTER I have designed and constructed a properly normalised database, then I use RADICORE's code generation facilities to construct the basic components which I then season to taste. When I came to build the TRANSIX application in 2007, my first ERP package I started with some comprehensive database designs which I found in Len Silverston's Data Model Resource Book. These database were PARTY, PRODUCT, ORDER, INVOICE, INVENTORY and SHIPMENTS. I built the components, added the business rules, and demonstrated the first working version to a customer after just 6 man-months. That is an average of one man-month per database. If I were to change my methods and follow the "advice" given by these pseudo-experts and their so-called "best practices" then my levels of productivity would plummet like a lead balloon, so excuse me if I don't follow the crowd and become a Cargo Cult Programmer like so many others in the programming community.
Here endeth the lesson. Don't applaud, just throw money.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles: