Figure 1 - a System

(with apologies to William Shakespeare)
I recently came across an article written by Robert C. Martin (Uncle Bob) with the title NO DB in which he complains about the rise of relational databases and the fact that some developers have the audacity to design their systems around the database. Here are some quotes from that article:
During this time I watched in horror as team after team put the database at the center of their system. They had been convinced by the endless marketing hype that the data model was the most important aspect of the architecture, and that the database was the heart and soul of the design.
....
But then I noticed something. Some of the systems using these nice, simple, tasty, non-relational databases were being designed around those databases. The database, wrapped in shiny new frameworks, was still sitting at the center of the design! That poisonous old relational marketing hype was still echoing through the minds of the designers. They were still making the fatal mistake.
He finishes his argument with this statement:
The database is just a detail that you don't need to figure out right away.
As a developer who has been designing and building database-based enterprise applications for over 30 years I dispute the notion that designing an application around the database is a fatal mistake. On the contrary, not only is it NOT fatal, by adopting a database-centric approach I have found it to be entirely beneficial. I have created an open source framework called RADICORE for building database applications which allows me to be far more productive than any of my rivals. I have used this framework to build a large ERP package, originally called TRANSIX, but which is now being marketed under the name GM-X Application Suite by Geoprise Technologies. This application uses 450+ database tables, 1200+ relationships, and handles 4,000+ user transactions (tasks).
I use my own framework instead of any of the others for several reasons:
In his article Uncle Bob makes the following statement:
The center of your application is not the database. Nor is it one or more of the frameworks you may be using. The center of your application are the use cases of your application.
I disagree most strongly with this statement. It implies that you design your software components first and leave the database till last as it is regarded as nothing more than an "implementation detail". In my experience the best way is the exact opposite - design your database first, then it is the software which becomes the "implementation detail". You have to design and build a database table before you can write the code to access the contents of that table. Trying to do the opposite would be like trying to push a piece of string instead of pulling it.
Nowadays all my applications are developed using the RADICORE framework which produces components based on a combination of the 3 Tier Architecture and the Model-View-Controller Design Pattern, as shown in this structure diagram. Long gone are the days when I wrote single tier monolothic monstrosities. Every application, regardless of the business domain which it covers, has components which exist in three different places:
The purpose of every application is to satisfy the customer's requirements as cost-effectively as possible. These requirements are expressed as a series of business rules, so where do these business rules exist in the structure identified above? They exist in just two places:
Of all the components in my applications all business rules exists in, and only in, the Business layer where the Model components reside. There are NO business rules in the Controller, View or Data Access components. While part of the business rules are expressed in the database design I never use the database to tell me when a rule has been violated. Each database table class has complete knowledge of the structure of the table for which it is responsible. This allows it, with the help of some standard framework components, to validate any CRUD operation before it passes control to the Data Access Object where the relevant SQL query is constructed and executed.
Unlike some people who advocate having a separate method in the Business layer for each use case (user transaction) I think that this idea totally removes the ability to employ Polymorphism, which is one of the principle features of OOP. Polymorphism requires the use of method signatures which are shared by multiple classes, so having method signatures which are unique and never shared removes this extremely useful capability. It should be recognised that communicating with a database can only be done at the table level, and the only operations which can be performed on any table, regardless of its contents, are the Create, Read, Update and Delete (CRUD) operations which are provided in the SQL language. It therefore makes sense, to me at least, to create a separate class which is responsible for the business rules for each database table, and for each of these classes to support the same method signatures to handle each of the CRUD operations. Having a single class deal with more than one table would surely break the Single Responsibility Principle. Having the same CRUD methods in each table class then opens the door to polymorphism.
All interaction with the user, the user transactions (tasks), is done via components in the Presentation layer. Every single task, no matter what it does for the user, follows the same pattern in that it performs one or more CRUD operations on one or more tables. Different combinations of operations on different combinations of tables can be broken down into a series of Transaction Patterns. Each of these patterns has its own Page Controller, but may share the same View object to create HTML, PDF or CSV output. It is possible for each Model component in the Business layer to be accessed by multiple components in the Presentation layer. The most common combination of Transaction Patterns is a forms family which consists of the same six patterns which can be used with any table in the database.
The easiest way for multiple classes to contain the same method signatures is to define those method signatures in an abstract table class which can then be inherited by every concrete table class. The use of an abstract class then opens the door to making use of the Template Method Pattern which allows you to provide boilerplate code in a series of invariant methods plus an empty series of variant or hook methods. These can be defined in a subclass to provide code which is specific to that subclass. In my ERP application I have 450+ database tables which are used in 4,000+ user transactions which are provided by a library of just 40 pre-written and reusable Transaction Patterns. This is made possible by the fact that the Controller script in each Transaction Pattern uses only those public methods which are defined in the abstract table class. This means that every Transaction Pattern can potentially be used with every table class, so if I have 40 patterns and 450 table class this provides the potential for 40 x 450 = 18,000 (YES, EIGHTEEN THOUSAND) opportunities for polymorphism.
When building software which interfaces with a database you are building an application, what used to be called a "data processing system", so it is necessary to first understand what is meant by a "system" in general then a "data processing system" in particular.
A "system" is a something which takes "input" and transforms it into "output", as shown in Figure 1:
Figure 1 - a System
A factory is an example of a system as it takes raw materials and transforms them into finished goods.
A "data processing system" is something which sits between the user and the database. Raw data goes in and is stored in a database from where it can be extracted and formatted in a variety of different ways. This is shown in Figure 2:
Figure 2 - a Data Processing System
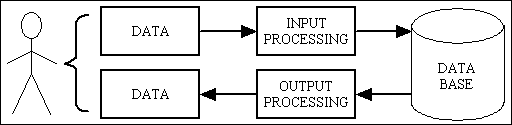
As the software sits between two entities - a user and a database - it is therefore required to have a separate interface for each of these entities, as shown in Figure 3:
Figure 3 - software with two interfaces

Those of you who are on the ball may notice that this 3-part structure can be implemented using the 3-Tier Architecture.
Having worked in a software consultancy for many years designing and building a variety of applications for a variety of customers I have personally been part of the full application life cycle which follows these steps:
This "logical" design is nothing more than a paper document which does not require the generation of any program code. It can be shown to and discussed with the customer to verify that it can meet all their requirements. It can also be used by the consultancy to provide cost and time estimates to build the application.
Note that the output of the analysis/design phase has two parts - a list of use cases (user transactions) with their user interfaces and a logical database design. One without the other would be virtually useless. While the identification of the use cases is the starting point of the logical design process, closely followed by the design of the database, the design of the software components which sit between the user interface and the database involves nothing more than identifying which operations need to be performed on which tables, and what additional business rules need to be implemented. It only identifies what needs to be done, not how it should be done. When, during the implementation phase, it comes to writing the code to deal with the how all users of the RADICORE framework are able to get off to a flying start as most of the work has already been done for them. All table classes can be generated from the Data Dictionary and, by virtue of the fact that each concrete table class inherits all of its boilerplate code from a single abstract table class, the only additional work which is required by the developer is add the code to deal with additional business rules into any of the available "hook" methods.
As the customer pays separately for the production of the Logical Design it has to be of good enough quality and have sufficient detail so that it could be implemented by another consultancy. Different consultancies use different methodologies and toolsets, so may be able to implement that design with different costs and/or timescales.
The team leaders decide on the application architecture, the programming language, and what framework and libraries will be used. Each functional specification identifies a user interface, what actions need to be taken on what database tables, and what business rules need to be applied. The developer then turns the specification into code, tests it, then releases it.
It is important to note here that the output of the analysis/design phase identifies what needs to be done but not how it should be done. It should not be biased towards any particular languages, toolsets or libraries unless it is required to integrate closely with an existing application.
Up until this point each Use Case (user transaction) is nothing but a paper design, and the application itself does not exist except on paper. Once the Build phase starts the physical database can be built from the logical design, then detailed functional specifications can be produced and handed off to the developers so that they can turn the paper designs into working code. I have seen two approaches used by analysts when preparing functional specifications for developers:
In my experience the former has always led to disasters as analysts who are not also developers are not the best people to determine what code should be written in order to achieve the desired result. An experienced developer is quite capable of taking a document which describes the what and turning it into the how by writing efficient and effective code. I have personally seen what happens when the analyst emphasises the how without mentioning the what. In one case I wrote the code exactly as it was specified as that was all I had to work with. When the analyst tested what I had written he complained to me that it did not produce the results that he expected. It was only by getting him to explain precisely what the program was supposed to do that I spotted a serious flaw in his pseudo-code. The code that I eventually wrote to implement his requirements bore no resemblance to the code that he had envisaged, yet the results were correct.
Please read Logical Versus Physical Database Modeling for a more complete description of the differences between a logical and physical database design.
The start of the Build phase is also when the big question is asked - do you design the software to match the database, or design the database to match the software?
Too many of today's OO programmers know very little of how relational databases work, but have their heads crammed full of Object-Oriented Design (OOD) theory. They seem to think that the universe revolves around their precious theories and that everything else, especially the database, is nothing but an implementation detail which can be left until later. A common approach is to use mock objects to simulate all communication with the database and not to build the physical database until the software has been finalised. A reason for this is that it may become difficult to make changes to the database structure after the software has been written. As far as I am concerned if an application which is written to interact with a database cannot deal with changes to the database structure without requiring significant changes to large numbers of software modules then that software has been badly designed and/or written. My RADICORE framework was specifically designed to build database applications, and it was also designed to deal with changes to the database structure with the minimum of disruption. Some developers may seem to think that I am tied to the waterfall model, but in reality I can be as agile as the next man.
Anyone who has been involved in writing database applications for a reasonable amount of time should be able to tell you that the design of the database is absolutely paramount. If you get this design wrong this will have a detrimental effect on the entire application and no amount of clever code will fix it. This is emphasised in the following quote:
Smart data structures and dumb code works a lot better than the other way around.Eric S. Raymond, "The Cathedral and the Bazaar"
In order to design an efficient structure for your database you should follow the rules of data normalisation. You know when this design is correct when you can generate SQL queries to obtain the data for all your use cases (user transactions) as efficiently as possible. Any online query that is forced to use a full table scan is the product of a bad database design and will cause slow response times followed by complaints from your users. The beauty of a good database design is that not only will it handle all the queries you have identified today, but it will also be able to handle most if not all of the new queries that may arise in the future. Invariably the user will generate new or modified requirements which may require the addition of extra columns or extra tables, or perhaps moving columns from one table to another. Any such modifications should also be subject to the rules of normalisation so that the data structure is not compromised otherwise it will come back to bite you. Been there, done that, got the t-shirt.
Once the physical database has been built it should be possible to start writing the code to access that database. I say should, but unfortunately the OO purists just love to introduce a totally unnecessary software design phase which has to deal with IS-A and HAS-A relationships, along with class hierarchies, dependencies, associations, aggregations and compositions. The result of this process is invariably a software structure which is incompatible with the database structure. This causes a problem known as the Object-Relational Impedence Mismatch for which the solution is an Object-Relational Mapper (ORM). I think that such things are an abomination as they create more problems than they solve. In a situation such as this I prefer to follow this advice:
It is better to attack the root cause of a problem instead of addressing its symptoms.
If the root cause of the problem is a mismatch between the two structures then in my book the best solution would be to remove the cause of the mismatch. This can be done by producing one structure instead of two, but which one should you keep and which one should you ignore? The answer to me was a no-brainer. Having designed and developed database applications for several decades before switching to an OO-capable language I was very familiar with database design. In 2002 when I ventured into the world of OOP with the PHP language I knew nothing about object-oriented programming except that it was the same as procedural programming but with the addition of encapsulation, inheritance and polymorphism. I was not aware that I was supposed to design my classes according to a different set of artificial rules, so I ended up in the position of ignoring a huge number of them.
By treating the database as the heart of the application and the software as an implementation detail which can be left until last I am doing the total opposite of what the latest generation of developers is being taught, yet my results are visibly superior. I make that claim by virtue of the fact that by implementing OO theory properly I should be able to increase the amount of reusable code and therefore decrease code development and maintenance. The levels of reusability that I can achieve with my RADICORE framework have yet to be matched by any of my rivals. Once I have designed my database and understand how each use case (user transaction) is supposed to access that database I don't need to go through any OO design process as my framework makes that totally unnecessary:
In my long career I have personally built thousands and thousands of user transactions, and this has enabled me to spot various patterns which appear over and over again. By splitting each transaction into three parts - structure, behaviour and content - I have noticed that combinations of structure and behaviour are repeated over and over again, and it is only the content which is different. I have dealt with each of these three areas by creating the following:
The possible combinations of structure and behaviour are described in Transaction Patterns. Note that these are not the same as design patterns which I do not use as they are the wrong level of abstraction and provide very little in the way of reusable code.
Using my framework I can start with a database structure and build basic working components at the touch of a few buttons:
Using this procedure I can import a database structure and generate the class files at the touch of a button, then generate the tasks to maintain one of those database tables at the touch of another button within 5 minutes and without having to write a single line of code - no PHP, no HTML and no SQL. Unless you can match that level of productivity you are wasting your time by telling me that my methods are wrong.
Now compare this with what my critics like to call the proper way. As an example I shall take the use case "Pay an Invoice" as I have seen this used as examples in articles written by others. The first thing to identify is how this use case will access the database. The answer should be in two parts:
The purist way is to design an INVOICE class which controls access to all the database tables which are related to an invoice. It is simply not done to create a separate class for each table. This then requires the design of all the methods which will access all of those tables, as well as the getters and setters for each piece of data. For example, this will have a payInvoice() method and possibly an updateBalance() method which contain the code which updates the PAYMENT table and the INVOICE_HEADER table. This is then followed by the building of an INVOICE controller which accesses those methods in order to get the INVOICE object to do it's stuff.
It is obvious to me that the design and building of both the INVOICE class and the INVOICE controller will take quite some time, and as far as I am concerned this time is totally wasted. My approach cuts out all this waste:
It is important to note here that each table class can be accessed by any Controller, and each Controller can access any table class. How's that for reusability?
I also don't bother to use a front controller and a router as that is already handled by the web server. Every URL used to activate an application component is pointed directly to a component script which identifies which combination of Model, View and Controller will be required to complete that task.
To implement this particular use case I would create a new task using the ADD2 pattern and the PAYMENT table which would be accessing from a navigation button on the "List Invoices" screen. By calling the insertRecord() method on the PAYMENT object I have immediately taken care of the the primary database update, but what about updating the invoice balance? If you consider the business rule as being stated as "after adding a record to the PAYMENT table you must update the balance on the INVOICE_HEADER table" you should easily spot the logic in my implementation:
function _cm_post_insertRecord ($fieldarray) // perform custom processing after database record has been inserted. { $dbobject = RDCsingleton::getInstance('invoice_header'); $data = $dbobject->updateRecord($fieldarray); if ($dbobject->errors) { $this->errors = array_merge($this->errors, $dbobject->getErrors()); } // if return $fieldarray; } // _cm_post_insertRecord
Note here that I am not recalculating the balance before I call the updateRecord() method, I am merely telling the INVOICE_HEADER object to update itself. The primary key of the relevant INVOICE_HEADER record is extracted from $fieldarray.
function _cm_pre_updateRecord ($fieldarray) // perform custom processing before database record is updated. { $dbobject = RDCsingleton::getInstance('payment'); $query = "SELECT SUM(amount) FROM payment WHERE invoice_id={$fieldarray['invoice_id']}"; $balance = $dbobject->getCount($query); if ($dbobject->errors) { $this->errors = array_merge($this->errors, $dbobject->getErrors()); } // if $fieldarray['balance'] = $balance; return $fieldarray; } // _cm_pre_updateRecord
This code will automatically be processed for every update even though the balance may not have actually changed, but you won't know that it hasn't changed unless you actually look.
By cutting out the need for a custom-built INVOICE object and an INVOICE controller I have cut out the middle man and gone straight to the heart of the matter - the use case performs an operation on a database table, so I use a controller which performs that operation and simply tell it which table to operate on. Additional business rules can be handled by inserting the relevant code into the relevant customisable methods.
Uncle Bob's notions that The center of your application are the use cases of your application
and The database is just a detail that you don't need to figure out right away
simply do not exist in the universe in which I have lived for the past 4 decades. The use cases are merely an extension of the user's requirements expressed in more detail. They identify what needs to be done but not how it should be done. The how is part of the design phase, but then the question arises what do you design first, the software or the database?
Decades of experience has taught me that the database design is always the most important part of the application, and no amount of whining from any so-called OO guru will convince me otherwise. In my book both the identification of the use cases and the design of the logical data model are equal partners, and both take precedence over the software design.
Not only is it possible to derive the data model from the use cases, it is also possible to derive the use cases from the data model. When I started building my main enterprise application in 2007 I started with several database designs I found in Len Silverston's Data Model Resource Book, then, using the ability of my RADICORE framework to quickly generate working transactions to maintain each of those database tables I had a working prototype which I could demonstrate to my first client in just six months. When you consider that this prototype consisted of the PARTY, PRODUCT, ORDER, INVENTORY, INVOICE and SHIPMENT databases you might be ever-so-slightly impressed. How long would it take you using your framework?
Since that prototype went live in 2008 I have modified the databases, even added new databases, and added more user transactions. The application how has 450+ database tables, 1200+ relationships, and 4,000+ user transactions. I could not have achieved this if I had followed the advice of the OO purists, which tells me that OO "purity" is not the silver bullet that it's made out to be. In fact I would go so far as to say that it is more like a gilded turd.