Figure 1 - Radicore Infrastructure Overview
")
Every once in a while I am told by a developer who looks at my code that he considers it to be nothing but crap. Although the actual wording may be different - your code is unstructured, unreadable, unmaintainable, you don't understand design patterns, yadda yadda yadda - depending on whether the message is posted to a public forum or by private email, the sentiment is the same. The latest criticisms were posted as comments to a Sitepoint article called The PHP 7 Revolution: Return Types and Removed Artifacts, specifically post #152 which lists the following "amateur mistakes":
SQL injection vulnerabilities. Mail header injection vulnerabilities. Global variables up the wazoo. Control logic mixed with DB logic mixed with validation logic mixed with... pretty much every other kind of logic.
Further criticisms (more like attacks and personal insults, actually) have been provided in the following recent Sitepoint discussions:
After reading the numerous criticisms you might also think that my code is crap, but if you looked closer you would actually see that each accusation is totally false. My critics are not making statements of fact, they are merely being echo chambers for outdated ideas. Let me step through each of them and explain why.
If you look at securephpwiki.com you will see an example of code which exposes this exploit. It suggests the following as solutions, either magic_quotes_gpc (which was deprecated in 5.3 and removed in 5.4) or addslashes(). It you look at that sample of my code you will see that I actually use addslashes(), so where is the vulnerability? Note only that, but where a database extension provides its own method of escaping special characters, such as MySQL's real_escape_string, I actually use that within my data access object.
If you look at securephpwiki.com you will see an example of code which exposes this exploit, with a selection of possible solutions.
In the first place there is nowhere in that code where I am sending an email, so where exactly is the vulnerability?
In the second place where I actually do send out an email using details supplied by the user I have already incorporated the solution which uses the regular expression (although I actually use preg_match() as eregi() has been deprecated).
For a definition of global variables please refer to this wikipedia entry.
Whenever somebody says "X is bad", where X in the software world can be anything from global variables to inheritance to dependency injection to design patterns to <name your poison here> it is usually somebody mis-quoting a statement made by somebody else who said "X can be bad when ...." and thereby changing the statement from conditional to unconditional. Just because it is possible for a bad programmer to misuse "X" and create bad code, that is no reason to prevent a good programmer from using "X" when appropriate to produce good code. How many times has a doctor made the statement "Too much X is bad for you" only to have someone drop the "too much" qualification and report it as "X is bad for you", thus implicitly changing "too much" to "any quantity". Consuming too much water can be bad for you, but does that mean that we should all stop drinking water?
Whenever I come across such a blanket unconditional statement I am now old enough and wise enough to assume that somebody, usually out of ignorance and not malice, has accidentally dropped the condition that went with the original statement and has therefor changed its true meaning. Whenever I see a blanket rule like this I now ask the question "Under what circumstances is X bad?". If the person quoting that rule cannot justify its existence then it has no right to exist, so I ignore it. If the conditions which make it bad no not exist in my code then it does not apply to my code code, so I ignore it.
When you consider the fact that every programming language ever written has support for global variables, I am sure that if they were really bad that support would have been dropped, just like some modern languages no longer support the GOTO statement. When I search for the exact conditions under which global variables are bad I come across arguments such as the following:
This would be a prime example of very bad programming as every good OO programmer should know that an object's state should always be kept inside the object.
Each global variable should be used for one thing and one thing only. Having the same variable used for different things in different parts of the program is a sign of sloppy workmanship on the part of the programmer and is therefore NOT the fault of global variables in general. In my early COBOL days I encountered quite a few programs where the programmer always created a block of global variables called flags, indicators or switches with the names SW1, SW2, SW3 and so on. Each switch could hold a collection of possible values, sometimes just ON or OFF or sometimes a range of values. The definition of each switch could never describe the range of possible values and their meanings, so you had to hunt through the code to find where values were assigned and hope that the code contained a comment as to why that particular value was being assigned at that particular point. That is why when I composed my own programming standards I insisted on the use of condition names which enabled all these issues to be eliminated in one fell swoop.
This depends on the capabilities of the programming language which you are using. For example, in my COBOL days a user could start the online program at 9am, at which point the necessary memory space was assigned, and this space would be used continuously by whatever subprograms were run during the working day. This memory space would not be deallocated until the user terminated his copy of the online program. PHP, on the other hand, is entirely different. Computer memory is not not assigned at the start of the user's working and released at the end. As each web page is run it always starts off without any shared memory whatsoever, and when it finishes any memory which has been allocated is automatically released. It should therefore be obvious that any global variable which is created can ONLY be created during the execution of the current script, and any programmer who is incapable of locating where a particular variable is assigned is, in my humble opinion, a pretty poor programmer indeed.
Agreed, but that is only a problem if a poorly trained programmer makes it a problem.
Then you do not understand what Coupling actually means, so that criticism is bogus.
You can only pollute something if you over-use, mis-use or an-use that something, so the simple answer is properly, sparingly and intelligently.
I have been writing and testing programs which use global variables for 40 years and I do not recall any problems resulting from their use. Except, that is, in one early version of a particular language which used numbered, not named, global variables to pass arguments from one component to another. The problem arose when the calling component loaded valueX into variable $29 and valueY into variable $30 while the receiving component used variable $30 for valueX and variable $29 for valueY.
If you look at securephpwiki.com you will see a description of a vulnerability which is caused by the use of register_globals. This was deprecated in 5.3 and removed in 5.4, but I stopped using it much earlier as soon as heard that it could cause problems. So where exactly is the vulnerability in my code?
Globals in PHP are not really globals in the same sense as they are in other languages. This because the $GLOBALS variable is bound to the request and not kept between requests, which would make it difficult to identify where a global variable was modified and where it was referenced. This makes the $GLOBALS variable no different from any other variable inside a request - it always starts off as being empty at the start of request, and is always discarded at the end of the request. This means that anything within the $GLOBALS array was created within, and may only be referenced within, the current request. How can that be such a bad thing? It is surely no more of a problem than the $_GET, $_POST, $_SERVER and $_SESSION arrays.
Some people advocate the use of variables inside a global object, but as far as I am concerned this does not offer any benefits over the $GLOBALS superglobal, and as it requires extra effort it seems like wasted effort to me, so I'd rather not bother.
Global variables exist in some form or other in every programming language. They are just a tool, just like every other feature of the language, and just like any tool they can be used in both appropriate and inappropriate circumstances. If someone uses a tool and screws it up then it is is a bad workman who blames his tools instead of his own poor workmanship.
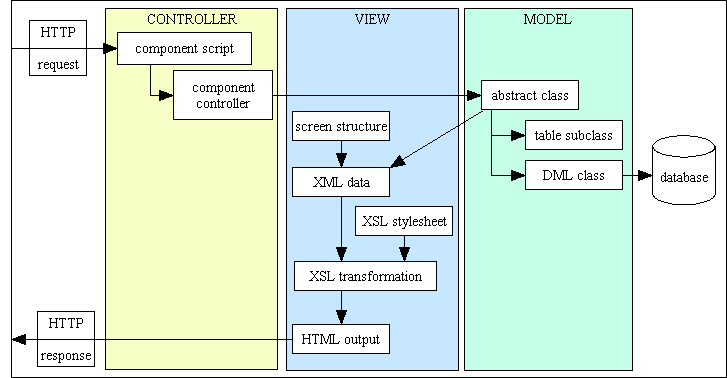
Firstly, the way I split my application logic into different components is explained in You have not achieved the correct separation of concerns. This summarises my implementation of the 3-Tier Architecture and the Model-View-Controller design pattern.
Secondly, it is very important to understand the difference between logic and information, which is why I wrote Information is not Logic just as Data is not Code. For example, take the following code snippet:
$this->sql_select = '.....'; $this->sql_from = '.....'; $where = '.....'; $fieldarray = $this->getData($where);
Anyone who describes that as "data access logic" is clearly seeing what isn't there. There are some lines of code which load strings into variables, and a call to a getData method, but this does not touch the database. If you look at this UML diagram you will see that the getData method in the Model will call the _dml_getData method which passes control to a separate DML (Data Manipulation Language) object, which is also known as the DAO (Data Access Object). This is the object responsible for constructing SQL queries and sending them to the relevant database using code similar to that shown in the following code snippet:
$query = "SELECT SQL_CALC_FOUND_ROWS $select_str FROM $from_str $where_str $group_str $having_str $sort_str $limit_str"; $result = mysqli_query($this->dbconnect, $query);
There is nothing in snippet #1 which touches the database. You cannot even tell which database extension is being used to access which database, so it cannot be described as "data access logic". The opposite is true with snippet #2.
I use this mechanism in order to provide me with the ability to construct SQL queries which are more complex than the simple SELECT * FROM <tablename>. While other developers devise more obfuscated ways to achieve the same thing, such as using a type of pseudo-SQL which is then translated into proper SQL in an Object Relational Mapper, I prefer the direct approach.
The accusation that each Model class contains validation logic when it should not is completely wrong. Validation logic for an entity is considered to be part of the business logic for that entity, so should therefore be defined within the Model class which you construct for that entity. You should not put any business logic in any place other then the Model - not in a Controller, not in a View, and not in a DAO.
The accusation that each Model class contains formatting logic is completely wrong. In the context of the 3-Tier Architecture the presentation/display logic in the Presentation layer is responsible for transforming the data obtained from the Business layer from its internal format, which is a PHP array, into a different format which is more presentable to the user, such as HTML, CSV or PDF. There is no code in the Business layer which performs this transformation, so it is completely wrong to say that there is presentation logic in the Business layer. The "formatting" logic in the Business layer does not transform the PHP array, it does nothing but format dates and decimal numbers within the array according to the user's language preferences, and that is part of the business logic.
The accusation that each Model class contains workflow logic is completely wrong. There is a small amount of code there only to decide if it is necessary to pass control to a separate workflow object. Having code which passes control to another object is not the same as carrying out the responsibilities of that object.
The actual accusation is:
You have a class with over 120 methods and 9,000 lines, therefore it must be doing too much. It must surely be a "God" class.
For the correct definition of a "God" class please refer to this wikipedia entry which clearly states that this is where all (or most of) a program's functionality is contained in a single component. This is also an example of a monolithic or single tier architecture. In his article 9 Anti-Patterns Every Programmer Should Be Aware Of the author Sahand Saba describes it as:
Classes that control many other classes and have many dependencies and lots of responsibilities.
My code does not fit the description of a "God Object" for several reasons:
If I am using well known design patterns to provide high levels of reusability in my code then how can anyone say that I am wrong based on nothing more than the ability to count?
If my critics would simply take the time to engage their tiny brains before opening their big mouths they would be able to see that my software is based around a combination of the 3-Tier Architecture and Model-View-Controller design pattern, as shown in figure 1:
Figure 1 - Radicore Infrastructure Overview
Note that all the components in the above diagram are clickable links which will take you to the descriptions of those components.
The so-called "God" class, which is item #4 in the above diagram, is not even a concrete class but is an abstract class which is inherited by every Model class (item #3 in the above diagram) in the Business layer. You should also notice that this structure has separate components for the following:
So far from being a "God" class that does everything it should be obvious that:
The methods in this class fall into one of the following categories:
It should also be obvious that each object in the business layer does NOT have many dependencies, it only has one - the data access layer.
There may be over 9,000 lines of code in this abstract class but these are split across 254 methods, so that gives an average of about 35 lines per method. These methods can be categorised as follows:
The true definition of a god class contains the phrase Most of such a program's overall functionality is coded into a single 'all-knowing' object
. While you may think that 9,000 lines is a lot, it is just a small part of the 53,000 LOC that exist in my reusable library. This means that my abstract class contains 9/53rds or 17% of the overall functionality. I don't know who taught you maths, but 17% cannot be described as "most" in anybody's language.
You should also be aware of the following points:
None of the methods in my "monster" class contains logic which belongs in another object, so none of its methods can be moved to another object. Because I have all of my business logic in the Model and none in any Controller or View I have what is known as a "fat model, skinny controller" combination which everyone knows is far better than a "skinny model, fat controller".
If you look close enough you should see that this arrangement does not match the description controls many other classes and has many dependencies and lots of responsibilities
for the simple reason that the only dependencies in each Model class are the Data Access Object (item #6 in the above diagram) and the Validation object (item #5 in the above diagram).
Any notion that this class breaks the Single Responsibility Principle (SRP) based on nothing more than the count of methods or lines of code is therefore unscientific and unreliable. It is just as stupid as saying "your class contains only ten methods, therefore it must surely be following SRP". The fact that these counts are higher than those which you have previously encountered just means that you have never worked on an application which is as sophisticated or functionally rich as mine. If you only ever work on puny applications then you can get away with your puny rules, but bigger applications need bigger rules and developers with bigger ideas. Every one of the methods in that class is closely related to other methods, which means that they form a cohesive unit. If you do not understand what "closely related" means then consider these facts:
As you can see establishing "closely related" takes more brain power than simply being able to count.
Robert C. Martin has written several articles on SoC/SRP (see here, here and here) in which he clearly identifies only three responsibilities which should be separated - GUI logic, business logic and database logic. All my Model classes, which inherit from my "monster" abstract class, follow this principle by virtue of the fact that each is responsible for the business rules associated with a single database table. Note the use of the words "single" and "responsible" in that description. In none of these articles does he mention that a class should be limited by the count of methods or lines of code, just by the responsibility that the class carries out. Even if he did he would be wrong as that would violate the rule of encapsulation which specifically states that ALL the methods and ALL the properties should be contained in a SINGLE class.
The problem with most developers today is that they do not understand what the Single Responsibility Principle (SRP) actually means, when to start applying it and when to stop applying it. For a definition of "responsibility" take a look at what Robert C. Martin (Uncle Bob) wrote in his article Test Induced Design Damage?
How do you separate concerns? You separate behaviors that change at different times for different reasons. Things that change together you keep together. Things that change apart you keep apart.
GUIs change at a very different rate, and for very different reasons, than business rules. Database schemas change for very different reasons, and at very different rates than business rules. Keeping these concerns (GUI, business rules, database) separate is good design.
This quote is clearly a description of the 3-Tier Architecture on which my framework is based as this has separate layers for Presentation/GUI logic, Business logic and Data Access logic. This method of modularising an application is also described by Martin Fowler in his article PresentationDomainDataLayering, so it is an accepted and common practice. In addition to this I have also applied the MVC design pattern by splitting the Presentation layer into two separate parts - the Controller and the View, which results in the structure shown in Figure 2.
Figure 2 - The Model-View-Controller structure
Having used SRP to identify the different responsibilities I have created separate classes to deal with each of those responsibilities according to the rules of encapsulation. After that point I stopped applying SRP as to go any further would be to go too far and change a modular system of cohesive units into a fragmented system in which all unity and cohesion would be lost. When splitting a large piece of code into smaller units you have to strike a balance between cohesion and coupling. Too much of one could lead to too little of the other. This is what Tom DeMarco wrote in his book Structured Analysis and System Specification:
Cohesion is a measure of the strength of association of the elements inside a module. A highly cohesive module is a collection of statements and data items that should be treated as a whole because they are so closely related. Any attempt to divide them would only result in increased coupling and decreased readability.
Having methods in the same class which are not related would be wrong, just as having methods which are related but placed in different classes would be wrong. It is a question of balance, so when applying any software principle the intelligent developer has to know if and when to start applying it but also when to stop. This cannot be taught, it can only be learned. Sadly, too many of today's developers can do nothing except echo what they have been taught. They are not prepared to think for themselves, they are not prepared to question what they are taught, and they are not prepared to experiment and try out new ideas. All they can do is perpetuate the myths and legends spewed forth by these snake oil salesmen, and they cannot understand why theory and practice are not the same.
Unless you have your head stuck so far up your a**e you can contemplate your navel from the inside you should clearly see that the architecture shown in Figure 2 is anything but monolithic as it has been broken down into a collection of separate modules each with their own distinct responsibility. If you still don't understand what it means then let me give you the ten cent tour:
Please note that a method called by a Controller may involve calling a series of sub-methods which break that processing into logical steps, as shown in the UML diagram in figure 3:
Figure 3 - UML diagram for Update 1
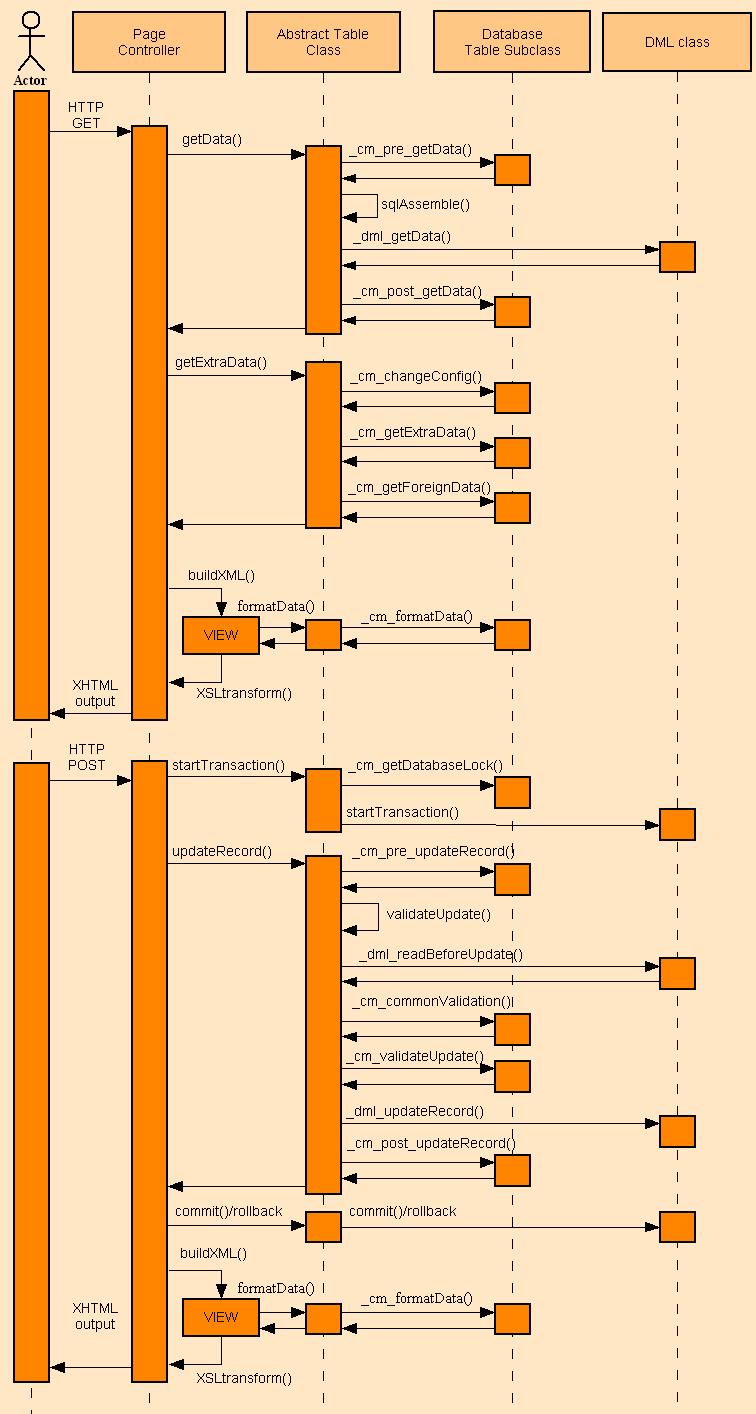
Note that the prefix on the method name denotes its usage:
For those of you who cannot digest information which is presented in a picture, there are a thousand words in Table 1:
When a method is called from the Controller it sometimes leads to calls on one or more internal methods, and sometimes touches the database through the Data Access Object.
I have not numbered the duplicate entries for _getDBMSengine(), so you should see that there are 42 methods just to complete a simple update of a single record. Also note that 20 of these methods (the ones with the "_cm_" prefix) are customisable and exist only that they may be copied to a concrete class and filled with code in order to override the default behaviour. If you think that 42 methods for a simple update task is too much then either you have difficulty counting above 10 without taking your shoes and socks off, in which case you are an idiot and your opinion does not count, or quite obviously you have never worked on a sophisticated and feature-rich enterprise application, so you are not qualified to have an opinion on such matters.
Every one of those methods is there for the same reason - to deal with data which is either going into or coming out of a database table - and belongs in the Model/Business layer and not in the Controller/View/Presentation layer. If you also look closely you should see that, with limited exceptions, all those methods have the table data as an argument. This data is also available as $this->fieldarray, so if all those methods perform different operations on the same data then how can you say that they don't belong together in the same class? To do otherwise would surely be a violation of encapsulation.
If I can justify having 42 methods in my Model class just to cater for one update pattern, then it should not be unreasonable to have additional methods to deal with the other 50 Transaction Patterns in my library, which means that 120 methods in total is not so ridiculous after all.
It should be clear to anybody but the blind that all the code I have within my "monster" abstract table class is there because it is part of the Model and cannot logically be moved to the Controller, View or DAO. If there is no logical reason to move the code elsewhere then you are wasting your time by inventing an arbitrary rule that has no basis in logic. Whether you like it or not each of those 120 or so methods in my "monster" class is there to perform an operation in the business layer, and by splitting it into artificially small units I would be taking a cohesive modular system and turning it into a disjointed fragmented system, and everyone knows that such a system would be more difficult to read, more difficult to understand, more difficult to maintain and more difficult to enhance. So said Tom DeMarco in his book Structured Analysis and System Specification:
Cohesion is a measure of the strength of association of the elements inside a module. A highly cohesive module is a collection of statements and data items that should be treated as a whole because they are so closely related. Any attempt to divide them would only result in increased coupling and decreased readability.
If you look carefully at my abstract table class you will see that it only has the following dependencies:
Since when can this small number of dependencies be classed as "too many"?
One of the aims of OOP is to increase code reuse, and here I have an abstract class which enables me to share 9,000 lines of code among 300+ model classes using the single word "extends", so what can be wrong with that?
This claim, made in this sitepoint post completely contradicts what was said in this sitepoint post and this post and this post and this post and this post and this post and this post and this post and this post and this post and this post. If you look very carefully you will see that all these posts were made by the same person, a certain s_molinari.
How is it possible for the same person to first accuse me of creating a monster "god" class which tries to do everything, then complain that it also fits the description of an anemic domain model which does practically nothing? The wikipedia article describes this as follows:
Anemic domain model is the use of a software domain model where the domain objects contain little or no business logic (validations, calculations, business rules etc).
The name "anemic domain model" was first described my Martin Fowler as follows:
The basic symptom of an Anemic Domain Model is that at first blush it looks like the real thing. There are objects, many named after the nouns in the domain space, and these objects are connected with the rich relationships and structure that true domain models have. The catch comes when you look at the behavior, and you realize that there is hardly any behavior on these objects, making them little more than bags of getters and setters. Indeed often these models come with design rules that say that you are not to put any domain logic in the the domain objects. Instead there are a set of service objects which capture all the domain logic. These services live on top of the domain model and use the domain model for data.
The fundamental horror of this anti-pattern is that it's so contrary to the basic idea of object-oriented design; which is to combine data and process together.
If you looked closely at the definition of each concrete table class you would see that it inherits from an abstract table class, and it is this abstract class which provides the standard processing. All data validation is performed by a single validation object which is called by code inherited from the abstract table class. This uses the contents of the $fieldspec array for each class to validate that each field within $fieldarray matches its specifications. By virtue of the fact that every method called from a Controller on a Model is an instance of the Template Method Pattern means that any business rules can be inserted into the relevant "hook" methods which can be added to any Model class.
If you look at what I wrote in reply to You have created a monster "god" class you should see that I have correctly broken down my application into separate units - Controllers, Views, Models and Data Access Objects - where all domain logic, which includes data validation and business rules, exists in, and ONLY in, the domain or Business layer. This layer is comprised of a collection of Model classes, one for each database table. The fact that each Model class, when combined with the abstract class, contains logic for data validation, business rules and task-specific behaviour should completely disprove the accusation that it does not do enough, just as the fact that each Model does not contain any control logic, view logic and data access logic should completely disprove the accusation that it tries to do too much.
Accusations that my Model class does either too much or too little shows that my accusers do not really understand what these terms actually mean. Let me enlighten you:
So if the claim that my Model classes do "too much" is false, and the claim that my Model classes do "too little" is also false, where does it place them? Securely in the middle, I would say, and guess what description sits between "too much" and "too little"? You've guessed it - "just right". This, as far as I am concerned, is just about as close to perfection as it is possible to get. It also fits the description of the Goldilocks Principle.
For a definition of the singleton pattern please refer to this wikipedia entry which states the following:
In software engineering, the singleton pattern is a software design pattern that restricts the instantiation of a class to one object. This is useful when exactly one object is needed to coordinate actions across the system.
Note that this description identifies what the singleton is supposed to achieve - having a single instance of an object which can be accessed from multiple places - but it does not identify how this should be achieved. The actual implementation is left entirely to the developer, so I have chosen an implementation which achieves the objectives with the minimum number of adverse side effects. If other developers have problems with singletons then I would suggest that it is their implementation of the pattern which is faulty and not the pattern itself.
When people tell me that singletons are bad they can rarely explain exactly what the problems are supposed to be. After a bit of research I found the following:
They are supposed to, you dummy! The whole idea behind having a singleton is that it is globally accessible from anywhere within your application. It can only be globally accessible if it exists in global scope. Besides, I do not consider that using global namespace is exactly the same as polluting it. It is simply not possible to pass every variable that may be used in the list of arguments which are passed to a function or a method, which is where the careful use of global variables provides a simple solution. Note that the careful use of global variables is NOT the same as indiscriminate use.
This is supposedly because they produce two responsibilities:
I think that this statement is invalid as it relies on what I consider to be a totally perverse interpretation of what the Single Responsibility Principle (SRP) actually means. If a class can only contain methods which are actually used by the object itself then how come a class can contain a constructor and a destructor. A PERSON object cannot construct or destroy itself, so why should it contain methods which perform those operations? Surely those methods are performed ON an object and not WITHIN it, so should be written as construct($object) and destroy{$object) instead of $object->construct() and $object->destroy(). You may think that this idea is totally perverse, but it is merely an extension of a different perverse idea.
Besides, my implementation does not use a getInstance() method within each class, so there is no code within the class which dictates how many instances may exist at any one time.
Sometimes a class is coded so that its constructor is private, which means that it can only be instantiated using the getInstance() method, but guess what? I don't! It is totally up to me whether I use new or getInstance(), the class itself does not have any control over how it is instantiated.
A common example of this problem is where an application was originally coded to only use a single database instance, which then disallowed a future requirement to use more than one instance. A feature of my implementation is that I NEVER instantiate a database instance and then inject it into the object which may want to use it, I wait until I actually want to communicate with the database and only instantiate the object at the last possible moment. As I have complete control over the name which I use for each instance I am able to create more than one instance of the same database server or even have instances for different database servers at the same time.
Not if you use new on the subclass. When I use singleton::getInstance() on the subclass it does not start by firing the getInstance() method on the parent class, it simply executes new on the subclass.
Not in my framework they don't! I do not have Model classes which have to be configured before they can be used, so this is not a problem. Each class has a single configuration except for my database class where each instance is tied to a single database server with its own connection parameters. If I ever require to access more than one database server in the same script then my code is clever enough to use a single separate instance for each server.
So what? This is only a problem if a user of a singleton changes its state which can then cause problems to other users of that singleton. I do not have this problem in my framework as whenever I consume the services of a singleton object I extract whatever state I need from that object and store it locally, and if another user of that singleton does something to change its state it has no side effect on any previous users.
I disagree completely. They are just one method of obtaining a dependent object, but although a dependency is a sign of coupling it is not automatically a sign of tight coupling. If a module interacts with a dependent module through a simple and stable interface and does not need to be concerned with the other module's internal implementation then this fits the description of loose coupling.
As you can see, I do not have the "problems" that other programmers have in their inferior code, so as far as I am concerned singletons are NOT evil at all. Perhaps the real problem lies with their particular implementations and not the concept itself.
You might also want to read what Robert C. Martin has to say on this topic in his article called The Little Singleton. There is also an article called What's so bad about the Singleton? by Troels Knak-Nielsen.
So what? It may come as a surprise to you, but the three fundamental principles of OO are Encapsulation, Inheritance and Polymorphism. That is not just my personal opinion, it is also the opinion of the man who invented the term. In addition, Bjarne Stroustrup (who designed and implemented the C++ programming language), provides this broad definition of the term "Object Oriented" in section 3 of his paper called Why C++ is not just an Object Oriented Programming Language:
A language or technique is object-oriented if and only if it directly supports:
- Abstraction - providing some form of classes and objects.
- Inheritance - providing the ability to build new abstractions out of existing ones.
- Runtime polymorphism - providing some form of runtime binding.
If some idiot is now attempting to redefine what OO means then I shall take great pleasure in ignoring him.
There is nothing wrong with inheritance provided that it is used properly. The problem is that there are too many people who do not understand what "properly" means. A common mistake is to create class hierarchies which are often six or more levels deep, which caused Paul John Rajlich to say the following:
Most designers overuse inheritance, resulting in large inheritance hierarchies that can become hard to deal with.
In the same article he said:
One way around this problem is to only inherit from abstract classes.
Guess which method I use? All my concrete Model classes inherit from a single abstract class, so I don't have complex class hierarchies at all. So not only do I not have the problem caused by complex hierarchies, I have already implemented the preferred solution.
The idea that inheritance breaks encapsulation I also find to be completely nonsensical.
As for the equally ridiculous notion that I should favour composition over inheritance I have already answered that.
Here someone is objecting to the fact that I have created a function called is_True(). Why shouldn't I? This is the code that it contains:
function is_True ($value)
// test if a value is TRUE or FALSE
{
if (is_bool($value)) return $value;
// a string field may contain several possible values
if (preg_match('/^(Y|YES|T|TRUE|ON|1)$/i', $value)) {
return true;
} // if
return false;
} // is_True
As you can see the value "true" can be represented in a variety of ways (boolean, string, numeric). Why? Because different DBMS engines have a different way, or several different ways, of allowing BOOLEAN fields to be defined. In HTML the only boolean control is a checkbox, and when selected the value returned is "on". As I have to cater for all the possible options this makes the code a little complex. When I want to perform this test I can either write out that same block of code again and again, or I can follow the DRY principle and put it into a reusable library. How can this be wrong?
Rather than my approach being described as "too simple" have you ever considered that it is your approach which can be described as "too complex". I have always been a follower of the KISS principle (which is also known as Do The Simplest Thing That Could Possibly Work) which means that I always start with a simple solution and only add complexity when it is absolutely necessary. This approach is supported in the the article KISS With Essential Complexity.
Somebody once told me:
If you have one class per database table you are relegating each class to being no more than a simple transport mechanism for moving data between the database and the user interface. It is supposed to be more complicated than that.
But why exactly should it be more complex than that? For my in-depth response please look at Your approach is too simple and also Why is OOP so complex?.
The problem with complexity was highlighted in this quote from C.A.R. Hoare:
There are two ways of constructing a software design. One way is to make it so simple that there are obviously no deficiencies. And the other way is to make it so complicated that there are no obvious deficiencies.
Martin Fowler, the author of Patterns of Enterprise Application Architecture (PoEAA) wrote:
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
Here is an alternative translation:
Any idiot can write code than only a genius can understand. A true genius can write code that any idiot can understand.
Or to put in another way:
The mark of genius is to achieve complex things in a simple manner, not to achieve simple things in a complex manner.
The problem with a lot of today's programmers is that they think that if a concept is too simple then anybody could do it, in which case they would not be able to demand such a high salary. These are the people who ignore the KISS principle and instead use the LMIMCTIRIJTPHCWA principle. Is this because they are deliberately making things more complex than they need be, or that they genuinely don't know how to reduce a solution down to its simplest elements?
These two different approaches - either simple or complex - could also be characterised in the following ways:
Followers of this approach do enough to get the job done, produce well structured and readable code, and then stop.
Followers of this approach do enough to get the job done, then spend an equal amount of time in making it "purer", "holier than the Pope", making it use as many design patterns as possible, or apply as many principles as possible.
Just for your amusement I have taken my ideas on keeping software simple and essential and put it in an article called A minimalist approach to Object Oriented Programming with PHP. Hopefully my heretical views will either cause you to have an apoplectic fit or choke on your morning coffee.
Although this criticism has been aimed at me personally, it can just as well be aimed at every other developer in the world. What is my justification for saying that? For the simple reason that Nobody Agrees On What OO Is and there are too many different Definitions For OO. In my article What is Object Oriented Programming I reject the following definitions:
If you think that list of items is bad, then look at Abstraction, Encapsulation, and Information Hiding for different descriptions of each. The big problem with these different descriptions is that each description can be interpreted in a different way, and each different interpretation will be followed by its own set of different implementations. It is at that point that you start getting arguments along the lines of "MY interpretation is right, YOURS is wrong!" and "MY implementation is right, YOURS is wrong!
As well as that collection of possible definitions, there is also a large collection of possible implementation techniques which some people regard as requirements but which I dismiss as optional extras:
This list is discussed in greater detail in A minimalist approach to Object Oriented Programming with PHP. The fact that they are optional means that it is my choice whether I use them or not, and because I consider none of them to be of any value I choose not to use any of them.
If there are that many definitions of OO, and many different ways in which each definition can be implemented, isn't it rather arrogant of someone to say "My definition and implementation of OO are correct, so anything which is different must be incorrect!"
A far as I am concerned the only definition of OO which is worth any consideration is the following:
Object Oriented Programming is programming which is oriented around objects, thus taking advantage of Encapsulation, Polymorphism, and Inheritance to increase code reuse and decrease code maintenance.
As far as I am concerned OOP requires nothing more than the correct application of Encapsulation, Inheritance and Polymorphism, and if any programmer is incapable of writing effective software using nothing more than these three concepts then he/she is just that - incapable.
I have never said that my implementation is the best implementation, or the only acceptable implementation, just that it is different, and the fact that it is different should be totally irrelevant. You may not like my implementation, but as far as I am concerned it is in accordance with these definitions and the results speak for themselves.
All too often I am told that I am not using the right design patterns, or that I have not implemented them properly. It appears that far too many people judge the quality of a piece of software simply by counting the number of design patterns that it uses. This, to me, is a classic sign of pattern abuse.
In the article How to use Design Patterns there is this quote from Erich Gamma, one of the authors of the GOF book:
Do not start immediately throwing patterns into a design, but use them as you go and understand more of the problem. Because of this I really like to use patterns after the fact, refactoring to patterns.One comment I saw in a news group just after patterns started to become more popular was someone claiming that in a particular program they tried to use all 23 GoF patterns. They said they had failed, because they were only able to use 20. They hoped the client would call them again to come back again so maybe they could squeeze in the other 3.
Trying to use all the patterns is a bad thing, because you will end up with synthetic designs - speculative designs that have flexibility that no one needs. These days software is too complex. We can't afford to speculate what else it should do. We need to really focus on what it needs. That's why I like refactoring to patterns. People should learn that when they have a particular kind of problem or code smell, as people call it these days, they can go to their patterns toolbox to find a solution.
A lot of the patterns are about extensibility and reusability. When you really need extensibility, then patterns provide you with a way to achieve it and this is cool. But when you don't need it, you should keep your design simple and not add unnecessary levels of indirection.
This sentiment is echoed in the article Design Patterns: Mogwai or Gremlins? by Dustin Marx:
The best use of design patterns occurs when a developer applies them naturally based on experience when need is observed rather than forcing their use.
The GOF book actually contains the following caveat:
Design patterns should not be applied indiscriminately. Often they achieve flexibility and variability by introducing additional levels of indirection, and that can complicate a design and/or cost you some performance. A design pattern should only be applied when the flexibility it affords is actually needed.
In the blog post When are design patterns the problem instead of the solution? T. E. D. wrote:
My problem with patterns is that there seems to be a central lie at the core of the concept: The idea that if you can somehow categorize the code experts write, then anyone can write expert code by just recognizing and mechanically applying the categories. That sounds great to managers, as expert software designers are relatively rare. The problem is that it isn't true.
The truth is that you can't write expert-quality code with "design patterns" any more than you can design your own professional fashion designer-quality clothing using only sewing patterns.
In my world I will only implement a design pattern if I genuinely have the problem that the pattern was originally designed to solve. The fact that some programmers like to use them everywhere instead of where necessary is no reason why I should follow such an evil practice.
A typical example of this attitude can be found in the Sitepoint discussion at Dependency Injection Breaks Encapsulation. The original idea behind Dependency Injection, as described in Robert C. Martin's article at The Dependency Inversion Principle clearly demonstrates that it has clear benefits only when a dependency can be supplied from several sources as it moves the code which decides which of those sources to use from inside the program to outside. The key phrase here is "when a dependency can be supplied from several sources", so if I have a dependency which can only ever be supplied from a single source, without the possibility of any alternatives, then the raison d'étre for that pattern no longer exists, in which case I feel perfectly justified in not using it. Yet this simple application of logic does not work with some people, they seem to think that a pattern can be used everywhere, therefore should be used everywhere. I dislike this attitude, and I'm not the only one. In Dependency Injection Objection Jacob Proffitt writes the following:
The claim made by these individuals is that The Pattern (it can be any pattern, but this is increasingly frequent when referring to Dependency Injection) is universally applicable and should be used in all cases, preferably by default. I'm sorry, but this line of argument only shows the inexperience or narrow focus of those making the claim.
Claims of universal applicability for any pattern or development principle are always wrong.
In his article Non-DI code == spaghetti code? the author makes the following observation:
Is it possible to write good code without DI? Of course. People have been doing that for a long time and will continue to do so. Might it be worth making a design decision to accept the increased complexity of not using DI in order to maximize a different design consideration? Absolutely. Design is all about tradeoffs.
It is of course possible to write spaghetti code with DI too. My impression is that improperly-applied DI leads to worse spaghetti code than non-DI code. It's essential to understand guidelines for injection in order to avoid creating additional dependencies. Misapplied DI seems to involve more problems than not using DI at all.
The only design pattern I had in mind before writing my first line of code was the 3-Tier Architecture which I encountered in a prior language before switching to PHP. Later I read about the singleton pattern, but I did not like the implementations which I saw, so I devised one of my own. Some people say that singletons are evil, but I disagree. Other patterns just magically appeared in my code after a bit of refactoring, but that was by accident, not design (pun intended!). Among these are the following:
You may find other patterns in my code, if you look hard enough (such as Class Table Inheritance, Concrete Table Inheritance, Table Module, Active Record and the Transform View), but that's entirely up to you. You may find places where you think I should be using one of your favourite patterns, or where you think that my implementation is wrong, but I would keep those thoughts to yourself because I'm not interested.
Oh yes I am! It's just that I'm not following the same set of best practices as you are. If you took your head out of the sand and looked around you would actually be aware that there is no single document which is universally accepted as "best practice" by all developers. Even if someone had the gall to present one, I'm afraid that you would never get everyone to agree on its contents. If you typed "best practice" into your search engine you would be presented with hundreds of millions of hits, each of which gives a different opinion on what is "best". This is a subject on which there are millions of different opinions, so the idea of a consensus is nothing but a joke, a pipe dream. So if there is no single document, just 100,000,000 alternatives, how do you identify which ones to follow? How do you sort the wheat from the chaff? What happens if I choose a different set of "best practices" from you? Does that automatically make me wrong and you right?
In my long career of working in many different teams for many different organisations and with several different languages I have come across this notion of "common practice" being elevated into "best practice" which everyone else is then obliged to follow. Those who deviate from this "best practice" are automatically branded as deviants or heretics. A particular practice only becomes "common" in a particular group simply because everyone is forced to do it that way. The practice can be several years old and could have been devised by someone of average or even below-average ability. Changes in the capabilities of the language or the skill level of the current programmers is never taken into consideration. The common mantra seems to be we do it this way because we have always done it this way. Before a practice can be elevated from "common" to "best" it should really be evaluated against other practices. "Best" means "better than all the others", but if you do not know of any others then how can you possibly claim that your practice is better than them?
The big problem is that these "best practices" never originated from a single authoritative source, they have been added to and re-interpreted over several decades by any Tom, Dick and Harry with an opinion. This is like trying to combine the recipes from a multitude of different cook books and expecting the result to be a gourmet meal when in fact it is more likely to be a dog's dinner.
There is no such thing as a single unified set of best practices just as there is no single unified programming language, no single unified programming paradigm, no single unified religion or single unified political theory. What is good for one may be god-awful to another. One man's answer is another man's anathema. One man's meat is another man's poison. One man's purity is another man's putrefaction. We are each free to adopt those practices which suit us best, and that is what I will continue to do whether you like it or not.
In his article The Dark Side of Best Practices Petri Kainulainen writes:
When best practices are treated as a final solution, questioning them is not allowed. If we cannot question the reasons behind a specific best practice, we cannot understand why it is better than the other available solutions.
If best practices get in the way, we should not follow them. This might sound a bit radical, but we should understand that the whole idea of best practices is to find the best possible way to develop software. Thus, it makes no sense to follow a best practice which does not help us to reach that goal.
Later in the same article he says the following:
In the end, best practices are just opinions. It is true that some opinions carry more weight than others but that doesn't mean that those opinions cannot be proven wrong. I think that it is our duty to overthrow as many best practices as we can.
Why?
It helps us to find better ways to do our job.
The only "best practices" which I follow are the bare essentials which can be described as being universally applicable such as:
When other people go beyond these bare essentials and attempt to impose additional rules which go down into more and more levels of nit-picking detail then I consider that they have crossed the line and are moving into forbidden territory. They are moving from universally applicable to personal preferences and I find this level of interference more likely to cause friction than to solve real-world problems, so I feel justified in ignoring such petty and ridiculous rules altogether. Examples of such petty rules which I love to ignore are:
Here are some other articles which question the idea of "best practices":
It is often said that arguments about which programming style is best are on the same level as which religion is best as they are both based on bigotry, which is defined in wikipedia as follows:
It refers to a state of mind where a person is obstinately, irrationally, or unfairly intolerant of ideas, opinions, or beliefs that differ from their own, and intolerant of the people who hold them.
If you examine the origins of all the old religions you should see that they all had a common theme, which was to convert chaos into order, to identify what makes a "good citizen". This was done by creating a set of rules or commandments such as "Thou shall not kill", "Thou shall not steal" and "Thou shall not bear false witness". The essence of all these rules can be summed up in a single sentence:
Do unto others as you would have them do unto you.
If you examine the origins of computer methodologies or styles you should see a similar theme - to bring order from chaos, to identify what makes a "good programmer". The earliest set of rules identified such things as "use meaningful names for both functions and variables" and "create a program structure where the flow of logic is easy to follow and understand". The essence of all these rules can be summed up in a single sentence taken from the The Structure and Interpretation of Computer Programs written in 1985 by by H. Abelson and G. Sussman:
Programs must be written for people to read, and only incidentally for machines to execute.
Whilst a religion starts off with a sound and reasonable objective - how to be a good citizen - this is not good enough for some people who say "These rules were handed down to us by <enter deity of choice>. You can only worship <enter deity of choice> through us, you can only have an afterlife if you follow our rules, and to make us more important than we really are we will invent more rules". Thus they invent supplemental and totally artificial rules which dictate how to pray, when to pray, where to pray, what direction you should face while praying, what to wear, et cetera, ad infinitum, ad nauseam. Some of these people become extremists who believe that anyone who does not follow their religion is a heretic who should be punished most severely. It then becomes possible for the followers of a religion to obey the petty and artificial rules, which leads them to believe that they will ascend to heaven, yet they totally ignore the original purpose of that religion which was to help turn them into "good citizens" instead of barbarians. The world is full of religious fanatics who regularly pray to their deity, then go out and kill in the name of that deity. Whatever happened to "Thou shall not kill"?
The world of computer programming, in particular Object Oriented Programming, has also seen the rise of a similar "priesthood", a group of people who love to invent their own sets of supplemental and totally artificial rules for no other purpose than to make themselves appear to be superior in the eyes of the layman, the ordinary programmer. They issue diktats on trivial issues such as tabs vs spaces, camel case vs snake case, where to put curly braces, SOLID principles, the over-use of design patterns, et cetera, ad infinitum, ad nauseam. These people see themselves as the "paradigm police" whose sole purpose is to root out those who are not following their rules and to brand them as heretics. They claim that your software will not have a successful afterlife (i.e. have value in the market place) unless you worship at their alter and follow their rules. It then becomes possible for their followers to obey these petty and artificial rules, which leads them to believe that any software which they produce will automatically be "good". Yet they fail to realise that what they have produced is an over-engineered mess which has too many levels of indirection, which has become fragmented instead of modular, and which makes it far more difficult to read and understand, and therefore more difficult to maintain. This means that they have completely lost sight of the original rules which were supposed to turn them into "good programmers" instead of code monkeys.
Just like the religious fanatics who believe that the only way to get into heaven is to follow their religion, the OO fanatics believe that the only way to produce good software is to follow their version of "best practices". This leads them to believe that any programmer who does not follow their practices cannot produce software which is anything other than crap. This attitude is completely and utterly wrong, and is the product of a deranged mind. Just as it is possible for a person to follow a set of religious practices without being a "good citizen", it is possible for a programmer to follow a set of programming practices and still not produce "good software" which is readable and maintainable. The opposite is also true - it is possible for a person to completely ignore, or be totally unaware of, a particular set of religious practices and still be a "good citizen", and it is possible for a programmer to completely ignore, or be totally unaware of, a particular set of programming practices and still produce "good software".
Unlike religions, where the promise of an afterlife cannot be guaranteed (or even its existence be proved), in software development the "afterlife" is when that software moves from the hands of the developer into the hands of end-user, the paying customer. What matters to the customer is functionality, speed of development, and cost of development. If two pieces of software provide the same functionality, and one was written "properly" to a set of extremist rules, but at twice the cost and twice the time of the other which was written "improperly" to a set of moderate rules, which do you think will be more appreciated by the customer? In the real world it is Return On Investment (ROI) - more bang for your buck - which is the deciding factor, not programming purity. Customers do not (or should not) care about which development techniques were used, just that the result is cost-effective.
Both religious fanatics and OO fanatics rely on too much dogma and too little common sense, which means that they put the following of rules in front of the results which are supposed to be obtained. A pragmatist, on the other hand, will concentrate on the results and ignore any artificial rules which get in the way. A pragmatist will reserve the right to question any rule whereas a dogmatist will not allow his rules to be questioned.
Another problem with dogmatists is that, as well as arguing with pragmatists, they even argue amongst themselves about who's interpretation or implementation is the most pure. They each think that their opinion is the right one, which leads to a lot of Holier-Than-Thou or More Catholic than the Pope arguments.
I am a pragmatist, not a dogmatist, so I put all my efforts into producing the best result that I can instead of blindly following some artificial and restrictive rules and assuming that the result will automatically be the best.
In his article Are You There, God? It's Me, Microsoft Jeff Atwood says the following:
Religion appears in software development in numerous incarnations-- as dogmatic adherence to a single design method, as unswerving belief in a specific formatting or commenting style, or as a zealous avoidance of global data. Whatever the case, it's always inappropriate.
Blind faith in one method precludes the selectivity you need if you're to find the most effective solutions to programming problems. If software development were a deterministic, algorithmic process, you could follow a rigid methodology to your solution. But software development isn't a deterministic process; it's heuristic, which means that rigid processes are inappropriate and have little hope of success. In design, for example, sometimes top-down decomposition works well. Sometimes an object-oriented approach, a bottom-up composition, or a data-structure approach works better. You have to be willing to try several approaches, knowing that some will fail and some will succeed but not knowing which ones will work until after you try them. You have to be eclectic.
Here are some other articles which explore the idea of software development and religious wars:
My critics fail to understand that sometimes I don't follow a particular practice/principle/rule simply because it is not appropriate for the type of applications which I develop. This could either make that practice completely redundant, and thus a violation of YAGNI, or produce a result which is not as optimum as it could be. If I can find a way that is better than your "best" then surely I should be applauded and not admonished.
Note that the sole measurement for judging what is "best" should be "that which produces the best results". This means that the software should be cost-effective so that where several pieces of software have the same effect the one with the lowest cost should always be regarded as being better. Note that "cheaper but less effective" does not qualify. With software development it is the cost of the developers time which is a crucial factor, and the best way to reduce the amount of time taken for a developer to write code is to write less code, which in turn can be achieved by utilising as much pre-written and reusable code as possible. Since the stated aim of OOP is to increase code reuse and decrease code maintenance
then any practice which encourages the production of reusable code should be regarded as being better than any practice which does not. I encourage you to read Designing Reusable Classes which was published in 1988 by Ralph E. Johnson & Brian Foote for ideas on how this can be achieved.
Simply following a series of rules or common/standard practices is not enough on its own. Following rules blindly in a dogmatic fashion and assuming that the results you achieve will be the same as those achieved by others is the path to becoming nothing more than a Cargo Cult Programmer. You have to analyse a problem before you can design a solution, then you need to decide which practices to apply and how to apply them in order to achieve the best results. By "which practices" I mean that some rules or practices may be inappropriate for various reasons. Trying to build a modern web-based database application using practices which were created by people who had little or no experience with such applications is unlikely to set you on the path to success. Most of the rules, practices and principles which I have encountered were written in the 1980s by academics using the Smalltalk language, or something similar, but how many of these people used these languages to write enterprise applications with hundreds of tables and thousands of screens? Also, practices designed for programs using bit-mapped displays are not relevant for modern programs which use HTML forms.
Below are some the rules, principles and practices which I consider to be inappropriate, so I ignore them:
favour composition over inheritancewas devised by someone who didn't know how to use inheritance properly, which creates problems. The solution is to avoid deep inheritance hierarchies and to only inherit from an abstract class. Refer to Composite Reuse Principle for more of my thoughts on this matter.
program to the interface, not the implementationis meaningless as you cannot simply call an interface, you must call a method on an object which actually implements that interface. I have yet to see a code sample which proves that this idea has merit, and until I do I will dismiss it as bogus. If this is supposed to mean calling a method on an unknown object where the identity of that object is not provided until runtime, then as a description of how to use polymorphism is is pretty pathetic.
software entities should be open for extension, but closed for modificationimplies that, once deployed, you should not modify an object but extend it (using "extends" to create a subclass?), which sounds like it creates more problems than it solves. In the life of my framework I have performed numerous refactorings, and if I was forced to put each update in a separate subclass I would also have to change all references of the original class to the updated subclass. Refer to Open/Closed Principle for more of my thoughts on this matter.
depend upon abstractions and not concretionsis vague because there are so many different interpretations of the word abstraction. It took me years to realise that what this meant was to define methods in an abstract class which could then be inherited by numerous subclasses, thus providing polymorphism, which then gives you the ability to swap from one subclass to another at run time. But what if I don't have multiple subclasses? Refer to Dependency Inversion Principle for more of my thoughts on this matter.
each software module should have one and only one reason to change, but "reason to change" was found to be so inadequate and confusing that Uncle Bob had to produce a follow-up article to explain that what he meant was the separation of GUI logic, business logic and database logic. This is, in fact, the same thing as the 3-Tier Architecture which is less confusing to implement as it has a more precise and less ambiguous definition.
It should be obvious to every OO programmer that shared method names offer polymorphism while unique method names do not. Polymorphism provides the opportunity for more reusable code as it enables Dependency Injection.
it should not be possible for an object to exist in an inconsistent statewhere the word "state" is mistakenly taken to mean the data within an object when it actually means the condition of an object. The ONLY absolute rule regarding constructors is that after being executed the constructor should leave the object in a condition which will allow any of its public methods to be called. My full response to this schoolboy mistake can be found in Re: Objects should be constructed in one go.
PHP was created to make it easy to create dynamic web applications, those which have HTML at the front end and an SQL database at the back end. I was involved in writing enterprise applications (database applications for commercial organisations) for 20 years before I switched to using PHP, so I knew how they worked. I had even created frameworks in two of those languages. All I had to do was to convert my latest framework to use PHP and the OO features which it offered in order to create as much reusable software as possible. The structure of my RADICORE framework can be pictured in Figure 4 below:
Figure 4 - A combination of the 3-Tier Architecture plus MVC
")
There is also a more detailed version available in Figure 1. This shows that the RADICORE framework uses a combination of the 3 Tier Architecture, with its separate Presentation layer, Business layer and Data Access layer, and the Model-View-Controller (MVC) design pattern. The following amounts of reusability are achieved:
Note also that any Controller can be used with any Model (and conversely any Model can be used with any Controller) because every method call made by a Controller on a Model is defined as a Template Method in the abstract class which is inherited by every Model. This means that if I have 45 Controllers and 400 Models this produces 45 x 400 = 18,000 (yes, EIGHTEEN THOUSAND) opportunities for polymorphism and therefore Dependency Injection.
I was able to produce a single View module which can produce the HTML output for any transaction as a result of my choice to use XSL Transformations and a collection of reusable XSL Stylesheets. This is coupled with the fact that I can extract all the data from a Model with a single call to $object->getFieldArray() instead of being forced to use a separate getter for each column, as discussed in Getters and Setter are EVIL.
There are some people who seem to think that as soon as a new feature becomes available in the language then all developers should immediately rush out and refactor all of their code for no good reason other than to appear current, fashionable, and not behind the times. They fail to understand that most new features are introduced in order to solve a particular problem, but if your code does not have that particular problem then it does not have any need for that particular feature. Also, as a fully paid-up member of the if it ain't broke, don't fix it brigade, I find it more cost-effective to spend my time on things that need my attention (read: earn me more revenue) than things that don't.
As a prime example take the introduction of autoloaders. The problem which this feature addresses is described in the opening paragraph as follows:
Many developers writing object-oriented applications create one PHP source file per class definition. One of the biggest annoyances is having to write a long list of needed includes at the beginning of each script (one for each class).
Not only do I never have to write a long list of includes at the beginning of each script, I never have to write any include statements at all, so I have absolutely nothing to be annoyed about. I don't have this problem, so I don't need this solution. While I do have some include/require statements scattered around my framework, some of them are for files of procedural functions, not classes, so they cannot be covered by autoloaders and are therefore irrelevant. When I generate application components using my framework I never have to write a single include/require statement as they are already built into the framework's components. Should I need to access an additional object then I use my singleton class which makes use of the old fashioned include_path directive.
This is not good enough for the paradigm police. They seem to think that autoloaders were introduced with the sole purpose of replacing every include/require statement, so wherever my code uses an include/require statement then I should feel obligated to immediately remove it and use an autoloader instead. This would require refactoring my code for no obvious benefit, so I cannot justify the effort required to undertake such a pointless exercise.
Another example is the use of namespaces which some people are now saying should be added to the PHP core as well as being a necessity within every PHP application. These people cannot read otherwise they would see that this would be a violation of YAGNI. The reason for the addition of this feature is clearly stated in the manual as follows:
In the PHP world, namespaces are designed to solve two problems that authors of libraries and applications encounter when creating re-usable code elements such as classes or functions:
- Name collisions between code you create, and internal PHP classes/functions/constants or third-party classes/functions/constants.
- Ability to alias (or shorten) Extra_Long_Names designed to alleviate the first problem, improving readability of source code.
Note that the primary audience is stated as authors of libraries
whose code may be plugged into an unknown application containing unknown source code with an unknown naming convention. To an intelligent person this should automatically exclude the following:
So why change your code to take advantage of a feature when that feature is inappropriate and unnecessary? That would not appear to be the action of an intelligent person. This topic is also discussed in Is there a case for adding namespaces to PHP core?
How many of you, when the short array syntax was introduced in version 5.4, immediately rushed out and refactored your code to replace all instances of the "old" syntax with the "new" alternative? According to the paradigm police you don't have a choice in the matter - a new feature has become available, so you are obliged to use it whether it has any benefits or not.
I personally find this attitude quite childish. I earn my living by selling licences for my enterprise application to large corporations, and by providing customisations, support and training, so once I have written a piece of code and released it to my customers then I don't look at it again until I have a very good reason, such as to fix a bug or include an enhancement. Unnecessary refactoring is not the kind of work where I can pass off the costs to my customers as there would be no visible benefit. If I have the choice between doing unnecessary work that earns me nothing and working on a client's project which is going to pay me tens of thousands of pounds, then which one do you think I would put first?
I am not the only one who thinks that using the latest features in the language simply because they are shiny and new may not actually be a good idea. This is known as the Magpie Syndrome and is discussed by Matt Williams in his article as well as Does Your Team Have STDs?
I write code which is functional, not fashionable. Fashions come and go with alarming regularity, but software which performs useful functions will always have a market place. Customers are more appreciative of software which performs useful functions and do not care one jot about the style in which it was written. When it comes to writing software which ticks all the right boxes I'm afraid that the views of the paying customers have greater priority with me than the views of the "paradigm police".
When my critics hear that, rather than being a relative newcomer to the programming world, I spent several decades working with other languages such as COBOL and UNIFACE before switching to PHP in 2002, they immediately accuse me of being a dinosaur who is stuck in the past, or a Luddite who is resistant to technological change. The facts say otherwise. My first encounter with a web application was a complete disaster as UNIFACE was not designed for web development, so what did I do? A true Luddite would have stuck to the old technology and resisted the new, but I did the exact opposite. I taught myself HTML and CSS to see what it could do, then searched for a language which was built for web development and was easy to learn. I chose PHP, and this is a choice that I have never regretted. I encountered XML while working with UNIFACE, and I learned of XSL transformations, but whereas UNIFACE could not generate web pages using XML and XSL I quickly learned that PHP could, so I rebuilt my UNIFACE framework in PHP and got it to produce all its web pages from a library of reusable XSL stylesheets. My framework started with Role Based Access Control, but then I added in Audit Logging and an activity based Workflow system. I later designed and built a Data Dictionary which included the ability to generate class files and user transactions from my catalog of Transaction Patterns.
So rather than resisting a change in technologies I actually embraced it and redeveloped my old framework so that I could continue to develop enterprise applications, but in the new way. Your complaint is actually something else entirely - it concerns the techniques which I have used to implement the new technologies and not the technologies themselves. You are acting on the erroneous assumption that "there is only one way to do it, and I'm going to tell you what that is". Programming is an art, not a science. It relies on a person's creativity and not the blind following of sets of pre-conceived rules. If you give the same problem to 100 different programmers you will get 100 different solutions. Some of the differences may be small, but others could be huge. Why is this? Each of us is an individual, with an individual way of thinking. We can look at the same problem and perceive it in different ways, which leads us to devise different solutions which we then try to implement in our own individual ways. By telling me that I must not be different you are attempting to stifle my creativity in order to maintain the status quo, in order to protect your ideas from being revealed as not the best after all. Progress cannot be made by doing the same old thing in the same old way. Progress is made through innovation, not imitation, and the first step on the road to progress is to try something different.
So stop telling me that I am not allowed to be different as your words are falling on deaf ears.
The following are from an article which I wrote in December 2003 called What is/is not considered to be good OO programming:
The following are from an article which I wrote in November 2004 called In the world of OOP am I Hero or Heretic?:
The following are from an article which I wrote in December 2004 called Object-Oriented Programming for Heretics:
The following are from an article which I wrote in December 2006 called What is Object Oriented Programming (OOP)?:
My critics, of which there are many, constantly accuse me of being a bad programmer for no other reason that I refuse to follow their personal ideas of what constitutes "best practice", or that I prefer to use a different coding style to theirs. They completely ignore the fact that my software works, is more productive than theirs has more features than theirs, and is readable and maintainable for the simple reason that I have been maintaining and enhancing it for over 10 years. The biggest problem lies with the fact that they when they start applying a particular principle they simply do not now when to stop, or that their interpretation of the principle is so misguided that it becomes absolute nonsense. In some cases these people present such ridiculous ideas that are so off-the-wall that I have to question their sanity. Below are some of their crackpot theories.
This idea was first proposed in this post in which s_molinari said:
Tony MarstonAgain, you are confusing SoC with SRP or rather using SoC to support your usage of a monster class, which is totally off.
What he is clearly saying there is that you should separate out all GUI logic, Business logic and Data Access logic which is precisely what I have done by virtue of the fact that my framework is based on a combination of the 3-Tier Architecture and the MVC design pattern.
In this post he said:
You are again talking about SoC and not SRP. They are different. One is about the architectural split of main tasks or services within a software and the other is about single reason for change within a class.
In this post he said:
Tony MarstonSo now you are mixing up SoC with SRP? Come on Tony. Stick to SRP please.
I disagree. In Uncle Bob's article at Test Induced Design Damage? it says the following ...
In this post in another discussion he said the following:
Tony thinks separation of concerns and SRP are one and the same. So, because his framework follows MVC, thus obeying SoC, all of it then automatically obeys SRP too.
The contradiction he accuses Bob of making comes from his clear misunderstanding of the two concepts, which differ only in scope basically. SoC's scope is at a higher framework/ application level. Like...separation of concerns between areas of the framework and application to split them up in logical parts, so they are more modular, reusable and easier to change.
SRP's scope is at the lower class level. It describes how classes should be formed, so they are also more modular, reusable and easier to change. The goals of both concepts are the same, however, you can't always say you have successfully complied with SoC and it directly means you have properly done SRP too.
If you see the two concepts like that, then everything Bob has said makes perfect sense and we are back to Tony's 9000 line class breaking SRP.
This idea strikes me as being totally ridiculous as both principles are about splitting a large monolithic piece of code, where several concerns/responsibilities are tangled together, into smaller parts where each part then contains only a single concern/responsibility. The only difference between the two descriptions is that they use different words,but to any reasonable person the terms "concerned with" and "responsible for" mean exactly the same thing. If the results of applying either of these two principles are exactly the same then how exactly are they different? Take these two articles written by Robert C. Martin (Uncle Bob). In Test Induced Design Damage? he writes:
How do you separate concerns? You separate behaviors that change at different times for different reasons. Things that change together you keep together. Things that change apart you keep apart.
GUIs change at a very different rate, and for very different reasons, than business rules. Database schemas change for very different reasons, and at very different rates than business rules. Keeping these concerns (GUI, business rules, database) separate is good design.
In The Single Responsibility Principle he clearly recognises that the two terms are interchangeable:
This is the reason we do not put SQL in JSPs. This is the reason we do not generate HTML in the modules that compute results. This is the reason that business rules should not know the database schema. This is the reason we separate concerns.
Later in the same article he also said the following:
Another wording for the Single Responsibility Principle is:
Gather together the things that change for the same reasons. Separate those things that change for different reasons.If you think about this you'll realize that this is just another way to define cohesion and coupling. We want to increase the cohesion between things that change for the same reasons, and we want to decrease the coupling between those things that change for different reasons.
In the first article he is talking about "concerns" and in the second it is "concerns/responsibilities", but the end result is exactly the same - all GUI/HTML logic is separated out from the computations/business rules, as is all the database/SQL logic. The two terms mean the same thing, they are interchangeable, there is no difference. Anyone who says otherwise is talking out of the wrong end of his alimentary canal.
In his book Agile Principles, Patterns, and Practices in C# Robert C. Martin wrote about the SRP: The Single Responsibility Principle in which he said the following:
If a class has more than one responsibility, then the responsibilities become coupled. Changes to one responsibility may impair or inhibit the class? ability to meet the others. This kind of coupling leads to fragile designs that break in unexpected ways when changed.
Later on when talking about the Rectangle class he says the following:
This design violates the SRP. The Rectangle class has two responsibilities. The first responsibility is to provide a mathematical model of the geometry of a rectangle. The second responsibility is to render the rectangle on a graphical user interface.
Under the heading Persistence he says the following:
Figure 8-4 shows a common violation of SRP. The Employee class contains business rules and persistence control. These two responsibilities should almost never be mixed. Business rules tend to change frequently, and although persistence may not change as frequently, it changes for completely different reasons. Binding business rules to the persistence subsystem is asking for trouble.
Here he is saying quite clearly that GUI logic, business logic and persistence (database) logic are different responsibilities and should therefore be split into separate classes, one for each. Nowhere does he say that a responsibility should be split into multiple classes so that option is entirely up to the developer.
It is also important to note that, although this article uses "reason to change" to identify different responsibilities, there may actually be a valid reason not to put each responsibility in its own class:
If, on the other hand, the application is not changing in ways that cause the two responsibilities to change at different times, then there is no need to separate them. Indeed, separating them would smell of Needless Complexity.
There is a corollary here. An axis of change is only an axis of change if the changes actually occur. It is not wise to apply the SRP, or any other principle for that matter, if there is no symptom.
What he is saying here is that you should not go too far by putting every perceived responsibility in its own class otherwise you may end up with code that is more complex than it need be. You have to strike a balance between coupling and cohesion, and this requires intelligent thought and not the blind application of an academic theory.
In this post TomB stuck his oar in with this comment:
Again this goes back to your misuse of SRP/SoC. In this scenario a component fulfils a concern, that component may be made up of many classes. SRP is applied at a class level, not a component level. This has been explained to you by Scott and others on at least a dozen occasions.
Let's put it this way: If SRP and SoC are the same thing, why do they have different wikipedia pages?
There are two articles for the simple reason that two people came up with different names for the same idea. If you bothered reading those articles you would see that each contains a reference to the other. The article on SoC also contains an external reference to The Art of Separation of Concerns which says the following
The Principle of Separation of Concerns states that system elements should have exclusivity and singularity of purpose. That is to say, no element should share in the responsibilities of another or encompass unrelated responsibilities.
Separation of concerns is achieved by the establishment of boundaries. A boundary is any logical or physical constraint which delineates a given set of responsibilities. Some examples of boundaries would include the use of methods, objects, components, and services to define core behavior within an application; projects, solutions, and folder hierarchies for source organization; application layers and tiers for processing organization; and versioned libraries and installers for product release organization.
Though the process of achieving separation of concerns often involves the division of a set of responsibilities, the goal is not to reduce a system into its indivisible parts, but to organize the system into elements of non-repeating sets of cohesive responsibilities. As Albert Einstein stated, "Make everything as simple as possible, but not simpler."
In that article it uses the word "responsibility" over 20 times, so in that author's mind there is NO distinction between "concern" and "responsibility". The two words mean the same thing, they are interchangeable, they are NOT different. I actually posted a question to that article in which I specifically asked if "concern" and "responsibility" meant the same thing or were different, and if Separation of Concerns meant the same thing as Single Responsibility Principle, and this was his reply:
A responsibility is another way of referring to a concern. The Single Responsibility Principle is a class-level design principle that pertains to restricting the number of responsibilities a given class has.
It is quite clear to me that he is saying that the two terms mean the same thing, that they are NOT different. Note that both my question and his response have been deleted from that article's comments section.
In the book Pattern-Oriented Software Architecture - A System of Patterns it states the following:
Separation of Concerns
Different or unrelated responsibilities should be separated from each other within a software system, for example by attaching them to different components. Collaborating components that contribute to the solution of a specific task should be separated from components that are involved in the computation of other tasks. If a component plays different roles in different contexts these roles should be independent and separate from each other within the component. Almost every pattern of our pattern system addresses this fundamental principle in some way. For example, the Model-View-Controller pattern separates the concerns of internal model, presentation to the user and input processing.
How can you read that and claim that "concern" and "responsibility" mean different things? Where is a description of this difference?
Eventually Dave Maxwell posted a comment which supported my view in which he said the following:
Can we PLEASE get over talking semantics and "Letter of the Law"? From a high level, they are the same concept. SRP might have a slightly more narrow definition of successful compliance as it's essentially SoC 2.0, but from a basic, mile high perspective, they are the same,
Thank you, Dave. The cheque's in the post.
This idea came to light in this post in which TomB said:
Your abstract class has methods which are reusable only to classes which extend it. A proper object is reusable anywhere in the system by any other class. It's back to tight/loose coupling. Inheritance is always tight coupling.
Where did you get such a rubbish idea? My use of an abstract class is perfectly valid because:
If you do not understand how and when to use an abstract class I suggest you read Designing Reusable Classes which was published in 1988 by Ralph E. Johnson & Brian Foote. In it they state that when you have several concrete classes which share the same set of common protocols (methods) then you place those common protocols in an abstract class so that they can be inherited/shared by each one of those concrete classes. This is why I have an abstract table class which is inherited by hundreds of concrete table classes as they all share the same CRUD methods. The use of an abstract class then enables the use of the Template Method Pattern which is an essential pattern for use in frameworks as it allows concrete subclasses to contain nothing by customisable "hook" methods. The correct use of inheritance therefore solves more problems than it creates.
In this post he said the following:
And you again prove you don't know what coupling is.
In this post he said:
Of course it can, most easily by looking at coupling. Tight coupling is by definition less flexible than loose coupling.
This was closely followed by a reference to Software Quality Metrics for Object-Oriented Environments (PDF) to support his claim. In post #342 I answered as follows:
The ORIGINAL definition of coupling is defined thus
In software engineering, coupling is the manner and degree of interdependence between software modules; a measure of how closely connected two routines or modules are; the strength of the relationships between modules.This is clearly limited to when one module calls another, not when one class inherits from another. The fact that some people have chosen to use the word "coupling" to describe the effects of inheritance is a silly mistake on their part. This is just as silly as the notion that inheritance breaks encapsulation.
If you bothered to read that article which you cited you would have read the following:
Classes (objects) are coupled three ways:This quite clearly states that when examining code using various metrics that the effects of inheritance can be ignored.
1. When a message is passed between objects, the objects are said to be coupled.
2. Classes are coupled when methods declared in one class use methods or attributes of the other classes.
3. Inheritance introduces significant tight coupling between superclasses and their subclasses.
Since good object-oriented design requires a balance between coupling and inheritance, coupling measures focus on non-inheritance coupling.
This problem boils down to the fact that the word "coupling" has been used in two different situations:
In the first situation the coupling can be regarded as either tight or loose depending on the skill of the programmer, where loose coupling is considered to be better.
The second situation is brought about simply by using the word "extends" and cannot be varied between tight and loose. There are no such things as "loose inheritance" and "tight inheritance", there is either inheritance or there is not. To say that inheritance always produces tight coupling and tight coupling should be avoided is saying that to be a "good" OO programmer you should avoid using one of the mainstays of OO. What a load of rubbish!!!
Whereas the first usage can be affected by the programmer's skill and can be used to measure software quality, with inheritance the situation is entirely different and for the purposes of measuring software quality can be completely ignored. That academic article says so in black and white, so who am I to argue?
It would have been better if the second description had used a word such as "combined" instead of "coupled" as in inheritance combines a subclass with a superclass instead of inheritance tightly couples a subclass with a superclass, then the possibility for confusion would have been greatly diminished.
This idea came to light in this post in which TomB said:
Tony MarstonExcellent then you also have broken encapsulation. You've quoted this exact definition before:
Wrong. That is a variable in the Model which is passed to the View object which is responsible for the production of CSV files.
All your accusations are wrong. Those are simply variables which are defined in the Model but which are passed to other objects for the actual processing. It is these other objects which contain the logic which deals with the contents of those variables so to say that my Model class contains too much logic is completely bogus.
Tony MarstonYou have just said you have the data in the model and the functions in the view. The data and functions are in different components. So that's two for two.
Encapsulation is the packing of data and functions into a single component. The features of encapsulation are supported using classes in most object-oriented programming languages, although other alternatives also exist. A language construct that facilitates the bundling of data with the methods (or other functions) operating on that data.
Here he is saying that I have used SRP to separate my View logic from my Business logic, and that I have ended up with variables in my Model which are passed to the View for processing. This then breaks encapsulation because I have data in one object and the code which operates on that data in a different object. He reinforces this idea with what he later says in post #133:
I clearly said you broke encapsulation by separating the data and the methods that work on that data. The data is in the model and the methods that work on the model is in the view: Encapsulation has been broken. I'm suggesting you have a poor separation of concerns.
I have not separated the data and the methods that work on that data. By this I define "work on" as "apply the business rules" which always takes place in the Business/Domain layer. What you are talking about are the methods which "transform that data into another format" which only exist in the Presentation layer. There are other methods which "move the data into and out of the database" which only exist in the Data Access layer. Putting these methods into different objects does not violate encapsulation (unless you have a perverted definition of encapsulation), neither does it violate SRP as it follows what the author wrote when he said Keeping these concerns separate is good design
.
When the View object is run it may require some information which is in addition to the raw application data which is found in $fieldarray. When it requires this information it calls a specific method in the Model which asks the question Can you supply a value for XXX please
where XXX could be something like the following:
$pdf_destination - can be set to I=Inline (browser), D=Download (browser), F=Filename (on server), S=String$no_csv_header - can be set to TRUE so that when the CSV file is created the first row does not contain any column headings.$upload_subdir - the directory into which files are to be uploaded.The fact that the Model contains methods which supply additional information required by the View does not mean that the Model contains Presentation logic. It is doing nothing more than supplying data, and the code which processes this data, the logic, exists in the View.
In various different posts I have either been accused of twisting the meaning of words, or of using wild interpretations. I invite you to examine each of these accusations to see who is being the sensible moderate and who is being the wild extremist.
For example, in this post in which s_molinari said that my use of one class each for the MVC design pattern was wrong:
Tony Marston:First of all, the MVC patterns/ architecture says nothing about classes in particular at all. This is obviously another one of your misunderstandings or twisting of facts to fit your prerogatives.
Why should I need more than three? The MVC pattern only mentions three, so why should I need more than that?
Secondly, you need more than three classes, because a view, or a controller or a model aren't singular responsibilities, but rather main concerns within the application's architecture. To me, overall, the MVC pattern is the main behavior an MVC framework offers. Each one of the 3 MVC concerns also have a good number of objects and tasks needed to achieve the goals of the framework and the application. These objects and tasks are the responsibilities.
It looks like you are mixing up the concerns of MVC and understanding them as single responsibilities. This is why your framework is missing out on class fidelity ( a term I just coined myself).
class fidelity - when an experienced programmer new to an application can relatively easily determine the single responsibilities of classes.
I certainly do not think that I am the one who is twisting the meaning of words here. The MVC design pattern specifically describes three components, each of which is concerned with (or responsible for) a separate aspect of the application, so it is reasonable to assume that in an OO language each of these components would require its own class/object. Only an unreasonable person would assume otherwise. I would agree that 3 classes is the minimum number required to implement MVC, but you do not have the right to say that it should have much more than three. As a practitioner of the art of minimalism I will always stick to the minimum unless I have good reason to do otherwise. In my framework I have actually split the Model into two so that all database access is in a separate class. Why did I do this? Because it is a requirement of the 3-Tier Architecture, that's why.
Saying that the Model, View and Controller are separate concerns, but need to be broken down into even smaller classes to cover the separate responsibilities within each concern is just plain gobbledegook. I have yet to find any examples of MVC implementations on the internet which support this crazy notion.
Continuing his argument that MVC requires more than three classes in this post s_molinari posed a challenge:
I challenge you to find just one framework that has MVC architecture and does it with only three main classes and no serious sub-classing.
In this post I pointed to an article written by his fellow crackpot TomB:
How about this one https://r.je/mvc-tutorial-real-application-example.html
There is also http://www.sitepoint.com/the-mvc-pattern-and-php-1/ and http://code.tutsplus.com/tutorials/mvc-for-noobs--net-10488, so that proves that I am not the only one who thinks that MVC requires no more than one class for each of the three components.
In this post TomB attacked my assumption that, in order to follow Robert C. Martin's advice in Test Induced Design Damage? I would only need three classes to implement his separation of GUI logic, business logic and database logic. His words were:
If all logic is in the same component, it doesn't necessarily mean the same class! (In fact it most certainly does not in most cases!). So yes, all GUI code should be in its own COMPONENT but that component can (And should if we follow SRP) be split into sub-components, or submodules as you just referred to them.
Again this goes back to your misuse of SRP/SoC. In this scenario a component fulfils a concern, that component may be made up of many classes. SRP is applied at a class level, not a component level. This has been explained to you by Scott and others on at least a dozen occasions.
Here he is trying to say that a "responsibility" is a subcomponent of "concern" despite the fact that I had previously pointed him to a second article written by Robert C. Martin called The Single Responsibility Principle in which he describes the exact same separation of GUI logic (HTML), business logic (compute results) and database logic (SQL). In this article he switches between using the term "responsibility" and "concern" in a manner which would make a reasonable person assume that they meant the same thing. Uncle Bob used the two terms to describe the same concept, and he certainly did not say that they were different, which is what I stated in this post.
I have yet to see any definition of Separation of Concerns which states that, after identifying a "concern", this should then be broken down into multiple classes, one for each "responsibility". Uncle Bob certainly did not say such a thing, and if you read his two articles at https://blog.cleancoder.com/uncle-bob/2014/05/08/SingleReponsibilityPrinciple.html and https://drive.google.com/file/d/0ByOwmqah_nuGNHEtcU5OekdDMkk/view you will clearly see that after identifying separate responsibilities he puts each into its own class, not a group of classes. To any reasonable person in the software world when you talk about splitting a large something into its constituent parts, each smaller part can have various names such as "component", "subcomponent", "program", "subprogram", "subroutine", "module", "function", "class" or "method". They are different words, yet they mean the same thing. I have not seen it written anywhere that in a piece of software a "component" is different from a "class".
In this post TomB tried to criticise my use of the word "component", that it does not mean a single class but a collection of classes:
And now you're redefining the term "component". From wikipedia ( https://en.wikipedia.org/wiki/Component-based_software_engineering )
Software components often take the form of objects (not classes) or collections of objectsAlternatively, this definition from Berkeley University ( http://www.eecs.berkeley.edu/newton/Classes/EE290sp99/lectures/ee290aSp994_1/tsld009.htm )
A software component is a unit of composition with contractually specified interfaces and explicit context dependencies only. A software component can be deployed independently and is subject to composition by third partiesinterfaceS, dependencieS. A component is not a single class.
I replied in this post:
Don't be silly. The word "component" means "constituent part" and can also be referred to as "module". A module can also be made of sub-modules. In software a high-level component can be a user transaction, and each transactions may be comprised of other modules or components which in OOP would be objects or functions. These are simply different words for the same thing.
He tried a different argument in this post:
Software component has a specific meaning in computing which has no relation to classes.
I replied in this post:
I am limiting myself to words in the English language which are now used in the world of software development. If the English dictionary states that "component" means "constituent part" then it is totally WRONG for you to say that in software development "component" does NOT mean "constituent part".
In this post TomB tried to reinforce his opinion that each class encapsulates a single responsibility but not a single concern:
Robert C. Martin said this in the book Clean Code.
To restate the former points for emphasis: We want our systems to be composed of many small classes, not a few large ones. Each small class encapsulates a single responsibility, has a single reason to change, and collaborates with a few others to achieve the desired system behaviors.
He is saying that each class should be small enough to encapsulate a single responsibility, but he is NOT putting a limit on the number of methods or the number of properties. He has previously defined a "responsibility" as being an area of logic such as GUI logic, business logic or databases logic, which is EXACTLY what I have done. Each Model class, which inherits from my "monster" abstract class, is responsible for the business logic associated with a single database table, so IMHO it meets the criteria for "single responsibility". If you were to create a class which was responsible for multiple database tables then that would have multiple responsibilities and would break SRP.
I actually have a copy of that book, and after reading it cover-to-cover all that I can say is that in some places he uses the term "concern" while in others he uses "responsibility", but NOWHERE does he say that they are different. He DOES NOT say anywhere that first you have to break a program down into different "concerns", and then you break each "concern" into separate "responsibilities" before you can start creating your classes. Although he does not explicitly say that the two terms are the same, neither does he explicitly (or even implicitly) give any hint that they are different.
In this post TomB tried to back up his argument that SoC and SRP are different by asking a simple question:
If SoC and SRP are the same thing, why are there two different wikipedia pages for them?
Because they were written at different times by different people? Later on in this post I asked a different question:
If SoC was different from, yet as important as SRP, then why does it not have its own place in the SOLID principles?
It should also be pointed out that in Robert C. Martin's article Principles of OOD there is no SoC only SRP. Why is this? Because SRP supersedes SoC, that's why!
In this post TomB explained that while "concerned with" and "responsible for" might mean the same thing to most people, they actually mean different things in OOP:
Tony Marston:In a purely english sense perhaps, however they have been used to describe particular concepts in OOP. It's like saying "Car and Automobile mean exactly the same thing" ignoring the fact that "car" can also be used in the context of trains. In which case, they are not the same thing at all. Nuance really isn't your strong point.
"concerned with" and "responsible for" mean exactly the same thing.
If the dictionary definition of these two terms points to the same meaning, then who exactly is redefining the meaning of words to suit their own purposes? It certainly isn't me!
In this post TomB accuses me of redefining various terms:
So far you've redefined encapsulation, SRP, SoC, coupling and "software component" in order to fit your needs and make the claim "My code follows the concepts!!". Instead, you should build your code based on the concepts, not redefine the concepts to fit your code.
As far as I am concerned I am not redefining these terms, which would involve a complete change in their meaning, I am merely using a moderate interpretation instead of an extreme one. This is what I said in this post:
I never redefined any terms, I merely take one of the many existing opinions/interpretations of what a particular term means and apply that interpretation. The fact that some of these terms have so many interpretations - and in many cases contradictory interpretations - just proves that these terms, concepts or principles were so badly written in the first place.
I have NOT redefined what encapsulation means as I have closely followed many of the standard definitions which describe it as "The act of placing an entity's data and the operations that perform on that data in the same class."
I have NOT redefined what SRP and SoC mean as I have separated my code into the EXACT SAME three areas - GUI, business rules and database - that were described in TWO separate articles by Robert C. Martin.
I have NOT redefined "component" as the dictionary definition clearly states it as "constituent part". In software these "constituent parts" could come under several different names - program, subprogram, subroutine, module, class, object.
I have NOT redefined "coupling" as my description at http://www.tonymarston.net/php-mysql/oop-for-heretics.html#coupling clearly uses https://en.wikipedia.org/wiki/Coupling_(computer_programming) as its source.
I repeat, I have implemented both the 3 Tier Architecture and the MVC design pattern, so far from being a monolithic piece of unmaintainable code I have created a proper modular system which is based on sound and proven architectural principles. I have been maintaining and enhancing this code for over 10 years, so it is far from being unmaintainable. Your only objection is that my implementation is different from yours, and you cannot understand how anything so different can be so successful. I have never said that my implementation is right and yours is wrong, I have merely said that my implementation is different. It is YOU who keeps saying "You're not allowed to be different!!"
When people tell me that I am using the wrong interpretation of their favourite principles this points to a fundamental flaw in all of those principles - they are so badly written and so imprecise that they are open to large amounts of interpretation, and therefore mis-interpretation. They contain too many soundbites and buzzwords and not enough substance. Those who follow these principles without thinking do not realise that this makes them nothing more than Cargo Cult programmers who are suffering from the Bandwagon Effect. It is therefore up to the individual programmer to use his own skill and experience in order to not only derive the most meaningful interpretation of those principles, but also to apply them in his software as he sees fit when they provide genuine improvements, or to ignore them when they do not.
In this post s_molinari tries to prove that SoC and SRP are different simply because of the use of a plural instead of a singular:
Tony Marston:You nicely highlight the word responsibility, but ignored what is being said. Look at the last sentence.
The Principle of Separation of Concerns states that system elements should have exclusivity and singularity of purpose. That is to say, no element should share in the responsibilities of another or encompass unrelated responsibilities. Separation of concerns is achieved by the establishment of boundaries. A boundary is any logical or physical constraint which delineates a given set of responsibilities.
A boundary is any logical or physical constraint which delineates a given set of responsibilities.Responsibilities, not responsibility. It is plural, not singular.
Surely I cannot be the only one who thinks that this argument is ridiculous? Both of these things discuss the same principle as the results are exactly the same:
All you have done is separate a group of "things" (plural) so that each "thing" (singular) is now in its own container.
Now substitute the word "class" for "container" and the word "concern/responsibility" for "thing". The results are the same, therefore the principles are the same.
The only difference is that "Separation of Concerns" (plural) identifies the start of the process while the "Single Responsibility Principle" (singular) identifies the end. Same process, different ends. Same result, therefore same meaning.
In this post s_molinari proves that he does not understand what a basic term such as encapsulation means:
Tony Marston:That is not a rule of encapsulation. Where does anything speaking about encapsulation say all methods and properties of an entity all have to go into a single class? In the rules I've read, there is nothing mentioned about "entities". You are twisting the rules of encapsulation here too, just like you do with SRP. Also, your default table class isn't depicting a "single entity" either. It rather deals with a good number of concerns, which breaks SRP.
The first rule of encapsulation is to place ALL the methods and ALL the properties for an entity into a SINGLE class
Incorrect. My abstract table class represents a single unknown database table, while each concrete subclass represents a single specific database table.
As for the rule of encapsulation, have you seen the definition in this wikipedia article?
Encapsulation is the packing of data and functions into a SINGLE component.
It later says the following:
Encapsulation refers to the bundling of data with the methods that operate on that data. Encapsulation is used to hide the values or state of a structured data object inside a class
Or this definition from Encapsulation in Java:
Encapsulation in java is a process of wrapping code and data together into a SINGLE unit
Or even this definition from Ruby Inheritance, Encapsulation and Polymorphism:
Encapsulation is the packing of data and functions into a SINGLE component.
Note the use of the word "single" in all those descriptions. Surely "a single component" is the same as "the same component", or has somebody changed how the English language works?
In my book an "entity" is just another name for "thing" or "object", and this view is supported by wikipedia, which states the following:
An entity is something that exists in itself, actually or potentially, concretely or abstractly, physically or not. It need not be of material existence. In particular, abstractions and legal fictions are usually regarded as entities. In general, there is also no presumption that an entity is animate.
I often use the word "entity" to describe the "thing" which I am trying to represent in my software. I create a class for each "entity", and from a class I can create one or more objects. If I used the single word "object" to identify both the external entity and the software object then I'm afraid that some poor dears would get confused as to which of the two "things" I was actually talking about.
The word "entity" has also been widely used since 1976 to describe database tables, which is why there are such things as Entity-Relationship Diagrams (ERD). Each "entity" in a database is represented as a table, and each "entity" in my software is represented as a Model class in the Business layer.
In his article How to write testable code describes the following basic categories of class:
| Entities | An object whose job is to hold state and associated behavior. The state (data) can be persisted to and retrieved from a database. Examples of this might be Account, Product or User. In my framework each database table has its own Model class. |
| Services | An object which performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). Examples of Services could include a parser, an authenticator, a validator or a transformer (such as transforming raw data into HTML, CSV or PDF). In my framework all Controllers, Views and DAOs are services. |
| Value objects | An immutable object whose responsibility is mainly holding state but may have some behavior. Examples of Value Objects might be Color, Temperature, Price and Size. PHP does not support value objects, so I do not use them. I have written more on the topic in Value objects are worthless. |
This is also discussed in When to inject: the distinction between newables and injectables.
In this post s_molinari shows that he has a very narrow view of what a "responsibility" actually is:
Tony Marston:Wouldn't you say these are 3 different responsibilities? If not, why not?
The methods fall into one of the following categories:
1) Methods which allow it to be called by the layer above it (the Controller or the View)
2) Methods which allow it to call the layer below it (the Data Access Object).
3) Methods which sit between these two. Many of these are "customisable" methods which are empty, but could be filled with code in order to override the default behaviour.
Item #3 includes the methods which provide standard (default) behaviour as well as the customisable methods which can alter this behaviour.
I replied in this post:
No, they are NOT different responsibilities. All those operations form a cohesive unit and therefore belong in the same class. To split them into artificially small classes would convert a modular system into a fragmented system and make it less readable. I am not the only one with this opinion. This is what Tom DeMarco wrote in his book Structured Analysis and System Specification:
Cohesion is a measure of the strength of association of the elements inside a module. A highly cohesive module is a collection of statements and data items that should be treated as a whole because they are so closely related. Any attempt to divide them would only result in increased coupling and decreased readability.
Let me make this quite clear. My implementation of the Model conforms EXACTLY to one of the three responsibilities that Robert C. Martin has mentioned in his articles on SRP. He specifically identified (1) GUI logic, (2) business logic and (3) database logic as being the only responsibilities that need to be separated. Nowhere in any of his SRP articles does he specify or even hint that these three are "mega" responsibilities which need to be broken down further into smaller "minor" responsibilities.
Any competent programmer should be able to tell you that when you have a layered application an object in the middle (business) layer MUST have the three sets of methods that I have identified simply because that is how a layered application is supposed to work. The top (presentation) layer calls the middle layer, which means that the middle layer MUST have methods to receive those calls. The middle layer also calls the bottom (database) layer, which means that the middle layer MUST have methods to make those calls. It should be obvious to anyone with more than two brain cells to rub together that these methods CANNOT sensibly be moved to separate objects as the middle layer would STILL require methods to both receive calls from the layer above it and to make calls to the layer below it. By introducing intermediate objects between these three layers you would be proliferating the number of classes and calls for no good reason. You would also be making the code more difficult to read and understand, and also having an impact on performance by having to load even more class files and instantiating even more objects.
TomB then added to this same argument in this post:
Tony Marston:SRP is violated when there is more than one "reason to change"
So each Model class is responsible for the validation and business rules
? Changing the validation is a reason to change
? Changing the business rules is a reason to change
The class does too much and breaks SRP.
In this post (at the bottom) he then said:
If any of the business rules change, the class needs to change. How many business rules are there? Well it doesn't matter because you specifically said rules. If we were following SRP, each rule would have its own class.
You are obsessing far too much on the phrase "reason to change" and ignoring what Uncle Bob actually wrote. In Test Induced Design Damage? he wrote:
How do you separate concerns? You separate behaviors that change at different times for different reasons. Things that change together you keep together. Things that change apart you keep apart.
GUIs change at a very different rate, and for very different reasons, than business rules. Database schemas change for very different reasons, and at very different rates than business rules. Keeping these concerns (GUI, business rules, database) separate is good design.
In The Single Responsibility Principle he wrote:
Another wording for the Single Responsibility Principle is:
Gather together the things that change for the same reasons. Separate those things that change for different reasons.If you think about this you'll realize that this is just another way to define cohesion and coupling. We want to increase the cohesion between things that change for the same reasons, and we want to decrease the coupling between those things that change for different reasons.
Nowhere in any of these articles does he say that each individual business rule is a separate responsibility which should be put into a separate class, or even that business rules can be separated by some perceived category. By not explicitly subdividing the term "business rules" into different categories or types he is implicitly saying that ALL business rules, whatever their type, form a single responsibility and can therefore be placed in the same class. For anyone to jump to a different conclusion is therefore wrong. In fact, by following this misinterpretation of SRP you end up by decreasing cohesion and increasing coupling which is the exact opposite of what you are supposed to achieve.
The idea that a domain object should not contain data validation or business logic is totally wrong as this would create that anti-pattern known as an anemic domain model where you have state but no behaviour. While it is good practice to remove presentation logic and data access logic from the domain object, business logic should remain. Or, as Martin Fowler says in his article:
It's also worth emphasizing that putting behavior into the domain objects should not contradict the solid approach of using layering to separate domain logic from such things as persistence and presentation responsibilities. The logic that should be in a domain object is domain logic - validations, calculations, business rules - whatever you like to call it
Notice that the words validations, calculations, business rules
are all in the plural. None of these three needs to be separated from the other, and none of these plurals needs to be separated into singulars. These all constitute domain logic which should go into the same domain object.
In SRP: The Single Responsibility Principle he wrote:
If, on the other hand, the application is not changing in ways that cause the two responsibilities to change at different times, then there is no need to separate them. Indeed, separating them would smell of Needless Complexity.
There is a corollary here. An axis of change is only an axis of change if the changes actually occur. It is not wise to apply the SRP, or any other principle for that matter, if there is no symptom.
So even if you think that different pieces of code have different reasons to change, if they don't actually change at different times then there is no reason to separate them.
To any reasonable programmer the concept of "business logic" includes "data validation" because it is the business which defines what data items are required, and it is the software's responsibility to verify that the contents of each data item is valid before it is written to the database. Some of the business rules can be expressed directly in the database schema, such as an entity has a property/column which is a date, a number or a string, but the application should still have code which validates each column's data with its data type before it gets sent to the database. There are also some business rules which cannot be defined in the database schema and which have to be handled directly in the code, such as "the date in columnA must be greater than the date in columnB". The idea that each business rule is a separate "reason to change" and therefore should be placed in a separate class runs contrary to what Uncle Bob actually wrote, so in my view has no validity. It also violates the principle of encapsulation which states that ALL the properties and ALL the methods for an entity should be placed in the SAME class. When I am in maintenance mode and want to examine the business rules associated with a particular database table I would much rather look in the single class which is responsible for that table than have to ferret around in a large collection of classes.
It is also quite common for an operation to involve several distinct steps which need to be performed in a particular sequence, as shown with the updateRecord() method in Table1. In this situation it is common practice to put each of those steps into a separate method in the same class. The only reason to put any of those steps in its own class is when it needs to be accessed independently from the other steps. This then allows the step to be called from more than one object. But if the step will only ever be called from a single object then it would make more sense to include that method in that one object. After all, the idea of using classes and objects is to make code reusable, but if a piece of code is only ever accessed from a single object then there is no need to give it the ability to be accessed from multiple objects. This idea complies with the YAGNI principle.
In this post I tried to explain to TomB that in my main enterprise application each of the 2,500 user transactions has its own component script which is generated by the framework, such as the following:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
Each of these only contains three lines - one each to identify the Model, View and Controller which are to be used - and each combination is totally unique, yet the gormless guru seems to think that this violates the DRY principle.
In this post he claimed that navigating to the framework component to generate each script was obviously less efficient that typing out those three lines by hand. In this post I pointed out that the generation process does much more than that, as in:
But that is not all that my transaction generation process does. For example, the most common transaction pattern in all the applications which I have built is the LIST1. This is part of a family which also includes the ADD1, ENQUIRE1, UPDATE1, DELETE1 and SEARCH1 patterns. When you create a LIST1 task it performs the following:
1) Generates the transaction script for the LIST1 task.
2) Adds the LIST1 task to the TASK table in the MENU database.
3) Adds the LIST1 task to the MENU table in the MENU database.
4) Generates the transaction scripts for the associated ADD1, ENQUIRE1, UPDATE1, DELETE1 and SEARCH1 tasks.
5) Adds ALL these task to the TASK table in the MENU database.
6) Adds ALL these task to the NAVIGATION table in the MENU database.
This means that the LIST1 task will be instantly available on that subsystem's menu bar, and all the associated tasks will be available on the LIST1 task's navigation bar. All these tasks will be runnable with default behaviour but without having to write a single line of code - no PHP, no HTML no SQL. Can YOUR framework do that?
This did not satisfy TomB as this post was his reply:
Simply put: it doesn't need to because putting it together doesn't require so many repeated steps each time I want to add something... as I said, it violates DRY.
When I asked him why this post was his reply:
Just because you've automated the process doesn't mean it's not repeated each time... you just coded something to do it for you. My point was, this repetition of each of those steps you mentions exactly that.
In this post I asked him why running a program several times to repeat a process would be considered a violation of DRY:
According to your logic if I use the "Add Customer" transaction 100 times to add 100 different customers to my database then I have violated the DRY principle simply because I have used the same transaction 100 times. Do you know how ridiculous that sounds?
His reply in this post was as clear as mud:
If it's generating similar code 100 times then yes, it is violating DRY. Just because you automated the repetition and didn't have to type it out repeatedly doesn't mean there isn't repeated code, it's just automatically generated repeated code.
I tried to explain to him in this post that running the same procedure several times does not violate DRY:
It is NOT repeated code! The same code is run many times, but each time it produces a different result by creating new records on the database or new files on disk.
The DRY principle is only violated when you have identical blocks of code appearing in multiple places in the same piece of software.
Obviously I hit a brick wall as this post was his reply:
...which contain similar code.
I tried to explain in this post that using the same process to add different records to the database was not the same as writing the same piece of code multiple times:
Similar maybe, but NOT identical. Besides "adding new records to the database" is not the same as "generating similar code".
If each time I run the same piece of code to generate new records in the database, how does the act of running the code violate the DRY principle?
His reply in this post clearly shows that his thought processes are beginning to wander:
You need to repeat the process each time. This is by definition repeating yourself.
This numpty clearly does not understand that the DRY principle covers the WRITING of the same block of code multiple times, not the EXECUTION of that code multiple times.
If someone can twist the meaning of "Don't Repeat Yourself" to include the repeated running of the same process as well as repeating the same lines of code then as far as I am concerned it is simply not possible to have a sensible discussion with that person. Every single programmer in the universe (by that I mean every competent programmer) knows that the purpose of writing software is to create programs which can be run repeatedly to automate a process. For example, a typical e-Commerce application has a process called "Enter Sales Order" which can be run thousands of times, and each time it enters a different sales order. This is what generates revenue for the business. The fact that the same process is run thousands of times is NOT a violation of DRY. That particular principle relates ONLY to lines of code which are repeated and not to anything else.
In this post s_molinari states that SRP has nothing to do with modular programming:
Tony Marston:This is incorrect. Nothing mentioned concerning SRP is about splitting up large monolithic programs into smaller and more manageable modules.
Both SoC and SRP describe the splitting of a large monolithic program into smaller and more manageable modules.
Am I the only one who is astonished at this remark? Robert C. Martin's article at Single Responsibility Principle clearly states that, instead of having one single piece of code which contains a mixture of GUI logic, business logic and database logic, you split out those different pieces of logic and put them into separate modules. In this way each module is "concerned with" or "responsible for" only a single piece of logic. The word "module" is a generic term and can be expressed differently in different languages or paradigms. In procedural programming it can be a "subprogram" or "subroutine", in component-based programming it can be a "component", and in OO programming it can be a "class" or "object".
Perhaps you ought to read the following definitions of "modular programming":
Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules, such that each contains everything necessary to execute only one aspect of the desired functionality.
Modular programming is closely related to structured programming and object-oriented programming, all having the same goal of facilitating construction of large software programs and systems by decomposition into smaller pieces.
Modular programming is the process of subdividing a computer program into separate sub-programs.
A module is a separate software component. It can often be used in a variety of applications and functions with other components of the system. Similar functions are grouped in the same unit of programming code and separate functions are developed as separate units of code so that the code can be reused by other applications.
Object-oriented programming (OOP) is compatible with the modular programming concept to a large extent. Modular programming enables multiple programmers to divide up the work and debug pieces of the program independently.
One key solution to managing complexity of large software is modular programming: the code is composed of many different code modules that are developed separately. This allows different developers to take on discrete pieces of the system and design and implement them without having to understand all the rest.
In this post your favourite gormless guru TomB made the following statement:
Tony Marston:Sorry, what? So any article that uses two different terms without explicitly stating they are different means they are the same?
They use the two terms in the same article without saying that the two terms are different, which confirms that they have the same meaning. That is not a big leap, it is a reasonable interpretation.
That is correct. I was educated in a proper Grammar school and not one of these pathetic state-run comprehensives, and we were taught that if an article/paper/book/whatever described an idea/concept/principle and switched between using different words for the same idea then by default those different words had exactly the same meaning. I say by default as the default could ONLY be overridden by an explicit statement to the contrary. Thus a book on driving could use the terms "highway", "street" and "road" in different places which a reasonable, sensible, intelligent and well-educated person would treat as having the same meaning. This assumption could only be corrected by an explicit statement to the contrary. Not only would it have to say the "highway", "street" and "road" are different but it would also have to define the differences.
The argument that if a document uses two different words to define a concept and does not explicitly say that they are the same means that they are actually different can be twisted around - if the article does not explicitly say that they are different then it must mean that they are the same.
In Robert C. Martin's article The Single Responsibility Principle he clearly states the following:
This is the reason we do not put SQL in JSPs. This is the reason we do not generate HTML in the modules that compute results. This is the reason that business rules should not know the database schema. This is the reason we separate concerns.
Here he is clearly saying that the "separation of responsibilities" is EXACTLY the same as "separation of concerns". He did NOT say that the two terms are different, nor did he explain why they would be different, therefore they are the same. I said the same thing in this post:
My reference to "responsibility" and "concern" was to point out that as that article switched between the two terms without explicitly saying that they were different that it led me to believe that they had the same meaning. Others is this discussion came to a different conclusion - because the article did not explicitly say that they were the same they deduced that they were different.
The gormless guru TomB resorted to personal insults in post #72, post #73, post #80 and post #88. He seems to think that anyone who does not follow his particular interpretation of the rules is automatically incompetent. He fails to understand that there is no single set of rules which is universally accepted by all programmers. He fails to understand that following rules is less important than producing cost-effective software, and if I can produce cost-effective software by ignoring his favourite rules then it simply proves that his favourite rules are not the only way to produce cost-effective software. As I can also produce cost-effective software at a faster rate and with more features than he possibly can then it is clear to me that my level of competence is higher, not lower, than his.
I build business-facing enterprise applications, which means that I specialise in writing applications which do nothing but allow users to maintain and view the contents of a relational database. I am therefore experienced in both the design of application databases and the design and building of software which interacts with those databases. If a database consists of tables and columns which are manipulated using SQL queries then it is logical (to me at least) that the software should also have knowledge of tables, columns and SQL queries.
I designed and built my first framework in 1985 using COBOL (see my User Guide - COBOL) for a single project but it was so successful that it was adopted as the company standard for all future projects. In the 1990s I redeveloped this framework in UNIFACE (see my User Guide - UNIFACE), and when I switched to using PHP in 2002 I again rewrote my framework (see my User Guide - PHP). The latest version, which is available as open source from radicore.org, is Object Oriented by virtue of the fact that it implements encapsulation, inheritance and polymorphism, and because it does nothing but manipulate database tables it has a separate class for each table. It is a proper rapid application development (RAD) framework in that after creating a new table in my database I can create a whole family of transactions in a matter of minutes without writing a single line of code - no PHP, no HTML, and no SQL. The LIST1 transaction can then be instantly accessed from a menu button while the others are available as navigation buttons on the LIST1 screen. While these transactions are fairly basic in that they only provide default behaviour, by providing the default behaviour so quickly they leave the programmer much more time to deal with the heart of the application, which is the business rules. The programmer can override the default behaviour in any of the table classes simply by putting custom code inside the relevant customisable method.
Not only have I released this framework as open source so that other developers can use it to build enterprise applications of their own, I have also used it to build my own enterprise application as a package which is now marketed as the GM-X Application Suite, so that it can be used by multiple customers as a cheaper option than a one-off bespoke application. I did this by starting with several of the database designs in Len Silverston's Data Model Resource Book, specifically the PARTY, PRODUCT, ORDER, INVENTORY, INVOICE and SHIPMENT databases, which I then imported into my Data Dictionary. From there it was one button press to create a class file for each table, then another button press to create default transactions from my library of Transaction Patterns to access each table. The only thing left to do was to flesh out the default transactions with all the necessary business rules by putting code in the custom methods.
Guess how long it took me to create and demonstrate the first prototype? Six months. This equates to an average of one month per database, which is far faster than can be achieved with your methods. It is this level of productivity which impresses customers, not your blind following of rules in the name of "purity".
Unless you can - single-handedly - create your own framework which has capabilities and levels of reusability which match my RADICORE framework, and can - single-handedly - use that framework to create an enterprise application which has capabilities to match mine, then I am afraid that your opinion that one of us is incompetent is aimed in the wrong direction. Not only has my track record proved that I am not incompetent, I am actually less incompetent than you think. In fact I feel justified in saying that I am actually less incompetent than you, period. So put that in your IDE and compile it.
All the arguments I hear against by methodology are like a bunch of chefs who have got together to discuss not the efficacy of their recipes but the rules which they follow in order to create their recipes. They each try to invent more esoteric rules in order to prove how clever they are or that their approach is purer than everyone else's, but they fail to realise that the success of a recipe is not judged by the effort that went into it, or how many rules which it obeyed, but by the taste of the result. This simple fact gave way to the phrase The Proof of the Pudding is in the Eating. Although this phrase originated in the culinary world it is also relevant in any area which has processes to produce results. The opinion of the person who consumes the result of a process carries more weight than that of the person who created the process. Something which tastes like crap will always be a failure regardless of how much effort went into the recipe.
There are two ways in which a chef can make money - prepare meals from his own recipes or publish those recipes in a book so that others can prepare meals from them. The success of a published recipe will then be judged on how easy it is to follow it as well as the results that it produces. If two chefs both have recipes for the same meal, but chef #1's recipe is easier to follow than that of chef #2, then who do you think will be judged as the better chef? If chef #1's recipe requires ingredients which can be obtained from any local supermarket while chef #2's requires a remote speciality store, then whose recipe do you think will be more popular? A chef's opinion of his recipe is nothing compared to the opinion of the person who consumes the result of that recipe.
Competency as a programmer should not be judged on how well you follow a bunch of artificial rules but only by the quality of the software which you produce. I have been designing and building database-based enterprise applications for over 30 years, and since 1985 I have built frameworks in 3 different languages to assist me in this task. I can now produce such applications much faster and therefore cheaper than you, and with more features, so your opinion of my methods is irrelevant. My latest framework, which can be considered as a recipe for making database applications, has been available as open since 2006 so that others can benefit from my not inconsiderable experience. I can absolutely guarantee that none of my critics has actually used my framework to build an application to see how it compares with what they can produce, so I do not believe that they have genuine grounds for saying that my framework is a failure. Rather than the results of my efforts being crap, it is their rules which are crap, which is why I don't follow them.
If posts in an online forum were not enough critic Scott Molinari started to attack me via email. He started with this:
Your interpretation of SRP is a total bending of what Uncle Bob communicates. It isn't my interpretation. It is what he is saying. His references to separation of concerns is just a preamble to his further refinement of SoC, which he calls SRP, the part you actually completely ignore. The fact you equate the two out of his writing shows how your interpretation is a twist to make it fit your design and not the other way around. Your design should be fitting his principle. And thus, it seems like a futile effort to make you see how incorrect you are. We've been trying without an iota of success for weeks.
I am in no way "bending" what Uncle Bob wrote. If you look the following articles:
You should clearly see the following points:
How can you possibly accuse me of bending what he wrote when I keep referring to the exact words which he wrote and not the words that he didn't write? Can you answer these questions:
The separation of logic which he describes in all of those articles fits the description of the 3-Tier Architecture which is precisely what I have implemented, so how can my implementation be anything other than in accordance with what he wrote?
Scott continued his email with:
It is obvious, you intend to learn nothing or are even slightly open for considering other "interpretations", as you not only ignore the complete meanings in what Bob and other authors have written, including Derek, but also the people who are trying to help you too, like Tom and myself. Not only do you incorrectly interpret what the authors are saying, you insist they agree with you, despite them clearly saying the contrary. You don't want help. You are blind as a bat. I get that now.
If the "rules" of OOP are so badly written and so imprecise that they are open to vast amounts of interpretation and mis-interpretation, who are you to tell me which interpretation is the only one that should be followed? I will interpret each rule in a way that makes sense to me, but unless I can be convinced that a different interpretation will provide genuine benefits in the context of the type of applications which I write then I will refuse to follow that interpretation.
I am willing to learn new ways, but only if they are better than the old ways. Due to my long experience in which I have been exposed to many different theories, some of which worked and some which did not, I choose to stick with those that have contributed to successful projects and ignore those which have contributed to the disasters. This is my choice not yours. Stop telling me that your interpretation of the rules is the only valid interpretation as there are plenty of articles on the internet which contradict your opinion.
So, I will predict the future. You will continue to have a badly rotting knowledge of PHP and OOP programming and a continued urge to fight any change, which I personally find a shame. The PHP world can always use a good and passionate developer. But, to be good, you have to be constantly learning and have a willingness to change and explore new ideas and concepts. The PHP development world is a living and organic ecosystem and you are just a dev under a rock, who once and a while tries to get out and claim a rightful place in the ecosystem. It is the only reason I can come up with for your insistence on your class following SRP or your framework being better than other frameworks today. Both are untrue as can be.
I am a passionate developer, which is why I am still doing it after 30 years. My experience tells me whether an idea is good or not, and I simply will not waste my time on ideas that do not smell right to me. I will not refactor my huge codebase just because a new feature has been made available in the language. I will only use a new feature if the cost of refactoring has genuine benefits, but I will not use it just because it is there. This is what we oldies call a "cost-benefit analysis" or "return on investment". Perhaps that is something that you ought to learn. The fact that I don't use every new feature in the language as soon as it is released should be irrelevant. I have been programming with different languages for several decades, and I can honestly say that I have never found a good reason to attempt to use every available feature in any of those languages. I will only use those features which help me solve a current problem, and once I have found code that works I move on to the next problem. It may be possible to solve a problem in one of several different ways, but once I have written code that works I will not refactor it unless the cost of refactoring can be justified with genuine benefits.
Thus, your efforts are a major fail. Why? Because you stopped learning with the creation of your framework 10 years ago and it shows in your code too. Your framework may work. It may make you money. And that is fine for you. It shows resilience and persistence. To good characteristics to have. But, please stop insisting you or your framework deserve a place in the PHP ecosystem today, by insisting it and you follow modern coding principles. That is the issue. It is simply incorrect. You first need to be willing to learn and change Tony, then work on your code, then see if it fits the ecosystem. If it does, the ecosystem will enjoy your presence and your work and welcome you with open arms. If that isn't what you want in the end, please just stay under your rock, until you decide you do want to learn and change.
My efforts haven't failed for the simple reason that they work, and have worked for several decades. I have been designing and building cost-effective software with PHP for over a decade (and with other languages for several decades before that) so there cannot be anything wrong with my methodology. I have not stopped learning as I constantly check various blogs for new ideas. The sad fact is that a lot of these "new" ideas are nothing more than "old" (and "bad") ideas which have been rebranded and which have resulted in the condition known as Gilding the Turd. I refuse to follow "modern" coding principles because they do not improve upon the original principles which I learned in the 1970s, that of writing simple code, readable code and modular code. Both the hardware and the software have changed significantly since then, and I have adapted to these changes, but the basic principles have remained the same. I used to design and build enterprise applications for "green screen" VDUs, but nowadays I design and build the same type of applications for the internet which still sell today for the simple reasons that they are deemed by my customers to be more cost-effective than rival applications which have been built by my competitors. Provided that my competitors are dogmatists and purists like you I shall always beat them, so please continue what you are doing as it puts money in my pocket.
I don't write code which is acceptable to other programmers as my priority is to write code which is acceptable to my customers, the ones who pay my wages. They want cost-effective software, so cost-effective software is what I deliver. I can build software at a faster rate than you can, and with more features, so it will always be more cost-effective than yours and therefore more appealing to customers. The fact that it is not as pure as you would like is irrelevant. "Pure" software that does not sell has less value than "not-so-pure" software that does sell. By concentrating on purity instead of sell-ability you are concentrating on the wrong objective. This could end up with a situation similar to that of a surgeon who utters the phrase "the operation was a success but the patient died". A dead patient can never be a sign of success. Software which does not sell, or which is not cost-effective, can never be a sign of success.
I am a pragmatist, not a dogmatist, which means that I put achieving a result before the following of rules. The fact that my methodology is different from yours should be irrelevant as the results speak for themselves. Instead of complaining that my methodology is different perhaps you should be more open-minded and ask yourself the question "If his methodology is different from mine, yet still produces software which is as successful (or even more successful) than mine, then perhaps it is my methodology which should be questioned".
All the vitriolic attacks on my style of programming can be boiled down to the following:
In some cases these wild accusations are brought about by confusion on the part of certain crackpots who cannot get to grips with the fact that in the English language:
These wild accusations are totally without foundation due to the following facts:
If my code really was as bad as you make it out to be, then surely none of this would be possible.
If you read article 6 things all good software code has in common you will see that it lists the following:
Nowhere it that list does it say It has to follow every silly principle imaginable regardless of how effective it is
, so excuse me if I do not feel obliged to corrupt my code in such a perverse way.
The only accusation that I will admit to is that my approach to software development is definitely "different" to what is being taught to the current generation of developers. But "different" is not the same as "wrong". Just because you have only been taught one way to do things does not necessarily mean that it is the only way, or even the best way. It is just one way of several possible ways, and surely it would be "best practice" to allow budding programmers to be aware of the alternative approaches so that they can weigh up the pros and cons of each one before deciding for themselves which one makes the most sense or makes them feel the most comfortable. If young developers are taught to do what they told, without question and never try thinking for themselves, never to question the rules, then I'm afraid the future will consist of nothing but a bunch of code monkeys and copycat developers who practice nothing but Cargo Cult Software Engineering who suffer from the Lemming Effect or the Bandwagon Effect. If you agree with the points made in Effective PHP Cargo Cult Programming them I'm afraid that you will never be anything more than a second rate programmer (if that), and you and I will never agree on anything.
What a lot of developers fail to realise is that the primary purpose of a software developer is to develop software which provides benefits to the paying customer, not to impress other developers with their clever and fashionable development techniques. This software needs to be effective and efficient, and the paying customer will be swayed by such things as development speed and development cost, but never development style. I choose a style which enables me to create software at a faster speed and lower cost than my rivals, and all the while I have to compete against dorks who prefer style over substance then it makes my job that much easier.
When I write software I, like every other developer, am constrained by certain limitations:
I refuse to be constrained by the limitations of your intellect as it would be the equivalent of going back in time and living with neanderthals.
I have made this point before, but it is worth repeating:
If I were to do everything the same as you then I would be no better than you, and I'm afraid that your best is simply not good enough. The only way to become better is to innovate, not imitate, and the first step in innovation is to try something different, to throw out the old rules and start from an unbiased perspective. Progress is not made by doing the same thing in the same way, it requires a new way, a different way.
When it comes to software engineering I am a pragmatist, not a dogmatist. I do not blindly follow a set of rules and assume that the outcome is going to be perfect, I aim for an outcome and use whatever tools and techniques come to hand in order to achieve that outcome as quickly, simply and effectively as possible. If I have to break other people's artificial and arbitrary rules to achieve that objective then so be it. If any rule gets in my way or doesn't measure up, then I will flush it down the toilet without any hesitation. If you don't like it, then it's your problem, not mine.
For those of you out there who are still under the erroneous impression that just because I do not follow your version of best practices that my code is automatically crap I have one final word:
That may be what you laughingly call "best practices" in your neck of the woods, but from where I'm standing your neck of the woods is simply the place where the bears go to take a dump. That is why you are ankle-deep in bear crap and I'm knee-deep in roses.
Here endeth the lesson. Don't applaud, just throw money.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles:
| 09 Dec 2023 | Added Some "best practices" are not appropriate. |
| 29 Aug 2015 | Added The proof of the pudding is in the eating. |
| 15 Aug 2015 | Added You are incompetent and Insults via email. |
| 31 Jul 2015 | Added You are twisting the meaning of words. |
| 02 Jul 2015 | Added Crackpot Critics. |
| 26 Jun 2015 | Added Table 1 to show how many Model methods can be used in a single user transaction. |
| 18 Jun 2015 | Added You have created an anemic domain model |
| 12 Jun 2015 | Added Software Development and Religious wars |
| 13 May 2015 | Added You have created a "god" class
Updated Your code uses singletons Added You don't understand Design Patterns Added You are not following Best Practices Added You are not keeping up with changes to the language Added You are a Luddite and unwilling to change Added Summary |