Figure 1a - A single module with multiple responsibilities
")
Visitors to my website may be aware that my efforts in building A Development Infrastructure for PHP have been attacked most vociferously by a group who do not like what I have done simply because it is different to the way in which they would have done it. Because it is 'different' it is automatically branded as 'impure'. The following articles document some of their criticisms along with my responses:
These people are like religious zealots who think that their way is 'the only way, the one true way', and that anybody who dares to think differently is an unbeliever, a heretic, and should be burned at the stake. They act like a modern equivalent of the Spanish Inquisition. I call these people the 'paradigm police'.
I do not care for their brand of religion. I will not conform. I will not apologise for being different.
The problem with OOP is that there is no clear definition of what it is and what it is not. Since its first appearance numerous people have expanded on its original definition (whatever that was) and invented new 'rules' which in turn have been subject to different interpretations. For each interpretation there are also many different possible implementations. There is no single definition, or set of definitions, which is universally accepted, therefore, no matter what you do, somebody somewhere will always find a reason to complain that 'you are wrong!'
Here is a list of basic definitions that I referenced while creating my infrastructure:
| Object Oriented Programming | Writing programs which are oriented around objects. Such programs can take advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance.
Note that the effectiveness of your implementation can be measured by the amount of reusable code that you produce. The more reusable code you have at your disposal then the less code you need to write to get the job done, the less time it will take and the more productive you will be. |
| Abstraction | The process of separating the abstract from the concrete, the general from the specific, by examining a group of objects looking for both similarities and differences. The similarities can be shared by all members of that group while the differences are unique to individual members. The result of this process should then be an abstract superclass containing the shared characteristics and a separate concrete subclass to contain the differences for each unique instance.
As explained in What is "abstraction" there are two flavours:
Please also refer to What Abstraction is not and The difference between an interface and an abstract class. |
| Class | A class is a blueprint, or prototype, that defines the variables (data) and the methods (operations) common to all objects (entities) of a certain kind. A class represents a common abstraction of a set of entities, suppressing their differences.
In a database application each table has its own blueprint which is defined in the DDL script, and different rows in that table have different values which match that blueprint. Every table, regardless of the data which it holds, is subject to exactly the same methods, which are Create, Read, Update and Delete (CRUD). This is why it is a good idea to create a separate class for each database table. |
| Object | Objects are instances of a class which represents a set of problem domain entities of the same kind. All instances of a class provide the same interface (set of operations) to other objects. The intent of an object is to encapsulate the representation of a problem domain entity which changes state over time.
A class must be instantiated into an object before it can be used in the software. More than one instance of the same class can exist at any one time. Each instance shares the same set of methods, but has different values for its variables. |
| Encapsulation | The act of placing data and the operations that perform on that data in the same class. The class then becomes the 'capsule' or container for the data and operations. This binds together the data and functions that manipulate the data.
The difficult part is choosing the data and operations to encapsulate. It would not be wise to put all the data for the entire application into a single class as this would be a monolithic monstrosity. Instead the application should be broken down in smaller logical units or entities, each with its own distinct responsibility, and a separate class should be built for each entity. Each class would therefore be responsible for the data and operations for that single entity. In a database application the smallest logical unit would be a database table as each table has its own structure and its own business rules. The smallest units are NOT columns as these should be regarded as properties of the entity/table in which they belong. Creating a class which is responsible for more than one database table would create a class with multiple responsibilities - multiple structures, different business rules for each structure, separate methods for each table - which would make it less cohesive and more difficult to maintain. Note that this requires ALL the properties and ALL the methods for an entity to be placed in the SAME class. Breaking a single class into smaller classes so that the count of methods in any one class does not exceed an arbitrary number is therefore a bad idea as it violates encapsulation and makes the system harder to read and understand. Putting all methods which are related into the same class leads to high cohesion whereas putting related methods into separate classes leads to low cohesion. Note that data may include meta-data (type, size, etc) as well as entity data. Please also refer to What Encapsulation is not. You may also like to read the following: |
| Inheritance | The reuse of base classes (superclasses) to form derived classes (subclasses). Methods and properties defined in the superclass are automatically shared by any subclass. A subclass may override any of the methods in the superclass, or may introduce new methods of its own. The PHP4 manual had this to say:
Often you need classes with similar variables and functions to another existing class. In fact, it is good practice to define a generic class which can be used in all your projects and adapt this class for the needs of each of your specific projects. Note that I am referring to implementation inheritance (which uses the "extends" keyword) and not interface inheritance (which uses the "implements" keyword). Please also refer to What Inheritance is not. |
| Polymorphism | The earliest definitions I found were not very informative, such as:
Polymorphism is the ability to send a message to an object without knowing what its type is. Unfortunately this description is lacking in clarity. If an "object" is instantiated from a "class", where does "type" fit in? Where is the definition of "type"? What is the relationship, if any, between "class" and "type"? What is the relationship, if any, between "type" and "data type"? If they mean the same thing then why not be consistent and use the same word? This is what the PHP4 manual said: Classes are types, that is, they are blueprints for actual variables. You have to create a variable of the desired type with the new operator. This then means that, as far as PHP is concerned, there is no distinction between "class" and "type" as each class is its own type. It is not possible to assign a type to a class or an object as its type is always the same as its class. When you instantiate a class into a variable and then call the gettype() function on that variable the result will always be nothing but "object". A more meaningful definition of polymorphism is as follows: Same interface [method signature], different implementation. The ability to substitute one class for another. This means that different classes may contain the same method signature (which is not the same as an object interface), but the result which is returned by calling that method on a different object will be different as the code behind that method (the implementation) is different in each object. In other words I can code While the most common way to share method signatures among multiple classes is to define them in a superclass which can then be inherited by any number of subclasses, it is also possible to define method signatures manually in each class which makes them hard-coded instead of inherited. Note that by "interface" I actually mean "method signature" and not the object interface which requires the use of the keywords "interface" and "implements" as these are entirely optional in PHP (they were added as an option in version 5). All that is required is that different classes implement the same method signature. Unlike some other languages, it is NOT a requirement that the method signature was previously defined in an interface or an abstract class. Please also refer to What Polymorphism is not and Polymorphism in PHP. |
| Dependency | Dependency, or coupling, is a state in which one object uses a function of another object. It is the degree that one component relies on another to perform its responsibilities. It is the manner and degree of interdependence between software modules; a measure of how closely connected two routines or modules are; the strength of the relationships between modules.
Coupling is usually contrasted with cohesion. Low coupling often correlates with high cohesion, and vice versa. Low coupling is often a sign of a well-structured computer system and a good design, and when combined with high cohesion, supports the general goals of high readability and maintainability. High dependency limits code reuse and makes moving components to new projects difficult. Lower dependency is better. You can only say that "module A is dependent on module B" when there is a subroutine call from A to B. In this situation it would be wrong to say that "module B is dependent on module A" because there is no call from B to A. Module B is a dependent *OF* but not dependent *ON* module A. If module B calls module C then B is dependent on C, but there is no direct dependency between module A and module C as A does not call C. Module A does not even know that module C exists. However, it would be safe to say that there is an indirect dependency between module A and module C as module A is dependent on module B which, in turn, is dependent on module C. If there is a dependency then there is coupling, but the degree of coupling can be one of the following:
The idea that loosely coupled code can be further "improved" by making it completely de-coupled (via Dependency Injection) shows a complete misunderstanding of what the terms dependency and coupling actually mean. If module A calls module B then there *IS* a dependency between them and they *ARE* coupled. All that Dependency Injection does is move the place where the dependent object is instantiated, it does *NOT* remove the fact that there *IS* a dependency and coupling between them. |
| Coupling | Describes how modules interact. The degree of interdependence between software modules; a measure of how closely connected two routines or modules are; the strength of the relationships between two modules. High/Tight coupling means that modules are closely connected and changes in one module may affect other modules. Low/Loose coupling means that modules are independent, and changes in one module have little impact on other modules.
Loose coupling is better as it tends to create more methods which are polymorphic and therefore reusable via the mechanism known as Dependency Injection. It is not possible to write completely decoupled methods, otherwise the program will not work! Tight coupling tends to reduce or even eliminate the number of reusable methods. Tightly coupled systems tend to exhibit the following developmental characteristics, which are often seen as disadvantages:
Note that this coupling is restricted to when one module calls another, not when one class inherits from another. With inheritance the two classes are combined to form a single object whereas coupling describes the interaction between two different objects. The ripple effect was first described in an article called Structured Design published in 1974 in the IBM Systems Journal Vol. 13, No 2 which stated: The fewer and simpler the connections between modules, the easier it is to understand each module without reference to other modules. Minimizing connections between modules also minimises the paths along which changes and errors can propagate into other parts of the system, thus eliminating disastrous 'Ripple Effects', where changes in one part causes errors in another, necessitating additional changes elsewhere, giving rise to new errors, etc. Note the words "fewer and simpler". This means that the number of connections also has a bearing on the maintainability of the code as well as the simplicity of each connection. Some people seem to think that "de-coupling", where a direct call between two modules is interrupted by inserting a call to an intermediate object, is a good idea. This is not correct as it has the effect of doubling the number of connections which makes the path through the code more convoluted that it need be. The shortest distance between two points is a straight line, so if you interrupt the line with more points and change direction between them you can easily loose sight of where you came from and where you are going. Coupling is usually contrasted with cohesion. Low coupling often correlates with high cohesion, and vice versa. Coupling is also affected by the number of times the transfer of control flows not from one method to another but from one object to another. If MethodA calls MethodB where both methods are closely related in their responsibilities, such as the generation of HTML or SQL, or the execution of business rules, then putting those closely related methods into different objects will lower cohesion and increase coupling, both of which are traits which should be avoided. As shown in Figure 12 I have split my application into several layers and several component types. The only place where table names and column names are mentioned in any code is within the Model, which eliminates a great deal of tight coupling:
This means that if I change a table's structure or validation rules I only have to change a single Model class, and none of the other classes will be affected. I do not have to change any Controllers, Views or Data Access Objects. This high level of reusability is a clear sign that I have achieved low coupling. This term is often interchangeable with dependency. Note that some people like to say that inheritance automatically produces tight coupling between the superclass and the subclass, but this only causes a problem when you extend one concrete class into a different concrete class. As I only ever create a concrete table class from my abstract table class this problem does not arise. Good object-oriented design requires a balance between coupling and inheritance, so when measuring software quality you should focus on non-inheritance coupling. Please also refer to What Coupling is not and The difference between Tight and Loose Coupling. |
| Cohesion | Describes the contents of a module. The degree to which the responsibilities of a single module/component form a meaningful unit; the degree of interaction within a module; the functional relatedness of the contents of a module. It refers to the degree to which elements within a module work together to fulfill a single, well-defined purpose. High cohesion means that elements are closely related and focused on a single purpose, while low cohesion means that elements are loosely related and serve multiple purposes.
Higher cohesion is better. Modules with high cohesion are preferable because high cohesion is associated with desirable traits such as robustness, reliability, reusability, extendability, and understandability whereas low cohesion is associated with undesirable traits such as being difficult to maintain, difficult to test, difficult to reuse, difficult to extend, and even difficult to understand. In his book Structured Analysis and System Specification Tom DeMarco describes cohesion as: Cohesion is a measure of the strength of association of the elements inside a module. A highly cohesive module is a collection of statements and data items that should be treated as a whole because they are so closely related. Any attempt to divide them would only result in increased coupling and decreased readability. In his blog Glenn Vanderburg has this description of cohesion: Cohesion comes from the same root word that "adhesion" comes from. It's a word about sticking. When something adheres to something else (when it's adhesive, in other words) it's a one-sided, external thing: something (like glue) is sticking one thing to another. Things that are cohesive, on the other hand, naturally stick to each other because they are of like kind, or because they fit so well together. Duct tape adheres to things because it's sticky, not because it necessarily has anything in common with them. But two lumps of clay will cohere when you put them together, and matched, well-machined parts sometimes seem to cohere because the fit is so precise. Adhesion is one thing sticking to another; cohesion is a mutual relationship, with two things sticking together. In his blog Derek Greer has this description: Cohesion is defined as the functional relatedness of the elements of a module. If all the methods on a given object pertain to a related set of operations, the object can be said to have high-cohesion. If an object has a bunch of miscellaneous methods which deal with unrelated concerns, it could be said to have low-cohesion. In his blog John Sonmez describes it as follows: We would say that something is highly cohesive if it has a clear boundary and all of it is contained in one place. High cohesion can be said to have two faces:
Cohesion is usually contrasted with coupling. High cohesion often correlates with low coupling, and vice versa. As an example of cohesion suppose we start with a program that contains 100 functions which can be broken down as follows:
Putting each of these functions in its own class would be bad because each method/function would not have any other methods within its class to which it could be related, therefore it would have no cohesion whatsoever. It would just produce a series of anemic micro-classes which would be more difficult to understand and maintain. As a high-level task is usually accomplished by performing a series of related low-level functions, if all those functions are in separate classes this could lead to tight coupling between those classes, which would be bad. Loose coupling is better. Putting all of these functions into a single class would be bad because it would contain too much mixed and unrelated logic, therefore it would have low cohesion. This would also be a prime example of a God object. The correct thing to do is to create a class for each area of functionality and put all related functions into that class. Be aware that a collection of functions which operate in a particular area may be broken down into smaller groups which are actually mutually exclusive. For example, the HTML, CSV and PDF functions could all be considered part of the View in the MVC design pattern, so it may be tempting to put all these functions into a single View class. This would be wrong because when output is generated it is only one of HTML, CSV or PDF and never a mixture, so each of those output formats is mutually exclusive. By creating separate classes for HTML, CSV and PDF output you would therefore have high cohesion. As shown in Figure 12 I have split my application into several component types each of which perform separate functions:
|
| Visibility | The ability to 'see' parts of an object from outside. Any method or property marked as 'public' is visible, whereas any method or property marked as 'private/protected' is not visible to the outside world and is therefore 'hidden'. Methods and properties which should not be directly accessed from outside should be hidden. Lower visibility is often considered to be better. |
Tightly coupled systems tend to exhibit the following developmental characteristics, which are often seen as disadvantages:
In this wikipedia article there is a description of tight coupling:
Content coupling (high)
Content coupling (also known as Pathological coupling) occurs when one module modifies or relies on the internal workings of another module (e.g., accessing local data of another module). Therefore changing the way the second module produces data (location, type, timing) will lead to changing the dependent module.
Here is an example of tight coupling:
<?php require 'screens/person.detail.screen.inc'; require 'classes/person.class.inc'; $dbobject = new Person(); $dbobject->setUserID ( $_POST['userID'] ); $dbobject->setEmail ( $_POST['email'] ); $dbobject->setFirstname ( $_POST['firstname']); $dbobject->setLastname ( $_POST['lastname'] ); $dbobject->setAddress1 ( $_POST['address1'] ); $dbobject->setAddress2 ( $_POST['address2'] ); $dbobject->setCity ( $_POST['city'] ); $dbobject->setProvince ( $_POST['province'] ); $dbobject->setCountry ( $_POST['country'] ); if ($dbobject->insertPerson($db) !== true) { // do error handling } ?>
An alternative to this would be to pass each column as a separate argument on the method call like in the following:
$result = $dbobject->insertPerson($_POST['userID'], $_POST['email'], $_POST['firstname'], $_POST['lastname'], $_POST['address1'], $_POST['address2'], $_POST['city'], $_POST['province'], $_POST['country'], );
The above code exists within the consuming object and "Person" represents the dependent object. This is "tight" coupling because of the following:
Tight coupling often correlates with low cohesion.
Loosely coupled systems tend to exhibit the following developmental characteristics, which are often seen as advantages:
In this wikipedia article there is a description of loose coupling:
Message coupling (low)
This is the loosest type of coupling. It can be achieved by state decentralization (as in objects) and component communication is done via parameters or message passing.
In the same article it also states
Low coupling refers to a relationship in which one module interacts with another module through a simple and stable interface and does not need to be concerned with the other module's internal implementation.
In this wikipedia article it states:
The degree of loose coupling can be measured by noting the number of changes in data elements that could occur in the sending or receiving systems and determining if the computers would still continue communicating correctly. These changes include items such as:
- Adding new data elements to messages
- Changing the order of data elements
- Changing the names of data elements
- Changing the structures of data elements
- Omitting data elements
Here is an example of loose coupling:
<?php // component script $table_id = "person"; // identify the Model $screen = 'person.detail'; // identify the View require 'std.add1.inc'; // activate the Controller ?> <?php // page controller script for the ADD1 pattern require 'classes/$table_id.class.inc'; require 'screens/$screen.screen.inc'; $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); if ($dbobject->errors) { // do error handling } ?>
This has the following differences when compared with the tight coupling example:
$table_id.Loose coupling often correlates with high cohesion.
In the article Write code that is easy to delete, not easy to extend the author has this observation on the meaning of "loose coupling":
A system where you can delete parts without rewriting others is often called loosely coupled.
Code that is loosely coupled isn't necessarily easy-to-delete, but it is much easier to replace, and much easier to change too.
Low cohesion implies that a given module performs tasks which are not very related to each other and hence can create problems as the module becomes large. Low cohesion in a module is associated with undesirable traits such as being difficult to maintain, test, reuse, and even understand. Low cohesion often correlates with tight coupling.
Low cohesion also exists when related functionality which should be placed in a single module is actually spread across multiple modules. This is often done in the mistaken belief that module size is a factor. A module can only be described as "too big" when it performs functions which are not related. On the other hand a module can be described as "too small" when it does not contain all the related functions. A module size can therefore be described as "just right" when it is neither too big nor too small.
Here is an example of low cohesion:
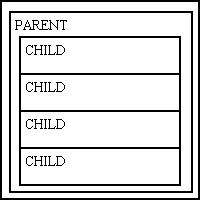
A computer program usually has pieces of code which deal with different areas - user interface (UI) logic, business logic, and data access logic. If these pieces of code are intermingled in a single module/class you end up with a complex class which looks like Figure 1a:
Figure 1a - A single module with multiple responsibilities
Because all the logic is intermingled it would be difficult to make changes without making the code more complicated and difficult to maintain. It would be difficult, for example, to do the following:
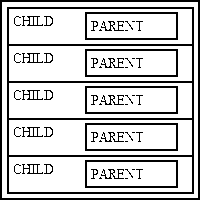
Another variation of low cohesion is shown below in Figure 1b:
Figure 1b - A single responsibility spread across multiple modules
")
Even though encapsulation is supposed to mean that ALL the methods and ALL the data for an entity should be placed together in a single capsule known as a class, there are some cowboy coders out there who seem to think that the Single Responsibility Principle (SRP) is based on size, so they take the code that should be held in a single class and break it into small pieces which are then spread across a large number of micro classes which are spread across a large hierarchy of subdirectories in the file system. I see this most often in various third-party libraries which I have installed via composer, and I have found them virtually impossible to understand and maintain. I tried to track down a bug in one of these libraries, and after spending 30 minutes stepping through the code in my debugger and seeing 100 different classes being loaded, each with a single method containing no more than one or two lines of code, I couldn't see where the fault lay. The code spent so much time jumping from one class to another, from one method to another, I couldn't identify the class that contained the faulty code or even the path it took through that maze of methods
High cohesion is often a sign of a well-structured computer system and a good design, and when combined with loose coupling, supports the general goals of robustness, reliability, reusability, and understandability. Cohesion is increased if:
Advantages of high cohesion are:
While in principle a module can have perfect cohesion by only consisting of a single, atomic element - having a single function, for example - in practice complex tasks are not expressible by a single, simple element. Thus a single-element module has an element that is either too complicated in order to accomplish a task, or is too narrow, and thus tightly coupled to other modules. Thus cohesion is balanced with both unit complexity and coupling.
Here is an example of high cohesion:
If the code which is responsible for user interface (UI) logic, business logic, and data access logic is split into separate modules then you end up with the structure which is an implementation of the 3-Tier Architecture as shown in Figure 2:
Figure 2 - separate modules with single responsibilities
")
Note that the separation of GUI logic, business logic and database logic into their own components matches exactly what Robert C. Martin wrote about in his articles on the The Single Responsibility Principle, SRP: The Single Responsibility Principle and Test Induced Design Damage?.
Note also that you should not infer from this diagram that the entire application can be built with a single component in each of these three layers. There should several choices as follows:
With this structure it is easy to replace the component in one layer with another component without having to make any changes to any component in the other layers.
This structure also provides more reusability as a single component in the Business layer can be shared by several components in the Presentation layer. This means that business logic can be defined in one place yet shared by multiple components.
Fortunately I was not trained in OOP by any of these religious zealots. I trained myself using a combination of common sense, logic, and 25+ years of programming with a mixture of 2nd, 3rd and 4th generation languages. I have successfully built my own development infrastructures in COBOL and UNIFACE which enabled my team members to achieve high rates of productivity, so I saw no reason why I could not repeat this success with PHP.
The ability to perform abstractions is supposed to be a fundamental part of OOP, but because there are so many different descriptions of the term "abstraction" it has become very difficult to find an absolute and easy to understand definition. If you don't understand what a term means then how can you possibly apply it correctly and achieve the correct result? I discuss this very topic in The meaning of "abstraction" which I wrote after discovering the paper written by Ralph E. Johnson & Brian Foote called Designing Reusable Classes which can be summarised with the following statements:
You could say that I have performed an abstraction on all the different definitions of "abstraction" in order to summarise the important points
and reduce to the essential details
. How ironic!
This misconception about the meaning of the word "abstraction" leads to my approach of having a separate class for each database table being subject to criticism such as this:
Abstract concepts are classes, their instances are objects. Classes are supposed to represent abstract concepts.
This is incorrect. Abstract concepts are represented as abstract classes while non-abstract entities are represented as concrete subclasses. Objects cannot be instantiated from abstract classes, only from concrete classes.
The concept of a table is abstract. A given SQL table is not, it's an object in the world. Having a separate *class* for each table is therefore bad OO.
It is clear to me that this critic does not really understand the words that he wrote or how they can be applied in the world of OOP. If you examine the original descriptions more closely and concentrate on the phrases without reference to a specific instance
and not concrete
and couple this with his statement The concept of a table is abstract. A given SQL table is not
then the light should begin to shine. To me the process of abstraction means to separate the abstract from the concrete, the general from the specific. You examine a group of objects looking for both similarities and differences. The similarities can be shared by all members of that group while the differences are unique to individual members. The result of this process should then be an abstract superclass containing the shared characteristics and a separate concrete subclass to contain the differences for each unique instance. If you compare his statements with my implementation you should see that rather than being totally opposed they are actually in complete agreement:
| his statement | my implementation |
|---|---|
| The concept of a table is abstract | That's why I have an abstract table class |
| A given SQL table is not | That's why I have a concrete class for each SQL table |
All the similarities are contained in the abstract class so that they can be shared using inheritance. Each subclass therefore need only define that which is unique to that class.
While the concept of an unidentified database table can be described in abstract terms (it does not have a specific name or set of columns), a particular database table can be described in more concrete terms. Thus a CUSTOMER table contains properties in the form of columns, and it has methods to perform select, insert, update and delete operations. Note that these methods are common to ALL database tables and are built into the database engine, they do not have have to be defined separately for each table. The DDL script for a table is the blueprint for each record within that table, and each record within that table is an instance of that blueprint. The DDL script, the blueprint, can therefore be used to define a CUSTOMER class, and an object of this class can be used to manipulate records (rows or instances) within the CUSTOMER table.
Similarly a table to hold PRODUCT data will have its own DDL script with its own set of columns, and because it has a different set of properties it therefore qualifies to have its own class definition. It will share the same common methods as any other database table - select, insert, update and delete - although the actual implementation will be different for each. This does not mean that each class will contain its own code to generate those SQL queries as it is possible to generate them using a single shared function which is provided with the table name and an array of column names and their values as its input arguments.
One thing you should notice with the above examples is that while CUSTOMER and PRODUCT denote different entities in the real world with their own sets of properties and methods, when the essential data is built into a database they both become tables. They both have properties in the form of columns, and they have identical operations in the form of Create, Read, Update and Delete. It does not matter what type of real-world entity is represented in a database, whether it be active and live like a person or inactive and inert like an invoice, when it is added to a database it becomes just another table, and can be treated just like every other table. My main enterprise application contains over 450 tables which represent a wide variety of entities and concepts which are important to the enterprise, but as far as the software is concerned every one of those 450+ entities is just another table, and can be manipulated and maintained in the same way as every other table.
If a given SQL table is a separate object in the database and its DDL script provides the blueprint for each row (instance) within that table, then all I am doing is following the principles of OOP and using that blueprint to define a concrete class for that table. All abstract concepts which can be applied to any database table are inherited from an abstract class. This is supposed to be what OOP is all about, so why do you insist that I am wrong?
Take a look at the following:
In his article Indirection Is Not Abstraction the author Zed A. Shaw points out another area of confusion:
Abstraction and indirection are very different yet cooperating concepts with two completely different purposes in software development. Abstraction is used to reduce complexity. Indirection is used to reduce coupling or dependence. The problem is that programmers frequently mix these up, using one for the other purpose and just generally screwing things up. By not knowing the difference between the two, and not knowing when to use one vs. the other or both, we end up with insanely convoluted systems with no real advantages.
Just as the definition of encapsulation can be corrupted, so can the definition of abstraction. Zed A. Shaw identifies the following as a prime example:
(v) The process of separating the interface to some functionality from the underlying implementation in such a way that the implementation can be changed without changing the way that piece of code is used.
(n) The API (interface) for some piece of functionality that has been separated in this way
[...]
Even more proof comes from the fact that Java uses the keyword "abstract" to create objects which actually support indirection. Think about it, the "abstract" keyword doesn't reduce, summarize, or generalize a more concrete implementation, but rather creates an indirect path to the real implementation of that function.
If misleading or even incorrect definitions of such basic terms are used from the get-go, it is no wonder that hordes of newbie programmers don't realise that they are being led down the wrong path?
As I have stated earlier I regard the purpose of OOP as taking advantage of Encapsulation, Inheritance and Polymorphism to increase code reuse and decrease code maintenance
and by following a less vague definition of abstraction I have done just that.
My abstract table class has allowed me to define large amounts of sharable code in a single place which can then be reused by hundreds of concrete table classes. My use of polymorphism has allowed me to create a library of just 40 page controllers which can be used with any of my concrete table classes to provide thousands of user transactions. It has also enabled me to create a single View component which can extract the data out of any Model in order to transform that raw data into HTML.
This biggest problem virtually everybody has with OOP is how to split the entire application into a collection of different classes. What should be defined as a class, and what should not? What sort of class hierarchy would be best? Getting back to basics what you are trying to do is build a system where you have software objects that represent Real World (RW) objects. Once you have identified which RW objects your application is supposed to deal with, then surely it follows that you must define a class for each of these RW objects from which you are able to create software objects?
In order to avoid confusion between RW objects and software objects I am going to use a different word. 'Thing' is valid but too common for some people. Another word already in use within the IT community is 'entity', so I shall use that. So an 'object' in the software is a representation of an 'entity' to the business.
Bear in mind that unless you are developing software which directly manipulates a real-world object, such as process control, robotics, avionics or missile guidance systems, then some of the properties and methods which apply to that real-world object may be completely irrelevant in your software representation. If, for example, you are developing an enterprise application such as Sales Order Processing which deals with entities such as Products, Customers and Orders, you are only manipulating the information about those entities and not the actual entities themselves. In pre-computer days this information was held on paper documents, but nowadays it is held in a database in the form of tables, columns and relationships. An object in the real world may have many properties and methods, but in the software representation it may only need a small subset. For example, an organisation may sell many different products with each having different properties, but all that the software may require to maintain is an identity, a description and a price. A real person may have operations such as stand, sit, walk, and run, but these operations would never be needed in an enterprise application. Regardless of the various operations and methods which exist in a real-world object, when an application does nothing more than interface with entities in a database the programmer would be wise to understand the following:
This simple series of observations led me to the following blindingly obvious conclusions:
In my many years of designing, building and using databases one valuable tool is the Entity Relationship Diagram (ERD) without which you cannot design a database that will support the needs of the business. This is where you identify all the entities used in the business and the relationships between them.
To me this seems blindingly obvious:
Also, if you look at the schema (DDL script) for a database table doesn't this qualify as the blueprint for all records of that type? Isn't a record an instance of that blueprint? Doesn't this mean that there are great similarities between the schema for a database table and the contents of a class? Yet there are some OO zealots out there who think that Having a separate class for each database table is not good OO. I shudder to think how they divide their applications into classes. These must be the people who complain Your design is centered around data instead of functions.
This now provides the following definitions to add to the list:
| Entity | A real world 'thing' with which the business has to deal. |
| Object | A software representation of an entity (which is still an instance of a class). |
In OO theory class hierarchies are the result of identifying "IS-A" relationships between different objects, such as "a CAR is-a VEHICLE", "a BEAGLE is-a DOG" and "a CUSTOMER is-a PERSON". This causes some developers to ask the question:
If object 'B' is a type of object 'A', then surely 'B' must be a subtype of 'A'?
This description leads the novice programmer to create separate classes for each of those types and subtypes where the type to the left of "is-a" inherits from the type on the right. This idea is a relic of programming languages from a much earlier age. In the Gang of Four book, which was published in 1994 and therefore was not written with PHP in mind, it states the following:
Specifying Object Interfaces
Every operation declared by an object specifies the operation's name, the objects it takes as parameters, and the operation's return value. This is known as the operation's signature. The set of all signatures defined by an object's operations is called the interface to that object. An object's interface characterises the complete set of requests that can be sent to the object. Any request that matches a signature in the object's interface may be sent to the object.
A type is a name used to denote a particular interface. An object may have many types, and widely different objects can share a type. Part of an object's interface may be characterised by one type, and other parts by other types. Two objects of the same type need only share parts of their interfaces. Interfaces can contain other interfaces as subsets. We say that a type is a subtype of another if its interface contains the interface of its supertype. Often we speak of a subtype inheriting the interface of its supertype.
...
Class versus Interface Inheritance
It is important to understand the difference between and object's class and its type.
An object's class defines how the object is implemented. The class defines the object's internal state and the implementation of its operations. In contrast, and object's type only refers to its interface - the set of requests to which it can respond. An object can have many types, and objects of different classes can have the same type.
The phrase an object's type only refers to its interface
can be interpreted in more than one way. I take the word "interface" to mean "method signature" and not object interface for the simple reason that the keyword interface did not exist in PHP 4 which is the version in which I created the RADICORE framework. Instead I recognised that every table class required methods to implement the same set of CRUD operations which could be defined once in an abstract class and shared through inheritance with any number of concrete subclasses. When I later read Designing Reusable Classes which was published by Ralph E. Johnson & Brian Foote in 1988 I discovered that this was the correct path to follow.
The difference between an object's class and its type does not exist in PHP as classes and objects do not have different types. You cannot assign a "type" to a class, and if you use the gettype() function after you have instantiated a class into an object the result will always be "object", so testing for an object's "type" is a waste of time. There are other functions you may use to identify the class from which an object was instantiated, such as get_class(), get_parent_class() and is_subclass_of(). Personally I have no use for any of these as every concrete class in my Business/Domain layer IS-A database table because they all inherit from the same abstract table class. This means that using the words "type", "supertype" and "subtype" has no special meaning in PHP. They are the same as "class", "superclass" and "subclass".
Just as "type" and "subtype" are meaningless in PHP they are also meaningless in a database as it is simply not done to create a separate table for each subtype when they exist as rows in the same table. If each subtype does not require its own table then why should it require its own class?
Some strictly typed languages treat subclasses differently from subtypes and claim that subclasses provide code reuse while subtypes provide polymorphism, but there are no such distinctions and restrictions in PHP (refer to Subclasses vs Subtypes for details).
Because I do not recognise "types" and "subtypes" I do not have to deal with any relationships between them therefore there are no class hierarchies and no inheritance from one "type" to another. The only inheritance I have is derived from the fact that each table class shares the same protocols as every other table class, and those shared protocols are inherited from a single abstract class.
A novice programmer who doesn't know what I know might create a class diagram like that shown in Figure 3:
Figure 3 - Hierarchy of "dog" classes
")
With this approach you cannot introduce a new type (breed or variety) of dog without creating a new subclass which uses the "extends" keyword to inherit from the supertype (superclass).
OO theory makes a complete dog's dinner of the concept of Subtyping because it implies that each type or subtype is a separate entity and therefore requires its own class and its own table in the database. This is patently ridiculous. In a database there would be a single table for the entire collection, and this table would have a column, probably including the word "type" in its name, to identify the precise type/subtype of each entry. If the entire collection can be held on a single table then the entire collection should have a single class. No competent programmer should ever suggest that having a separate class for each row in a table is a good idea.
In a database the DOG entity would have its own table, and in my software each table, because it has its own business rules, would have its own class. Each table can handle multiple rows, so its class should do so as well. In a database the idea of being able to split the contents of the DOG table into different types, breeds or varieties would not involve separate tables, it would simply require an extra column called DOG-TYPE which would be just one of the attributes or properties that would be recorded for each dog. If there is no need for a separate table for each DOG-TYPE I can see no reason to have a separate subclass for each DOG-TYPE.
If there were additional attributes to go with each DOG-TYPE then I would create a separate DOG-TYPE table to record these attributes, and make the DOG-TYPE column of the DOG table a foreign key which points to the DOG-TYPE column of the DOG-TYPE table, which would be its primary key. This would produce the structure shown in Figure 4:
Figure 4 - hierarchy of DOG and DOG-TYPE tables
")
With this design all the attributes of a particular type/breed of dog are stored on the DOG-TYPE table, so instead of a separate subclass for each DOG_TYPE I would have a separate row on the DOG-TYPE table. When reading from the DOG table you can include a JOIN in the SQL query so that the result combines the data from both tables. This is how you can "inherit" attributes in a database. The introduction of a new type of dog requires no more effort than adding a record to the DOG-TYPE table. There are no changes required to the software, no new classes, no new screens, no new database tables, no nothing. From a programmer's point of view this simple 2-table structure is far easier to deal with than an unknown number of subclasses.
Extracting details for particular types of dog is just as easy as extracting details by any attribute, such as:
SELECT * FROM dog WHERE dog_type='COLLIE' SELECT * FROM dog WHERE gender='MALE' SELECT * FROM dog WHERE colour='LIGHT BROWN'
This is basic stuff to a developer who has experience with working with databases, so why do OO programmers make such a dog's dinner out of it?
The idea that "a CUSTOMER is-a PERSON" is also wrong as this is not the way that this relationship should be represented in an enterprise application. I take my inspiration from the PARTY database in Len Silverston's Data Model Resource Book in which he says that you may be dealing with organisations as well as people who may be treated as customers, suppliers, employers, employees, partners, divisions or whatever. In his model a "customer" is not a "person type" it is just one of many roles that a party may play. This would be represented by the database structure shown in Figure 5:
Figure 5 - hierarchy of party types and party roles
")
In this structure a record on the PARTY table will have a single child record on either the ORGANISATION or PERSON table. You can create as many entries as you like on the ROLE table without having to create a separate class for each role. You can then add as many ROLEs to as many PARTYs as you like. You can even unlink a ROLE from a PARTY by deleting an entry from the PARTY-ROLE table.
Creating inheritance hierarchies like those shown in Figure 3 - Hierarchy of "dog" classes, or multi-level hierarchies, has proved to be a big mistake. In the article Pragmatic OOP written by Ricki Sickenger I found this observation:
A Car and a Train and a Truck can all inherit behavior from a Vehicle object, adding their subtle differences. A Firetruck can inherit from the Truck object, and so on. Wait.. and so on? The thing about inheritance is that is so easy to create massive trees of objects. But what OO-bigots won't tell you is that these trees will mess you up big time if you let them grow too deep, or grow for the wrong reasons.
Programming like this might not be a problem on a small to mid-sized one-man project, since there will be a limit to how much you will need to subclass to get a viable solution to whatever problem you are attacking. But on a 100KLOC+ sized project with thousands of classes, you get into big trouble. The project transforms from manageable inheritance trees and simple classes into an unmanageable mess, with stack traces so deep you need diving skills to reach the offending code. If you are really OOP obsessed and have been using interfaces to avoid being implementation-dependent, then you are in for a real treat. You will end up at the bottom of the stack trace looking at some offending code that clearly fails, but when backtracking to figure out how it got in this state all you encounter is interfaces. So you spend half the time finding out what implementation of said interface is being used and then find out that it is calling super.somemethod(..) which again calles super.somemethod(..) and so on all the way up the inheritance chain.
And then there is the issue of needing to change something in an object near the top of the inheritance stack, which in turn changes the behavior of the objects below in sometimes undefined ways. The deeper the inheritance tree, the worse things get when changing top-level objects. You can of course (and should) have unit tests and regression tests to ensure that the behavior remains the same, but these tests are just crutches that will help you dig yourself into a deeper hole.
An example of this mis-application of the "IS-A" test can be found in Inheritance in Java, Part 1: The extends keyword.
This is what happens when clueless newbies misunderstand how to apply the "IS-A" relationship between objects. If they started with the database they would realise that only two database tables would be required - VEHICLE and VEHICLE-TYPE - where the only relationship is VEHICLE-TYPE (one) to VEHICLE (many). In this way every entry on the VEHICLE table automatically shares/inherits the attributes of the related entry on the VEHICLE-TYPE table. I do not have to create a separate class for each type of vehicle, I simply add a new record to the VEHICLE-TYPE table.
I have never had any problems with inheritance simply because I got it right first time. I spotted the simple fact that every object that will ever exist in my Business/Domain layer IS-A database table, so it seemed obvious to have an abstract table class from which I could inherit to produce each individual concrete table class. Note that I NEVER extend one concrete class to create another concrete class. I was not taught to do it this way, it just seemed the most logical and least complicated thing to do. The idea of doing it some other way never crossed my mind simply because I could not imagine any other way of doing it.
What confused me for a long time with the various descriptions which I read was the use of the word "type" when the author was actually talking about a "class". Tables in a database are not of different "types", they are merely different instances of the same type. The concept of a database table is abstract while a physical table is concrete. It therefore made sense, to me at least, to have an abstract table class which could hold all operations which were common to all database tables, which then meant that each concrete class could be a subtype of this abstract class and could share all the operations in that class as well as holding any additional operations which were unique to that table.
It turns out that my decision to only inherit from an abstract class follows the definition of abstraction which was first published in 1988 in a paper titled Designing Reusable Classes by Ralph E. Johnson and Brian Foote. Who would have thought that a novice like me could have got it right first time simply by using intuition, experience and common sense. I was not taught to do it that way, it just seemed the most logical and simple way to do it.
Wikipedia has this to say about HAS-A:
Has-a is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership. In simple words, has-a relationship in an object is called a member field of an object. Multiple has-a relationships will combine to form a possessive hierarchy.
For example, if you say "a Car has an Engine" this implies that when you instantiate a Car class that class must also create an instance of the Engine class, and you communicate with the Engine object by going through the Car object. If you follow this by saying "an Engine has Valves and Pistons" then when you create an instance of the Engine class it must also create instances of the Valve and Piston classes.
In a relational database there is no such thing as a composite table which is comprised of a number of other tables as each table is a separate and independent entity in its own right and is subject to its own set of CRUD operations. You do not need to go through the Car table to access anything in the Engine table. Each table therefore has its own table class (Model) and its own set of user transactions (tasks) to maintain its contents.
The OO world recognises two types of composition, but I deal with these in the database as follows:
Where a table has relationships with other tables you are not required to insert code into any table class in order to access any of those related tables. While every class contains the identities of any relationships using the $child_relations and $parent_relations arrays, the code which accesses these tables is built into the framework. Refer to Going through the parent to access the child.
It was not until many years after completing my framework that I was informed that I was not following "best practices" when it came to the use of object associations. When I searched for this term on the internet I found the following:
In object-oriented programming, association defines a relationship between classes of objects that allows one object instance to cause another to perform an action on its behalf. This relationship is structural, because it specifies that objects of one kind are connected to objects of another and does not represent behaviour.
In generic terms, the causation is usually called "sending a message", "invoking a method" or "calling a member function" to the controlled object. Concrete implementation usually requires the requesting object to invoke a method or member function using a reference or pointer to the memory location of the controlled object.
- An association represents a semantic relationship between instances of the associated classes. The member-end of an association corresponds to a property of the associated class
- An aggregation is a kind of association that models a part/whole relationship between an aggregate (whole) and a group of related components (parts).
- A composition, also called a composite aggregation, is a kind of aggregation that models a part/whole relationship between a composite (whole) and a group of exclusively owned parts.
In database design, object-oriented programming and design, has-a (has_a or has a) is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership. In simple words, has-a relationship in an object is called a member field of an object. Multiple has-a relationships will combine to form a possessive hierarchy.
The phrase allows one object instance to cause another to perform an action on its behalf
is interpreted to mean that if you have a group of related objects (known as an aggregate) then there is code in one object (the container) which calls methods on the other (contained) objects to perform whatever actions are required to maintain that relationship. The more objects which are in this container then the more complicated is the code. It also means that in the container class each contained object is defined as a property, just like the table's columns.
The phrase the member-end of an association corresponds to a property of the associated class
is interpretted to mean that in a parent-child relationship the parent object must have a property which is an object of the child. This does not make sense to me. The only properties (variables) which belong to a database table are its columns. The database does not contain pointers to rows in a child table, so why should the software representation of a table contain pointers to instances which represent rows in a child table. There is no dependency between the parent and child objects as the tables which they represent are independent entities in the database. It is not necessry to "go through" one to get to the other. The child table is not a dependent of the parent table, and therefore a candidate for dependency injection, they are both independent entities.
In the RADICORE framework if there is a parent-child relationship between two entities (tables) then the parent object does not contain instances of the child object:
The $parent_relations array can be used when constructing SELECT queries to insert SQL JOINS in order to retrieve one or more columns from a parent table.
The $child_relations array is used in any DELETE operations to carry out any referential integrity requirements.
Databases do not have "associations", they have relationships. A relationship is between 2 tables (relations) where one is regarded as the parent and the other is regarded as the child. The existence of a relationship does not require the parent table to store a references to particular rows in the child table, instead it requires the child table to store a reference to the parent in the form of a foreign key whose columns have a logical link to corresponding columns in the primary key in the parent table. This is also known as a "one-to-many" relationship because the parent can have many related rows on the child table, but the child can only link back to a single row on the parent table. In an Entity-Relationship Diagram (ERD) this is often depicted as shown in Figure 6:
Note that the column names used in the child's foreign key need not be the same as the names used in the parent's primary key, but the types and sizes of each column in the foreign key must be the same as the corresponding column in the primary key. Note also that a table can be related to any number of child tables and also to any number of parent tables.
There are certain phrases in those definitions provided in the Introduction which do not reflect the way in which parent-child relationships in a database actually work, so I ignore them as the implementations that they suggest would be incomplete and inadequate.
The phrase The member-end of an association corresponds to a property of the associated class
implies that the parent object must contain a property/variable which points to an instance of an entity on the child object. In other words it must point to a particular row, or rows, within the child table. This is not how it is done in the RADICORE framework. The parent object does not contain any objects which represent rows on a child table, nor does it hold the primary keys of any rows on the child table. All it does is provide the identities of any child tables as well as the identity of the foreign key field(s) which can be used to access the related rows in the child table. This information is held in the $child_relations array. There is also a corresponding entry in the $parent_relations array of the child entity which identifies all the parent relationships which may exist for that child entity.
The phrase allows one object instance to cause another to perform an action on its behalf
implies that in any parent-child relationship you must go through the parent object in order to access the child. This is often interpretted as meaning that you must have a method in the parent object which will allow you to access the child object. This is not the interpretation that is used in the RADICORE framework. It is possible to achieve the act of "going through" in two ways:
It would appear that most programmers are taught to do the former while I have learned the advantages of the latter. Before accessing a child table all that may be necessary is to convert the primary key of the parent into the foreign key of the child, and how and where this conversion is done is a matter for the individual programmer. I say "may" as it is possible to read from a table which has one or more parents without specifying any foreign key values. When writing to such a table it is not necessary to "go through" the parent object to provide the foreign key value as the only requirement is that a value for any non-optional foreign key column is provided. How that value is provided is a matter for the the developer and not the author of any programming principle, especially when that author has little or no knowledge of writing database applications. I do not use custom code inside a parent entity to access a child entity, instead I use generic code within a controller, such as that used in the LIST2 pattern, to access the two entities separately.
In the RADICORE framework none of my table classes contain properties which are set to instances of any child objects, which means that access to those child objects cannot be performed by calling methods on those instances. However, the existence of relationships with child tables is recorded in the $child_relations property and the existence of relationships with parent tables is recorded in the $parent_relations property. It is standard framework code that will use this metadata to instantiate and communicate with those related objects, not customised application code.
In the RADICORE framework the most common method of "going through" the parent in order to access the child is using a task which is built using the LIST2 pattern. In this pattern the Controller will first retrieve one or more rows from the parent object and display them one at a time with a scrolling area. It will extract the primary key of the current row, then it will call the getForeignKeyValues() function to convert that primary key to the foreign key of the child. It will then access the child object using the foreign key as a filter. If it is not possible to use this method to provide the value for a foreign key before the ADD screen is activated, such as when a table requires an additional foreign key, then another approach would be to use the Data Dictionary to set the Control value for that foreign key column to a POPUP button. When this is pressed at runtime it will activate a POPUP form which will allow the user to pick a row from the parent table, thus ensuring that a valid primary key is chosen.
Instead of "going through" the aggregate root I record its identity by creating a primary key on each child table which includes the primary key column of its parent table. This produces a compound or composite key.
The following types of relationship are possible:
| One-to-Many | This is where the child table has a primary key and a separate foreign key. Each parent in this type of relationship can have zero or more children, and the child can have no more than one parent. | |
| One-to-One | This is where the foreign key on the child table is exactly the same as its primary key. Each parent in this type of relationship can have no more than one child, and the child can have no more than one parent. | |
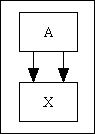
| Many-to-Many | This is often shown using the image to the right, meaning that "many of entity A can be related to many of entity B". This arrangement is not valid in a database. | 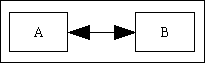 |
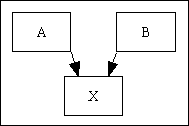
| Instead it has to be implemented as a pair of one-to-many relationships using an additional intersection table as shown as entity "X" in the image to the right. This intersection table then requires a separate foreign key for each of the parent tables, and a primary key which is comprised of both foreign keys in order to prevent the same combination of foreign keys from being added more than once.
Further thoughts on this type of relationship can be found at How to handle a Many-to-Many relationship - standard. |
 |
|
| Multiple | This is where a child table has more than one foreign key which points to the same parent table. It has two variations:
|
 |
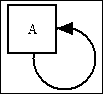
| Self-referencing | This is where a table is related to itself. In this case the name(s) of the column(s) in the foreign key must be different from the name(s) of the corresponding column(s) in the primary key. No row should be related to itself.
Further thoughts on this type of relationship can be found at How to handle a Many-to-Many relationship - Self-Referencing. |
 |
| Optional | This is where a row in the child table can exist without a reference to an entry in the parent table. This is done by designating each column in the foreign key as NULLable instead of NOT NULL. The relation_type on the DICT_RELATIONSHIP table should also be set to NULLABLE so that when an entry on the parent table is deleted the foreign key on all related child entries is set to NULL. |
Regardless of how each of these different types of relationship will be handled in the application, in the database they require nothing more than a link between a foreign key on the Many/Child table and the primary key on the One/Parent table. All the necessary processing is carried out by the framework by means of code in the Controller, the View and the abstract table class which is inherited by every Model (table subclass).
Note that it is possible for a foreign key to exist without a foreign key constraint, in which case all referential integrity must be carried out within the program code.
Prior to switching to PHP I had developed many applications and had dealt with hundreds of tables and relationships, so I knew what had to be done and how to do it. When I saw the code samples written by OO "experts" what immediately struck me was that their solutions were totally different, more convoluted and more complicated than mine. It became quite obvious to me that these people had no prior experience of database applications, had no experience of dealing with different kinds of relationships, but had come up with theories of how it could be done in a OO way without understanding how it had actually been done in non-OO languages. This lack of understanding led to a totally different approach:
In the RADICORE framework every relationship, regardless of its flavour, is defined in exactly the same way:
It is not necessary for a developer to insert custom code into a table class to access a related table as this is handled automatically by the framework, either in a controller script which handles related tables (such as the LIST2 pattern) or standard code within the abstract table class.
There are two ways in which the two tables in a parent-child relationship can be viewed, as shown in Figure 7 and Figure 8:
In this view, used by the LIST 2 pattern, the two tables have separate zones in the screen, and each zone is subject to its own set of method calls. A row from the Parent table is read first, and the primary key is extracted and converted into the equivalent foreign key for the Child table using the getForeignKeyValues() function which is called from within the Controller. This is then used as the $where string to read associated rows from the Child table. Note that with this pattern it is impossible to access entries on the Child table without first going through an entry on the Parent table.
In this view, which is common to all Transaction Patterns, there not a separate zone for the Parent table as the SELECT statement which is generated for the Child table will be customised to include one or more columns from the Parent table by means of an SQL JOIN. This can either be done manually by inserting code into the _cm_pre_getData() method, or you can get the framework to do this for you using the mechanism described in Using Parent Relations to construct sql JOINs. This means that all the data from both tables can be retrieved using a single call to the getData() method on the Child table.
It is precisely because I use a single $fieldarray variable to hold the table's data that I can include any number of columns from any number of tables. This avoids the restriction of only being able to display columns from a single table if I were to define each column as a separate variable with its own getter and setter.
There are some programmers who have been taught that every table should a technical or surrogate key called "ID" whose value comes from a numeric sequence. I was taught differently. If a table has a semantic or natural key which is guaranteed not to change over the lifetime of that record then it is not necessary to create an artificial key. It also avoids the overhead of creating two unique keys - one for the column called "ID" and another for the column containing the natural key.
Some programmers are also taught that a primary key should not be comprised of more than one column. I was taught differently. In a relational database a primary key can be comprised of any number of columns, but use your common sense and don't go overboard. For example, if I have a hierarchy of tables called Parent -> Child -> Grandchild I would probably use the following primary keys and foreign keys:
| Table | Primary key | Foreign key |
|---|---|---|
| Parent | parent_id | |
| Child | parent_id+child_id | parent_id (links to Parent) |
| Grandchild | parent_id+child_id+grandchild_id | parent_id+child_id (links to Child) |
An experienced SQL developer would know that in this example it would not be necessary to create an index for the foreign key as that is already covered by the leading columns in the index for the primary key.
In a real world example of Order -> Order_Item -> Order_Item_Feature
| Table | Primary key | Foreign key |
|---|---|---|
| Order | order_id | |
| Order_Item | order_id+order_item_seq_no | order_id (links to Order) |
| Order_Item_Feature | order_id+order_item_seq_no+feature_id | order_id+order_item_seq_no (links to Order_Item) |
| feature_id (links to Product_Feature) |
I am using a technical key called order_item_seq_no on the Order_Item table as it does not have a suitable natural key. While some inexperienced developer may think that product_id could be used that is not the case. It is possible for the same Order to have several Order_Item entries for the same product_id, but with a different combination of Product_Features
Whenever a user transaction is executed it does not involve code in a single module, it uses several modules, namely a Model, View, Controller and DAO, which work together in harmony, like those shown in Figure 12. While the Model contains a number of different methods it is the Controller which controls which methods are called in which sequence and with what context. This means that some of the logic for a user transaction is contained within the Controller instead of being completely within the Model. It is only after having worked on thousands of user transactions that I have been able to notice patterns of behaviour that have been repeated for different database tables, and I have managed to abstract out these patterns into a set of reusable controllers which are contained within my library of Transaction Patterns.
In my previous language, called UNIFACE, there was no separate Controller and View as these were both combined into a single component in the Presentation layer which communicated with one or more components in the Business layer. There was a separate component in the Business layer for each entity (table) in the Application Model. While each of these entities identified the table structure and the business rules they did not contain any code to deal with relationships as this was handled exclusively in the Presentation layer. If two tables were linked in a parent-child relationship then those two tables were painted in the screen, one inside the other, so that at runtime the UNIFACE software would first read the outer entity, then use the relationship details in the Application Model to convert the outer's primary key into the inner's foreign key so that it could then read the associated rows from the inner entity. This behaviour was logical and simple, so I duplicated it in my PHP code by putting the necessary code in my Controllers where it could be shared with any number of related entities instead of having to insert specific code inside each entity.
In the RADICORE framework each table has its own class, but none of these classes contains either properties or methods to deal with any relationship. Instead the existence of each relationship is identified in either the $parent_relations property or the $child_relations property of the two tables which are involved in that relationship. This information is then used by different components within the framework to deal with that relationship in the appropriate manner. Typically this involves creating a user transaction from a Transaction Pattern which has been designed specifically for that flavour of relationship. While a large number of tables can be maintained using the family of transactions shown in Form Families, others may require a different set of patterns. For example, in those cases where a child table requires the existence of a row in a parent table, because it contains one or more foreign keys, there are two possible approaches:
This pattern will use two entities - the parent (or outer) at the top with the child (or inner) below it. This pattern operates by calling the getData() method on the parent/outer entity using whatever selection criteria which was passed down from the previous screen, which is usually a LIST1. It will display only one row at a time for the parent entity from which it will extract the primary key. It then calls the getForeignKeyValues() function to construct a WHERE string for the foreign key of the child/inner entity using this primary key. This will be used to call the getData() method on the child entity to retrieve as many rows which are available to fit into the screen, subject to the user-defined page size. To create a new entry on the child table the user presses the navigation button labelled 'NEW' which will activate a task which uses the ADD2 pattern. This will then use that WHERE string to populate the relevant foreign key field(s).
This is used when the value for the foreign key is not passed down from the previous screen, in which case the user must supply it manually. Instead of using a textbox control on the HTML form a popup button ![]() will be shown instead. The user presses this button in order to activate a separate POPUP form which will display a list of entries from the parent/foreign table and wait for the user to select one and press the CHOOSE button. This will cause the primary key of the selected entry to be passed back to the ADD2 screen where it will be used to populate the foreign key fields.
will be shown instead. The user presses this button in order to activate a separate POPUP form which will display a list of entries from the parent/foreign table and wait for the user to select one and press the CHOOSE button. This will cause the primary key of the selected entry to be passed back to the ADD2 screen where it will be used to populate the foreign key fields.
Note that there are several different patterns which may be used to deal with many-to-many relationships.
Referential integrity checks the validity of the link between the foreign key and the associated primary key in order to ensure that data integrity is maintained. In the RADICORE framework's Data Dictionary each relationship has a type column which specifies how the relationship is to be treated when deleting entries from the parent/senior table. This has the following options:
If a foreign key constraint has been defined within the DBMS then the framework will do nothing and allow the DBMS to take the necessary action.
While foreign key constraints are processed by the DBMS during insert, update and delete operations, they are totally ignored when performing a SELECT query. However, the RADICORE framework can utilise the contents of the $parent_relations array to automatically retrieve columns from a foreign/parent table during a getData() operation. This is described in Using Parent Relations to construct sql JOINs.
Martin Fowler defines an aggregate as follows:
Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line-items, these will be separate objects, but it's useful to treat the order (together with its line items) as a single aggregate.
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
Aggregates are the basic element of transfer of data storage - you request to load or save whole aggregates. Transactions should not cross aggregate boundaries.
While I agree that the components of an aggregate are separate objects, just like those shown in Figure 7 and Figure 8, I do not agree that the components of the aggregate should be accessed through an aggregate root. This concept does not exist in the database, and has never existed in any software which I have worked on in the last 40 years. No table in a database has any special operations to deal with related tables, so I do not see any reason to put any special methods in any table class to deal with those relationships. It is an alien and artificial concept which does not exist in my universe. I cannot see any advantages of going through an aggregate root, only disadvantages. When retrieving data from two tables there are only two options:
The way that I deal with relationships is through standard code which is built into components in my framework. OO theorists like to over-complicate matters with the following distinctions:
In relational theory it is much simpler than that. A relationship between two tables is signified by one table having a foreign key which points to the primary key of the other table. All accessing is performed using the standard CRUD operations. A composition is achieved by setting all the foreign key fields to NOT NULL, in which case the child row must always contain a reference to a row that exists on the parent table. By setting the type in Referential Integrity to CASCADE all the child records will be deleted when the parent is deleted. An aggregation is achieved by setting all the foreign key fields to NULLable, in which case the child row either contains a reference to a row on the parent table or it does not contain a reference at all. By setting the type in Referential Integrity to NULLIFY all the child records will be updated when the parent is deleted.
In my experience this thing called an object aggregation is nothing more than a collection of parent-child relationships which can be arranged into a hierarchy which could be several levels deep, such as parent-child-grandchild-greatgrandchild-whatever. Two types are supported in the RADICORE framework:
A Composition implies that the contained class cannot exist independently of the container. If the container is destroyed, the child is also destroyed. This is represented in a database by having a separate table for each child, and each row in the child table has a foreign key, which is set to NOT NULL, which relates it to a row in its parent table. Thus a child row cannot be created without providing a value for that foreign key.
Figure 9 - an aggregate ORDER object (a fixed hierarchy)
")
In this hierarchy none of the rows in a child table in any relationship can exist without a corresponding row in the parent table. If a parent is deleted then all of its children must be deleted. Each of the objects in the above diagram is a separate "entity" with separate structures and separate rules, therefore each will have its own class. Note that while each table class knows of the existence of any immediate parent or child tables, it has no knowledge of any other tables which may be related to those parent or child tables.
This collection of tables is joined together to form a fixed hierarchical structure. An inexperienced person would look at this collection and immediately think that it is so unique that it requires a special non-repeatable solution. However, a more experienced person, one who has been trained to look for repeating patterns which can be turned into reusable code, should to able to see something which is quite obvious - this collection contains ten pairs of tables which are joined in a one-to-many/parent-child relationship, and every such relationship will always be handled in exactly the same way. No row can exist in the child table unless it contains a foreign key which contains the primary key of a row in the parent table, and the RADICORE framework has a standard method for dealing with foreign keys. This means that I can deal with this collection of tables by creating 66 tasks which use the following Transaction Patterns:
It is the use of the ADD2 pattern which ensures that no child record can be created without a reference to its parent record.
The only time I would want to read all the data from all of these tables would be if I wanted to produce a printable copy of the entire order, in which case I would construct a task based on the OUTPUT3 pattern.
The idea that I should be forced to go through the aggregate root in order to access any component within the aggregation is also handled differently. Instead of creating a class to handle the responsibilities of the aggregate root I can achieve the same effect by only allowing the LIST1 task for the root table, which is this example is ORDER-HEADER, to be accessible from a menu button. All the LIST2 tasks for each child table are only accessible from a navigation button on the parent task. This means, for example, that you would have to go through both the ORDER-HEADER and ORDER-ITEM tasks before you can access any ORDER-ITEM-FEATURE entries.
Some OO afficionados might spot that this arrangement, where the ADD1 task for the ORDER_HEADER table is totally separate from the ADD2 task for the ORDER-ITEM table, allows me to create an ORDER_HEADER record without any corresponding ORDER_ITEM records, which would technically be invalid. My logic for doing it this way is that it would be far too cumbersome for the user to enter data for the entire order using multiple screens before pressing the SUBMIT button, so I separate the data into one screen at a time so that the order can be built up incrementally. When the ORDER-HEADER record is first created it has an order_status which is set to "Pending", and while it has this status the user can make whatever additions, deletions and corrections to any part of the order as is necessary. Once the user is satisfied that all the details have been entered correctly he can change the order_status to "Complete", but this will not be allowed if there aren't any entries on the ORDER-ITEM table. Once the order comes out of the "Pending" status no further amendments will be allowed to any part of the order except to advance the status to the next value.
Note that in this particular hierarchy the only child table in any relationship which is required is the ORDER_ITEM table. All others are entirely optional. If an entry on a Parent table is deleted then all related entries on the Child table will also be deleted.
What is not shown in Figure 9 is that the ORDER-HEADER table has an additional foreign key to the CUSTOMER table, and the ORDER-ITEM table has an additional foreign key to the PRODUCT table. These are handled using a POPUP button.
An Aggregation implies that the contained class can exist independently of the container. If the container is destroyed, the child is not destroyed as it can exist independently of the parent. Martin Fowler has this to say on the subject of aggregates:
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
This wikipedia page has this to add:
Objects outside the aggregate are allowed to hold references to the root but not to any other object of the aggregate. The aggregate root checks the consistency of changes in the aggregate.
This is not how databases work. There is no such thing as an aggregate root which controls access to every member of that aggregation. An aggregation is nothing more than a collection of one-to-many or parent-child relationships, and the only "requirement" when accessing a relationship is that you obtain the primary key of the parent so that you can convert it to the foreign key of the child.
An aggregation is represented in a database by having a single table for the entities, and a separate table to identify the relationship between one entity and another. The "entity" table does not have any foreign keys for its parents, but the "relationship" table has two foreign keys to the "entity" table, one for the parent and one for the child. This allows for a row in the "entity" table to have zero or more relationships, so at the same time it can have zero or more parents and zero or more children. It is possible to delete a row on the "relationship" table without affecting any row on the "entity" table, but a row on the "entity" table cannot be deleted without first deleting all associated rows on the "relationship" table.
Figure 10 - an aggregate BILL-OF-MATERIALS (BOM) object (an OO view)
")
While a novice may see this as a collection of one-to-many relationships a more experienced person will recognise that not only can a CAR contain an ENGINE but the same engine (by which I mean a similar engine with the same specifications, not the same physical engine with the same serial number) may be contained in several other CARS. This results in what is known as a many-to-many relationship which is implemented by introducing an intermediate intersection or link table which then produces a pair of one-to-many relationships. This means that in this particular structure each of those entities is a record on the same table (in this example it is the PRODUCT table) while the relationship between one of those records and another is a record on the intersection table (in this example it is the PRODUCT_COMPONENT table).
I have seen the structure shown above in Figure 10 in several books on the OO design process where it shows an example of an object which is composed of (or comprised of or acts as a container for) other objects to form a hierarchy which could be many levels deep. Each of these objects represents a separate class. This means that each of those classes would require built-in references to each of its immediate components. This also means that when the Car class is instantiated it also instantiates the Engine, Stereo and Door classes which, in turn, instantiates the Piston, Spark Plug, Radio, Cassette and Handle classes.
In a database application this is absolutely, emphatically, totally wrong. None of the different products has its own class, it has its own row in the same PRODUCT table, and each row in a table shares/inherits the same structure and behaviour as every other row in that table. There is nothing within the PRODUCT class which identifies a row as being either a container or being within a container - this would require the use of a separate PRODUCT_COMPONENT table to implement a many-to-many relationship, as shown in in Figure 11 below, which could then be viewed and maintained using separate tasks.
In the RADICORE framework there is no need for a developer to insert custom code into a table class to access a related table as this is handled automatically by standard code within the framework. It is only necessary to identify the existence of each relationship within the DATA DICTIONARY so that it appears in the $child_relations array of the parent and the $parent_relations array of the child.
Figure 11 - an aggregate BILL-OF-MATERIALS (BOM) object (a database view)
")
This is a pair of tables which form a many-to-many relationship where both foreign keys on the intersection (child) table refer back to the same parent table. This produces a recursive hierarchy which can extend to an unknown number of levels as each parent can have any number of children, and each of those children can also be a parent to its own collection of children, and so-on and so-on. This produces what is commonly known as a Bill Of Materials (BOM).
With this arrangement an entry on the PRODUCT table can exist without any entries on the PRODUCT_COMPONENT table, but the reverse is not true. You cannot insert an entry into the PRODUCT_COMPONENT table without specifying the identities of two different rows in the PRODUCT table. There is no logic in the PRODUCT class which deals with the contents of the PRODUCT_COMPONENT table, just two entries in the $child_relations array. Similarly there is no logic in the PRODUCT_COMPONENT class which deals with the contents of the PRODUCT table, just two entries in the $parent_relations array.
Note that in this particular hierarchy although the effect is to relate one PRODUCT to another there is no direct relationship between the PRODUCT table and itself, instead there is an indirect relationship through the PRODUCT_COMPONENT table which is known as an intersection/link table. An entry cannot exist on this Child table without corresponding entries on the Parent table. If an entry on this Child table is deleted it has no effect on the related entries in the Parent table.
In this example the PRODUCT table contains a primary key called product_id while the PRODUCT_COMPONENT table has the following structure:
| Field | Type | Description |
|---|---|---|
| product_id_snr | string | Identifies the parent (senior) product in this relationship. Links to an entry on the PRODUCT table. |
| product_id_jnr | string | Identifies the child (junior) product in this relationship. Links to an entry on the PRODUCT table. |
| quantity | number | Identifies how many of this product are required in the parent product. |
Note that product_id_snr and product_id_jnr are separate foreign keys which both link back to the same PRODUCT table. They are also combined in the primary key to ensure that the same combination is not used more than once. This forms a recursive hierarchy as it can contain more than the two levels which are indicated by the two tables.
Note also that products can be added or removed from the PRODUCT_COMPONENT table without affecting the contents of the PRODUCT table. While the PRODUCT table can be maintained with a forms family starting with a LIST1 pattern, the PRODUCT_COMPONENT table would be maintained by a forms family starting with the LIST2 pattern. This would show as its parent entity the product that was selected in the PRODUCT table's LIST1 screen, and below it would appear that product's immediate children. To see the entire hierarchy in a single screen you would create a task using the TREE2 pattern, or you could export it to a spreadsheet using the OUTPUT6 pattern.
This shows that the two tables can be handled independently of each other. The fact they they are related is built into the database structure which is then copied into the $child_relations and $parent_relations arrays of each table class. The rule that says that an entry on the PRODUCT table cannot be deleted if it has any entries on the PRODUCT_COMPONENT table is enforced by the framework using the settings in the $child_relations array. The rule that an entry cannot be added to the PRODUCT_COMPONENT table without supplying valid values for two entries from the PRODUCT table is enforced by the ADD2 task where the identity of product_id_snr is passed down from the parent entity in the LIST2 task and the identity of product_id_jnr is selected from a POPUP task.
I have been told more than once that my practice of creating a separate class for each database table is not good OO. I have been told that each entity in the real world has to have its own class, and if its data needs to be spread across multiple database tables then that is a problem with the database which can be ignored as it can be dealt with using a Object-Relational Mapper. They seem to think that objects such as ORDERS (see Figure 9) and PRODUCTS (see Figure 10) should be handled within a single class, and all associations must be handled by going through the aggregate root. As I had never been taught this nonsense I never acted upon it for the simple reason that databases do not have "associations", they have "relationships" where the only requirement is that the child table has a foreign key which refers to the primary key of a row in the parent table. In a database I do not have to go through the parent table in order to access a child, so I never put code in the parent's class to access any of its children. If I want to show data from the parent table and a child table in the same screen then I create a task based on the LIST2 pattern which accesses those two table independently.
This means that I never read data from a table until I actually want to show it on a screen as to do otherwise would be a waste of time. I only ever read data from a table when the user actually requests a task which displays or processes data from that table. This seems sensible to me, but there are others out there who seem to think that when dealing with an aggregation every member is a property of the aggregate root and should be instantiated and loaded with data whenever that root object is created. I remember reading a newsgroup post several years ago from someone who had written an application for his school. In his database he had a group of related tables called SCHOOL, TEACHER, STUDENT, ROOM, SUBJECT and LESSON, but he was complaining that his application was taking too long to load. It turned out that when he instantiated the SCHOOL class he was also instantiating all the other classes and loading in all their data even though it wasn't actually required. No competent database programmer would ever do it this way. Nobody would ever load that much data into a single object as it would never be displayed to the user in a single screen. He needed to stop loading all his data into a single object and concentrate on building separate tasks to display the contents of each table when it was actually required, and then only reading from the database that data which can fit into a single screen. This is precisely what I had done in a similar application called a Prototype Classroom Scheduling Application which is available in the download of my RADICORE framework. You can also run it online as an option under the "PROTO" menu so you can for yourself how quick it is to display the contents of different tables.
Shortly after I released my framework as open source I received the complaint from someone asking "Why are you using inheritance instead of object composition?" My first reaction was "What is object composition and why is it better than inheritance?" Eventually I found an article on the Composite Reuse Principle (CRP) (or should that be CRaP?) but it did not explain the problem with inheritance, nor did it explain why composition was better. Those two facts alone made me conclude that the whole idea was not worth the toilet paper on which it was printed, so I ignored it. When I tried to identify the pros and cons of inheritance I came across this statement in the Gang of Four book:
Class inheritance is basically just a mechanism for extending an application's functionality by reusing functionality in parent classes. It lets you define a new kind of object rapidly in terms of an old one. It lets you get new implementations almost for free, inheriting most of what you need from existing classes.
However, implementation reuse is only half the story. Inheritance's ability to define families of objects with identical interfaces (usually by inheriting from an abstract class) is also important. Why? Because polymorphism depends on it.
Later on it says:
Implementation dependencies can cause problems when you're trying to reuse a subclass. Should any aspect of the inherited implementation not be appropriate for new problem domains, the parent class must be rewritten or replaced by something more appropriate. This dependency limits flexibility and ultimately reusability. One cure for this is to inherit only from abstract classes, since they usually provide little or no implementation.
In Object Composition vs. Inheritance I found the following statements:
Most designers overuse inheritance, resulting in large inheritance hierarchies that can become hard to deal with. Object composition is a different method of reusing functionality. Objects are composed to achieve more complex functionality. The disadvantage of object composition is that the behavior of the system may be harder to understand just by looking at the source code. A system using object composition may be very dynamic in nature so it may require running the system to get a deeper understanding of how the different objects cooperate.
[....]
However, inheritance is still necessary. You cannot always get all the necessary functionality by assembling existing components.
[....]
The disadvantage of class inheritance is that the subclass becomes dependent on the parent class implementation. This makes it harder to reuse the subclass, especially if part of the inherited implementation is no longer desirable. ... One way around this problem is to only inherit from abstract classes.
This leads me to the following conclusions:
The idea that you should only ever inherit from abstract classes was first documented in 1988 by Ralph E. Johnson and Brian Foote in their paper Designing Reusable Classes. This is discussed further in The meaning of "abstraction". Inheritance, when used properly, is a powerful tool which can help OOP in its aim to assist in the production of more reusable code, as discussed in Inheritance is NOT evil.
Object composition is inferior because of the following:
As far as I am concerned object composition is a device used by those programmers who do not understand how to use inheritance properly. They are told to avoid inheritance like the plague without understanding why, so they don't understand when inheritance is better than composition. Take the following statement from one of my critics, for example:
I understand the point of reusing code to generate SELECT/INSERT/UPDATE/DELETE statements, but you can do that without having to create a class for every table you have. Say I wanted to talk to the table 'cars'. I'd compose an object by creating an instance of a Table class and add rules represented as objects to it. I think that if you ask some good designers they will tell you that an approach which uses instances of a single Table class is better than one which requires the declaration of a new class for each new table.
I don't know about you, but the this idea sounds like far too much work to me. I would have to hold the rules for the 'cars' table somewhere, then have code to instantiate the Table class into an object and then inject the rules for 'cars' into it. My method can replace all this unnecessary code with the single word extends. I would put all the rules for the 'cars' table into a Cars class which would then inherit all the standard code from an abstract Table class. I am achieving the exact same result, but with far less code. How can you possibly say that my method is wrong!
Another reason to dismiss the principle favour composition over inheritance
as being illogical is the fact that it proposes replacing inheritance with composition which, according to what has been written about OO theory elsewhere, are totally incompatible concepts and therefore incapable of being used to achieve the same result. Inheritance is supposed to be the result of identifying "IS-A" relationships while composition is supposed to be the result of identifying "HAS-A" relationships. I challenge anyone to show me an example where two objects can exist in both an IS-A and HAS-A relationship at the same time. The two concepts are not interchangeable, therefore you cannot substitute one for the other.
I have yet to see any sample code which demonstrates that something which can be done successfully with inheritance can also be done with composition, so until someone provides proof that these two ideas are actually interchangeable I shall stick with the idea that works and consign the other to the dustbin.
I have written more on this topic in the following:
A "mapper" is something which sits between two objects in order to ensure that the output generated by one object is converted to the input expected by the other object. If the objects can engage in a two-way conversation then the mapper is expected to handle the conversion in both directions.
The reason that one might want to employ a mapper is that if the message format or contents in one of the objects ever changes then instead of making a corresponding change in the second object you make the change in the mapper instead.
This might have benefits in a situation where the communication is many-to-mapper-to-one as the change need only be made in the single "mapper" object instead of within each of the "many" objects, but in a situation where the communication is one-to-mapper-to-one there are no savings. On the contrary, in such a situation the introduction of a mapper does nothing but provide an extra level of complexity, more code to write, more code to test, more code to document and more code to debug. Just because a mapper may provide benefits in some circumstances does not guarantee that benefits will be provided in all circumstances. I've heard people estimate that as much as 70 percent of a given project's programming and debugging is spent in the object-relational mapping code, so as far as I am concerned this is a totally unnecessary overhead that can easily be eliminated.
An OR Mapper is something that sits between an in-memory object and a relational database. It is required when the structure of one is different from the structure of the other so that data being moved around can be correctly reformatted for the structure of the receiving component.
OR Mappers were originally created when relational databases that were accessed via SQL statements first appeared, and developers were reluctant to learn (or incapable of learning) a new language. Thus all SQL statements were maintained by SQL developers in separate objects, leaving the application developers to continue using the language of their choice. It was not necessary that the data structure in the application code be identical to the data structure in the SQL code as any differences could be dealt with programmatically. Not only was it possible for the two data structures to be different, over periods of time it became inevitable as one side was modified without the corresponding changes being made to the other side.
Another reason for the growth of OR mappers is because a lot of OO programmers have a nasty habit of designing complex object structures and hierarchies without any regard to the physical database design, often because the database is built after the event by different people. Because an OO database (OODBMS) which can support object structures and hierarchies without any mapping code is as rare as rocking horse shit, it is necessary to build a relational database (RDBMS) using different principles, then to write code to deal with all the differences between the Object Oriented and the Relational components.
I have found a simple way to avoid this unnecessary complexity: instead of allowing the structure of the two components to be different, thus requiring the need for a mapper, why not keep the two structures completely synchronised, thus removing the need for a mapper? If there are no differences then you do not need any code to deal with those differences.
I do not build my object hierarchy then add on a database as an afterthought, I design my database up front using the process of normalisation, then I create my class structure. This is very easy because I import the database schema into my Data Dictionary then export those details to my application, which produces one class file and one structure file for each database table. If the structure of any table changes then the import process can be run again to detect and deal with those changes, and the export process will regenerate the structure file. Note that it does not have to regenerate or update the class file as no methods or properties are affected. Thus my class structure and database structure are always in sync, which means that I have absolutely no need for any type of mapper.
This simple and effective process means that I have a separate class for each database table, which, according to the OO purists, is not good OO. Ask me if I care!
Whether you like it or not both the data and the software which manipulates that data have some sort of structure:
In the early 1980's all the courses on Structured Programming emphasised the point that the program structure should mirror the data structure as closely as possible, so if the structure of the data changed then the structure of the code which accessed it should change accordingly. Having personally witnessed the advantages of writing and maintaining code which has the same structure as the data I simply would not consider doing it any other way, so when someone tells me that this approach is wrong I can only say - BALDERDASH! POPPYCOCK! PHOOEY!
Another reason to avoid OR mappers is their impact on performance. The following quote comes from http://www.polepos.org, a company that provides benchmarking software:
The use of O-R mapping technology like Hibernate or JDO O-R mappers has a strong negative impact on performance. If you can't compensate by throwing hardware at your application, you may have to avoid O-R mappers, if performance is important to you.
This theme is followed up in Object Relational Mappers are EVIL.
This type of object deals with the translation of column/field names between one object and another, such as a data access object which communicates with the database, a business object where all business rules are applied, and a presentation object which displays output to and accepts input from the user.
I have been programming for 25+ years, and in that time I have used numerous languages and numerous file systems, and I have worked on numerous different projects with different teams of designers and developers. In all that time I have NEVER, EVER come across the idea that different components should have different names for the same piece of data. It has always seemed so logical to keep the same item names throughout the application. Indeed, some languages have made it virtually impossible to do otherwise, while others will only allow it with the addition of volumes of extra code. It is only by deliberately choosing a different naming scheme between different objects that the need for the services of a mapper arises. But by doing what comes naturally, by applying common sense and logic, the naming schemes are identical and thus there is absolutely no need for a mapper.
As far as I am concerned it is normal to have a single naming scheme for data items throughout the application, regardless of the type or size of the application. To deliberately choose more than one naming scheme strikes me as being abnormal if not perverse. Only a masochist, someone who seeks a path of pain, would make such a choice.
When programming with PHP for example, the various functions with which data can be accessed and manipulated seem to assume a single naming scheme. For example:
*_fetch_assoc functions will present each row of data as an associative array of name=value pairs where name is the column name as defined in the database schema. Apart from modifying each SELECT statement to specify name AS alias there is no mechanism whereby an alternative naming scheme can be introduced.name is the only key into the array. It is simply not possible to access any item within the array with anything other than the name given to it when the array was constructed.name=value into <name>value</name>. It can do this without having any names hard-coded as whatever name is read in is written out without any conversion or modification whatsoever. To perform a conversion from one naming scheme to another would require a deliberate act to which I would ask the question why bother?name=value pairs.As you can (or should) see, the use of a single naming scheme throughout the application requires the least amount of effort and presents the least amount of problems. Any attempt to introduce multiple naming schemes would require an enormous amount of effort for absolutely no gain (that I can see) whatsoever. I don't know what you learned at school, but to me any effort which produces no tangible benefit is wasted effort and should therefore be avoided as a Bad Thing ™ The use of mappers signifies wasted effort, therefore they have no place in my methodology.
When designing an application which uses a relational database it is essential that the database be properly normalised otherwise its performance may be catastrophic. The process of data normalisation requires the following of a number of rules and techniques which must be implemented in a set sequence, from 1st Normal Form (1NF), 2nd Normal Form (2NF) and 3rd Normal Form (3NF), and possibly all the way up to 6th Normal Form (6NF).
When designing the objects which are to be used in an application you need to identify the individual classes, their properties and their methods. This requires the following of a set of rules and techniques which are not as well defined and are therefore open to a lot of interpretation (and also mis-interpretation).
If you employ both design methodologies, one for the database and another for the software, it is more than likely that you will end up two structures which are not entirely compatible (see Object-Relational Impedance Mismatch). In order to allow the two incompatible components to communicate with one another the usual answer is to introduce a third component, known as an Object Relational Mapper, to sit between the two and deal with the differences.
To my mind once you have designed a properly normalised database it is not necessary to carry out a separate design process for the software objects as all you require has already been provided:
So if everything you need - classes, properties and methods - has been provided by Table Oriented Design (TOD), why waste time with Object Oriented Design (OOD)? Why waste time producing two designs which are so different that it requires an extra component to deal with the differences?
It is not considered good practice for each object to have too many responsibilities or concerns otherwise it may become too large and complex, and therefore difficult to maintain. Here is another problem - how do you identify those responsibilities or concerns which can be split off into other objects? Again my previous experience provided valuable insight. I have spent many years writing 1-tier systems in COBOL and 2-tier systems in UNIFACE, so I am well aware of how much complexity and duplication of code these involve. When proper support for the 3-tier architecture was introduced into UNIFACE in the year 2000 I managed to convert my 2-tier infrastructure into 3-tier and I could immediately see the benefits. This has been my favourite design pattern ever since.
For those of you who are unfamiliar with the 3-tier architecture it involves the separation of application logic into three tiers or layers:
Having successfully implemented this degree of separation in one language I saw no reason why I should not be able to do the same in PHP. To this end I decided that all the classes built around business entities would go into the middle business layer and be responsible for nothing more than business logic, while presentation and data access logic would be moved to different components.
This now provides the following definitions to add to the list:
| Presentation Object | An object or component which exists in the presentation layer and which contains nothing but presentation logic. |
| Business Object | An object or component which exists in the business layer and which contains data validation and business logic. It may also contain information which may be passed to other objects to help them carry out their responsibilities. Each of these objects will be associated with a database table. It is possible for an object to link with other objects in order to access multiple tables for a single task. |
| Data Access Object | An object or component which exists in the data access layer and which contains nothing but data access logic. It is possible to have a separate DAO for each DBMS so that an application can be switched from one DBMS to another without having to change any code in the Business layer. |
Please note that by "logic" I mean program code, not data. Information is not Logic just as Data is not Code.
There are some who would argue that it is possible to achieve a greater degree of separation which means creating more than three objects, but having witnessed a disastrous attempt at implementing a ten-tier structure I can only disagree.
However, after I had built my infrastructure someone pointed out that I had actually implemented a version of the Model-View-Controller (MVC) design pattern as my presentation layer contained a controller component and a view component, with my business layer containing the model component. Upon reading the description of this design pattern I could see the similarities, but this was pure coincidence, not deliberate design.
My approach is simple, yet frowned upon by some OO fanatics because it breaks their rules. After having built many different database applications my approach is based on the fact that I noticed that every database application has two basic parts:
I further noticed that:
In order to take advantage of encapsulation, inheritance and polymorphism I decided on the following implementation:
The follows precisely what is described in Designing Reusable Classes where it says that after identifying that common protocols (operations) exist in several entities that you should place those protocols into an abstract class so that they can be inherited (shared) by all the entity subclasses.
Point (1) led me to create the following set of methods for each database table object:
getdata($where) - to retrieve any number of records from the database based on the criteria in $where.insertRecord($array) - to add a single database record using the array of name=value pairs.updateRecord($array) - to update a single database record using the contents of $array.deleteRecord($array) - to delete a single database record using the contents of $array.Some of these methods only deal will single database records, so later on I added the following:
insertMultiple($array) - to add multiple database records.updateMultiple($array) - to update multiple database records.deleteMultiple($array) - to delete multiple database records.Each concrete class then encapsulates both the data which is stored in a database table and the operations which can be performed on that data. The operations which are common to every database table are shared using inheritance while any unique business rules can be added to any subclass using the predefined "hook" methods.
Point (2) is directly related to polymorphism, one of the fundamental principles of OOP. This means that in the situation where there are database tables for Customer, Product and Invoice I do not do what I have seen others do and create methods such as the following:
I can achieve the same result with the following:
getData() method on the Customer, Product or Invoice object.insertRecord() method on the Customer, Product or Invoice object.updateRecord() method on the Customer, Product or Invoice object.deleteRecord() method on the Customer, Product or Invoice object.This means that I can use generic controllers which call generic methods on whatever object they are told to work with. This also means that the same controller can be used with ANY object to achieve a predictable result without any modification, thus making them infinitely reusable. This high level of reusability would seem to indicate that my implementation achieves low coupling which is supposed to be a Good Thing (™).
If I am using encapsulation, inheritance and polymorphism to create reusable code, which is one of the fundamental aims of OOP, how is it possible for these OO fanatics to tell me that my methods are wrong? If I can achieve the desired result by breaking their precious rules, then doesn't it indicate that their precious rules are in desperate need of serious revision?
When I was learning PHP I had 3 sources of information - the PHP manual, books and online tutorials. I loaded some of the sample code onto my home PC and stepped through it with my debugger which was built into the Integrated Development Environment (IDE) which I chose to use instead of a plain vanilla text editor. As I became more and more familiar with PHP I noticed that its handling of data arrays was far superior to that which was available in my previous languages. It meant that I could pass around collections of data whose contents were completely flexible and not tied to a particular pre-defined record structure. The data passed into objects from both the Presentation layer (via the $_POST array) and the Data Access layer (via the result on an SQL SELECT query) appears as an array, and this can contain a value for any number of fields/columns. The foreach function in PHP makes it easy to step through an array and identify what values it contains for what fields. This is discussed in OOP is about information hiding.
However, in all of the OOP samples I saw in books or within internet tutorials I noticed that the same convention was followed:
When I saw this I asked myself some simple questions: If the data outside of an object exists in an array, why is the array split into its component parts before they are passed to the object one component at a time? Can I access an object's values in an array, or am I forced to use a separate class variable for each field/column?
The answer turns out to be a choice between:
$this->column // each column has its own class property and $fieldarray['column'] // all columns are held in a single class property
Guess what? To PHP there is no discernible difference as either option is possible. The only difference is in how much code the developer has to write. I then asked myself another question: Under what circumstances would a separate class property for each piece of data, forcing each to have its own setter (mutator) and getter (accessor), be the preferable choice?
The answer is as follows:
This scenario would fit something like an aircraft control system which relies on discrete pieces of data which are supplied by numerous sensors all over the aircraft. When changes in the data are processed the system may alter the aircraft's configuration or it may update the pilot's display in the cockpit.
This scenario does NOT fit a web-based database application for the following reasons:
Having built enterprise applications which have hundreds of database tables and thousands of user transactions I realised straight away that having separate class properties for each table column, each with its own setter and getter, would be entirely the wrong approach as it produces tight coupling which in turn greatly restricts the opportunity for reusable software. As the aim of OOP is supposed to be to increase the amount of reusable software I decided that any practice which did not support this aim was something to be avoided.
Consider the following sample code which is required when using a separate property for each table's column:
<?php require_once 'classes/person.class.inc'; $dbobject = new Person(); $dbobject->setUserID ( $_POST['userID'] ); $dbobject->setEmail ( $_POST['email'] ); $dbobject->setFirstname ( $_POST['firstname']); $dbobject->setLastname ( $_POST['lastname'] ); $dbobject->setAddress1 ( $_POST['address1'] ); $dbobject->setAddress2 ( $_POST['address2'] ); $dbobject->setCity ( $_POST['city'] ); $dbobject->setProvince ( $_POST['province'] ); $dbobject->setCountry ( $_POST['country'] ); if ($dbobject->insertPerson($db) !== true) { // do error handling } ?>
This suffers from the following deficiencies:
Contrast this with the following code which can be used when the data array is not split into its component parts:
<?php require_once 'classes/$table_id.class.inc'; // $table_id is provided by the previous script $dbobject = new $table_id; $result = $dbobject->insertRecord($_POST); if ($dbobject->errors) { // do error handling } ?>
This is loosely coupled and offers the following advantages:
The use of Common Table Methods which are inherited from the abstract table class means that this code, which appears in all Controller components, is a product of the fact that the only operations that can be performed on a database table are Create, Read, Update and Delete (CRUD), so there is no need to vary the names of these for different tables.
Extracting the data from an object, such as when transferring it to the View object, does not require a collection of getters as it can be done with one simple command:
$fieldarray = $dbobject->getFieldArray();
This array can contain any number of columns from any number of rows and from any number of tables, which means that is does not require different variations in the code to deal with different combinations.
Another reason which caused me to reject the idea of having a separate class property for each column, each with its own setter and getter, is that it restricts each object to only being able to deal with columns on that particular table.
Instead of doing what some people seem to do and design a complex class hierarchy before writing any code, I did exactly the opposite. I wrote the code, then I split it into a suitable class hierarchy which ended up as only two levels deep - an abstract superclass containing generic code for all database tables, and a series of concrete subclasses for individual database tables. I wrote a class for one database table, then tested it using a family of six standard screens. Once this was working I made a copy of the entire class, then modified it to deal with a second database table. The next exercise was to compare the two classes and determine which code was duplicated and could therefore be shared, and which code was specific to just one database table and therefore could not be shared.
The standard mechanism for sharing code in the OO paradigm is through inheritance, so I put all the common code into a class of its own, a generic table class. For each individual database table I created a separate table class which held specific information for that database table. As each database table subclass 'extends' the generic table superclass the resulting object shares or 'inherits' all the properties and methods from the superclass.
As a final step I took out all the code which communicated with the database and put it into a separate SQL/DML class. This now exists in the data access layer and is sometimes referred to as the data access object or DAO.
There are some circumstances when I find it useful to create subclasses of my database table subclasses, and these are documented in When and how do you use subclassing?
My development infrastructure was written in PHP 4 which does not have the more comprehensive object model of PHP 5. Yet it works, so the OO functionality provided by PHP 4 must be perfectly adequate. My infrastructure will also run under PHP 5 without modification. This leads me to believe that some of the new OO features in PHP 5 are merely cosmetic and offer no functional benefit. They must have been put there just to satisfy those OO zealots who say 'Java/C++ does this-and-that, so I want PHP to do the same'.
An example of this can be found with object interfaces which the PHP manual describes thus:
Object interfaces allow you to create code which specifies which methods a class must implement, without having to define how these methods are handled.
Take a look at the following code:
<?php // Declare the interface 'iTemplate' interface iTemplate { public function setVariable($name, $var); public function getHtml($template); } // Implement the interface class Template implements iTemplate { private $vars = array(); public function setVariable($name, $var) { ....code.... } public function getHtml($template) { ....code.... } } ?>
Exactly the same result can be achieved with this code:
<?php
class Template
{
private $vars = array();
public function setVariable($name, $var)
{
....code....
}
public function getHtml($template)
{
....code....
}
}
?>
So my question is this - if I can achieve exactly the same result without using interfaces, then what is the benefit of using them? Why should I waste my time writing more lines of code than is necessary?
After doing a little investigation I discovered the following comment regarding interfaces:
This topic is discussed more in Object Interfaces.
The reason for this is that PHP has its own method of dealing with arguments of different types, or arguments which are optional, while other languages can only do this through the use of interfaces.
I also came across articles which proposed the use of delegates instead of interfaces. Delegates are like interfaces except that they do not require the callee to declare an explicit interface. The caller must have access to the interface declaration in the form, but it is not necessary for the target to explicitly declare the implementation of an interface. Anonymous classes in Java are used for the same purpose.
This raises another important question - if interface declarations are so good, why do these statically typed languages keep using such cumbersome methods of avoiding them?
As far as I am concerned the word 'interface' means 'application program interface' (API) which means the method/function name and its associated arguments. I do not need to define method names in one place and interfaces in another when a single definition will achieve the same result.
All too often the OO zealots like to say 'you must prove you are one of us by implementing design patterns'. This usually means THEIR favourite patterns from THEIR favourite author (see all the references to Martin Fowler's Patterns of Enterprise Application Architecture (PoEAA) in In the world of OOP am I Hero or Heretic?). This again produces another dilemma as there are dozens of books by different authors containing hundreds of different design patterns, so which ones do you choose? If you have the time to examine all of these books closely you should observe the following:
So as you can see there is not one set of universally accepted design patterns just as there is not one universally accepted definition of OOP, which means that if you dare make the 'wrong' choice (according to the paradigm police) you are automatically a heretic.
Some programmers start by picking a collection of what they deem to be 'suitable' patterns (or what they are told are suitable to 'real' OO programmers) then attempt to implement them. This, in my opinion, is the wrong approach. Although it is a good idea to be aware of what patterns exist, and what problem each pattern is supposed to solve, you should not seek to employ any particular pattern until such time as you encounter a situation that the pattern was designed to solve. There may be a choice of alternative patterns for a particular situation, so you must take the time to choose the one which is most appropriate for your circumstances.
The only exception to this, where a pattern is deliberately chosen before the first line of code is written, should be a high-level architectural pattern. Before I wrote my own development infrastructure for PHP, for example, I knew that I wanted to employ the 3-tier architecture as I had used it with great success in a previous language. It wasn't until afterwards that someone pointed out that my code also included an implementation of the Model-View-Controller (MVC) design pattern, but that was entirely accidental, not deliberate. The only other design pattern that I have implemented after reading about it is the Singleton. There may be other recognisable patterns within my code, but that is pure coincidence.
For more of my views on design patterns please refer to Design Patterns - a personal perspective.
I have never considered multiple inheritance to be the solution to any problem I have encountered, yet others seem to employ it at every possible opportunity. Take the situation where a screen is required to show data from two database tables, TableA and TableB, which exist in a one-to-many relationship. The screen is required to show one occurrence from TableA at the top, with multiple related occurrences immediately below it.
According to some people, the Controller part in the MVC design pattern can only communicate with a single Model object, therefore under these circumstances this object must be a composite of TableA and TableB. It will therefore need one set of methods to access the data from TableA, and another set of methods to access the data from TableB. It will also need to inherit the properties and methods of the original TableA and TableB classes, hence the need for multiple inheritance.
My approach is far simpler. The first thing is to ignore the rule that "a controller can only access one object" and build a controller that is specifically designed to access any two objects which exist in a one-to-many relationship. That means that I do not need to construct a composite object, I do not need different methods to access the data from each of the two tables as the standard methods are more than adequate, and I certainly do not need multiple inheritance. What is more, that single controller can deal with ANY pair of tables which exist in a one-to-many relationship.
I once came across a post in a PHP newsgroup where someone complained that he could not write a routine to filter user input without multiple inheritance, and because PHP did not support multiple inheritance such a routine was physically impossible. As an example he took a piece of data which had to meet the conditions is_numeric and is_required. In his design he wanted to create an object for that piece of data which inherited from the numeric class as well as the required class. I don't know about you, but I can test that a piece of data meets the is_numeric and is_required conditions without putting that piece of data into its own object, and I can certainly do it without requiring any sort of inheritance, multiple or otherwise.The poor deluded soul did not understand that the need for multiple inheritance was a product of his design, and a different design would remove this need. Other programmers can write code which filters user input without the need for multiple inheritance (see below), so why can't he?
This is an example of how this requirement is satisfied in my framework:
$this->fieldspec['field1'] array('type' => 'integer', 'size' => 5, 'minvalue' => 0, 'maxvalue' => 65535, 'required' => 'y'); $this->fieldspec['field2'] array('type' => 'numeric', 'size' => 12, 'precision' => 10, 'scale' => 2, 'blank_when_zero' => 'y', 'minvalue' => 0, 'maxvalue' => 99999999.99);
Can you see what I'm doing here? I am describing the characteristics of each piece of data, which then enables me to have a single routine which checks that each piece if input data conforms to these characteristics. If it doesn't then I can generate a meaningful error message and send the data back to the calling component. Simple, effective and flexible, and all without any of this "I can only do it with multiple inheritance" nonsense.
By using this simple and straightforward approach I have managed to produce a development infrastructure in PHP which has the following characteristics:
High cohesion leads to high reusability, and as the levels of reusability within my infrastructure are high it must demonstrate that my implementation is more than adequate.
This means that the contents of any array can be changed without requiring the modification of any interface (API).
Low coupling leads to high reusability, and as the levels of reusability within my infrastructure are high it must demonstrate that my implementation is more than adequate.
There is also low dependency as the order in which fields are defined within the database has absolutely no effect on how those fields are accessed within the business object or written to the XML document or processed during the XSL transformation.
Low dependency leads to high reusability, and as the levels of reusability within my infrastructure are high it must demonstrate that my implementation is more than adequate.
If my infrastructure manages to achieve all this, then who are you to tell me that my implementation is wrong, invalid or impure?
Here is a selection of criticisms generated by members of the OO Purity League:
Some people like to use a function-driven design instead of a data-driven design, and complain when somebody dares to be different. If you inspect my infrastructure you should notice that in the different layers some components are designed around functions while others are designed around data. This is because some objects are entities while others are services:
Unlike an entity which can have numerous methods to load, modify and interrogate its data (state), with a service the data is loaded and processed in a single operation without being stored for later interrogation or manipulation. Business rules should only ever be defined within entities and never within services. A service which is properly designed should be able to performs its operation on any entity thus avoiding the need to have a different version of the service for different entities.
The components in the RADICORE framework fall into the following categories:
All these services are pre-written and supplied by the framework. It is only the entities which need to be created by application developers, but even this has been automated. You design and build your database first, then import each table into the Data Dictionary then export the data to create each table's class file and structure file. All the standard operations are supplied from the abstract table class so the only coding that is required is for the developer to add custom processing into the relevant "hook" methods.
You may also wish to take a look at Why is your design centered around data instead of functions?
My framework is an implementation of the 3 Tier Architecture and Model-View-Controller design pattern (see Figure 12), and if you look closely enough you will see that each component does exactly what it is supposed to. My implementation may be different from yours, but that does not mean that it is wrong.
Figure 12 - MVC plus 3 Tier Architecture
")
Note that each of the above boxes is a hyperlink which will take you to a description of that component. A more detailed diagram can be found in RADICORE - A Development Infrastructure for PHP.
The problem with the term 'separation of concerns' (which is sometimes expressed as 'separation of responsibilities' or 'separation of logic') is that different people have a different interpretation of what this actually means. If you study my infrastructure you should notice the following division of responsibilities:
In the RADICORE framework this architecture is implemented as follows:
By being part of the framework, all Controllers, Views and Data Access Objects are totally application-agnostic in that they do not contain any information regarding any application. All application knowledge - which includes the database structure, validation rules, business rules and task-specific behaviour - exists in, and only in, the relevant class within the Business layer.
As you can see each component has a single and clearly defined responsibility. The fact that information (data) may be supplied by another component in order to carry out that responsibility does not mean that this other component shares in that responsibility. The code which transforms data into HTML and sends it to the user exists in its own component. The code which transforms data into SQL queries and sends them to the database exists in its own component. The code which applies business rules to that data exists in its own component. If I have separate components which are responsible for HTML logic, SQL logic and business logic, how can this possibly be an "incorrect separation of logic"?
The problem that some of today's new programmers fail to realise is that by applying the Single Responsibility Principle in an over-zealous manner all you are doing is turning a modular system into a fragmented system which is full of ravioli code. The former has highly cohesive units while the latter has all unity destroyed.
When some people talk about the 'separation of logic' they get confused over what the word 'logic' actually means. To me 'logic' means 'code' where an operation or function is actually performed. It is not the same as 'data' or 'information' which may be held in one component but passed to another when it needs to be processed. As an example consider the following:
Although some information is held with a business object it is not actually processed within that object. It is passed to another object (DAO or view) for processing as only that other object contains the logic (program code) to process that information in the relevant manner. The fact that a business object contains information which is passed to a DAO or view object most certainly does not mean that the business object shares in the responsibilities of those other objects. The different responsibilities are clearly carried out within separate objects, therefore I have (in my humble opinion) achieved a clear separation of responsibilities.
You may also wish to take a look at the following articles:
Some OO zealots say that if a class is built around a database table then surely an instance of that class (an object) should only be allowed to deal with a single instance of that database table (row) at a time. They obviously don't know the difference between a Domain Model and a Table Module:
The primary distinction with Domain Model (116) is that, if you have many orders, a Domain Model (116) will have one order object per order while a Table Module will have one object to handle all orders.
This may be because their use of separate getters and setters for individual fields within that table forces them to deal with one database row at a time. They then require a special procedure to obtain a collection of rows, then another procedure to step through them one at a time.
I do not have this problem as I do not use getters and setters for individual fields. All data goes in and out as an associative array, and as arrays can be multi-dimensional they can contain multiple rows as well as multiple fields. I use a standard getData() method to retrieve data regardless of how many rows may be selected, and a standard foreach() loop to process the result.
It has been suggested that 'real' OO programmers do not build classes which are beyond certain size limits:
Anything which exceeds these arbitrary limits should therefore be broken down into smaller classes.
I disagree. Breaking a class down into smaller units would break encapsulation. Having the information for a business entity contained within a single class makes it much easier to maintain than having that same information spread across multiple classes. I have already separated the application logic into different components as suggested by the 3-tier architecture and the Model-View-Control design pattern, so I consider any further breakdown to be nothing more than an academic exercise with no practical benefit.
Breaking a class down into smaller classes would also have the effect of decreasing cohesion and increasing coupling, which is the exact opposite of what you are supposed to achieve. Instead of a set of cohesive modules you would end up with a series of incoherent fragments.
Instead of using an arbitrary value for 'too big/too many' I recently came across a definition (I forget where) which is less ambiguous:
'Too Many' means that you have more than you need. 'Too Few' means that you have less than you need.
Using this definition I can safely say that:
The idea that the visibility options public, private and protected are a requirement of OOP is just plain wrong. Encapsulation is about placing the data and the operations which act upon that data in a capsule called a class. Implementation hiding is not the aim of encapsulation, it is a by-product of creating the code for each of those operations. Whenever some code is placed within a function or a method it is only the API, the function or method signature, which is visible to the outside world. This signature must include input and output arguments for the data otherwise when you use that API you have no way of putting the data in or getting it out. When you call that API the only thing you "know" is the signature which you are calling and what that signature is supposed to do according to its documentation. That documentation is only supposed to describe those functions which you are allowed to call. You have no idea how each function does what it does, how it is implemented, just a description of what it does. This is not an idea that was introduced in OOP, it has existed since the first function was written in the earliest of languages. The only way to know how a function or method is implemented is to examine the source code behind it, and that is something which is open only to developers, not end users. Extending a class is something that only a developer will do, so it is natural for the developer to know and understand the implementation in that class before he can extend it into a subclass.
The idea that implementation hiding means the same thing as information/data hiding is completely wrong, as discussed in the following articles:
Data hiding is supposed to prevent the illegal or unauthorized access of members of a class, but how is this possible? Who can possibly carry out this unauthorized access - is it a user or a developer? It is a developer's job to write software which can view and modify the contents of the application database, so developers should only have access to the development environment which has dummy data. The production or "live" system should be off-limits to them.
Nobody should be able to access the production system unless they pass through a logon screen, after which they should only be able to access those parts of the system for which they have been granted permission. This is the purpose of a Role Based Access Control (RBAC) system which is built into RADICORE.
One potential problem I have seen many times in other people's code is the common practice of having a separate class property for each column in the table, and having separate load(), validate() and store() methods to complete either an insert or update operation. This means that it is possible to call the load() and validate() methods, but then alter one of the already validated properties to something which is invalid before calling the store() method. Note that this can be done even if you force the use of a setter method.
The way that I solve this problem is to move the load(), validate() and store() methods into a separate wrapper method such as insertRecord() and updateRecord(), each of which use a single $fieldarray variable for both input and output. In this way it is impossible, once the operation has started, for an outsider to insert some malicious data between the validate() and the store().
The terms coupling, cohesion and dependency can be viewed in various different ways, therefore can be interpreted in different ways. All too often I am accused of having the 'wrong' level of one or the other according to someone's personal interpretation. The problem lies in the fact that these variables cannot be measured on any scale - they are simply 'high' or 'low'.
So when is it 'too high' or 'too low'? When is it 'high enough' or 'low enough'?
My measuring stick happens to be the results of the 'right' and 'wrong' levels:
My architecture provides for extremely high levels of reusability, therefore my levels of coupling, cohesion and dependency must be at the right end of the scale.
This series of criticisms came from mjlivelyjr:
By having any SQL fragments in your presentation layer creates a dependency within your presentation on SQL. For example, if the database gods decided one day to radically alter SQL then you would have to make changes to your presentation layer because it has that dependency (or knowledge if you will) of SQL. SQL is obviously something that should be in the Data Access (Infrastructure) layer and if we are talking a 3 tiered application the presentation layer should have absolutely no dependency on your data access layer.
Before you start lecturing me on dependencies I suggest you go back to school and learn what dependency actually means. There can be a dependency between one module and another module, but there cannot be a dependency between a module and a piece of data. There is also no dependency between my presentation layer and my data access layer for the simple reason that the presentation layer does not call the data access layer.
My presentation layer does not execute any SQL queries, it merely passes around SQL fragments as data. These variables, which are entirely optional by the way, are passed through the business layer down to the data access layer where they are assembled into a valid query which is then executed. It is where SQL queries are actually executed which is the critical factor, not where the various components of those queries may originate.
Another significant point that you keep failing to take into consideration is that the DAO is never passed a complete SQL query for execution, it is passed a collection of data (user data and meta-data) which must be assembled into a query before it can be executed. As I have a separate DAO for each database engine (MySQL, PostgreSQL, Oracle and SQL Server) the query can be built according to the requirements of the DBMS in question. Thus any changes can be made within the DAO without having to go back to the source of that data.
Your presentation layer, by using SQL, requires you to have knowledge of how SQL works.
So what? As I am in the business of designing and building web applications I require skills in all the relevant technologies - HTML, CSS, XML, XSL, HTTP, SQL, et cetera. I would find it rather difficult to write software without such knowledge. Even Martin Fowler in his article Domain Logic and SQL says that hiding SQL from developers may not be such a good thing after all:
Many application developers, particularly strong OO developers like myself, tend to treat relational databases as a storage mechanism that is best hidden away. Frameworks exist who tout the advantages of shielding application developers from the complexities of SQL.Yet SQL is much more than a simple data update and retrieval mechanism. SQL's query processing can perform many tasks. By hiding SQL, application developers are excluding a powerful tool.
If he says that mixing SQL and domain logic is not a crime, then who are you to argue?
Yet more criticisms from mjlivelyjr:
I don't know that your view on dependency is entirely accurate. It may not seem like your controller is depending on SQL because it's not using full fledged SQL statements. However, let me ask you this. If you take a controller that is providing SQL fragments, and you decide you want to change the underlying database to a data system that doesn't use SQL will you have to make changes to your controller? If the answer is yes then that means your controller is dependent on SQL. Now you may say "I won't ever change away from SQL." That isn't the point, I am just saying your code is dependent on SQL. I am not even really saying that it's bad to depend on SQL in your controller. I am just saying it's not 3-tiered.
I think it's time for a reality check. Any such "dependency" on SQL is simply theoretical because there are no viable alternatives to SQL databases in the world of enterprise applications. If you don't believe me then answer these questions:
The reason that I do not cater for the possibility of dealing with a non-SQL database is that I do not need to. Refer to You Aren't Gonna Need It for a discussion on the logic of this argument.
This view was supported by aborint:
Sadly, the best argument against his design is that it would make it harder to do things that you would probably never do (e.g. convert you database to a CSV file). Increasing coupling to simplify code is a valid design decision. If you can manage the negative aspects of that decision, more power to you.
This little gem came from Brenden Vickery:
Not being able to switch to another data source is a problem whether that data source is an OO Database, an Relational Db or an XML file. Being able to make that switch is the point of the data source layer and if you know you'll never need to make any changes to how you access your data source then you don't need a data source layer.
Why on earth should I have two data layers, one for data source and another for data access, when both can be provided in a single component? My original Data Access Object communicated with a MySQL database, but when I wanted to use a PostgreSQL database instead I found that all I had to do was take the MySQL class, copy it, keep all the method names but change the code within each method. When I come to instantiate the Data Access Object all I have to do is identify whether to use the MySQL class or the PostgreSQL class. The business layer communicates with whatever object is instantiated using a common interface, so does not have to use different code to talk to a different object. This is a classic example of polymorphism, so should be familiar to every OO programmer. The fact that your implementation would be different does not concern me in the least.
More logic from mjlivelyjr:
The controller class is dependent on SQL. SQL is part of the data storage system. The data system lies in the data access layer. Follow the chain and you see that the controller class is dependent on the data access layer. Follow that one step further and it says your presentation layer is dependent on the data access layer.
I think it is your view on dependency which is not entirely accurate. The following description was provided by dagfinn:
from Martin Fowler, PoEAATogether with the separation, there's also a steady rule about dependencies: The domain and data source should never be dependent on the presentation. That is, there should be no subroutine call from the domain or data source code into the presentation code.
This clearly states that "A is dependent on B" only when there is a subroutine call from A to B. If you agree with this description (and I dare you to disagree with Martin Fowler) then I can state quite categorically that as nothing in my presentation layer makes a direct call into the data access layer (it always goes indirectly through the middle business layer) then there is categorically no dependency between my presentation and data access layers.
If writing software which is dependent on SQL is such a crime then why does Martin Fowler not have anything of significance to say on the matter? His book Patterns of Enterprise Application Architecture contains the following patterns: Table Data Gateway, Row Data Gateway, Data Mapper, Query Object and Record Set which all take for granted the fact that the underlying database can be accessed using SQL queries. If he regards SQL as the standard, then who are you to say otherwise?
This pearl of wisdom came from mjlivelyjr:
You are reading extremely watered down views of n-tier architecture that are most likely being conveyed in a tutorial for people new to the concept. I would wager to guess that the authors themselves would even agree with this assessment.
A similar comment from Brenden Vickery:
Being able to switch to different RDBMS isn't enough to call your layer a data source layer in the 3 tier sense.
I disagree. I suggest you take a look at: Client/Server and the N-Tier Model of Distributed Computing from a company which has been in business since 1982 and which knows a thing or two about the subject. This article clearly identifies the data source as "some sort of SQL server". It also states that database independence is achieved by "using standard SQL which is platform independent. The enterprise is not tied to vendor-specific stored procedures."
This article (and all the other articles I have read on the subject) quite clearly states that by implementing the 3-tier architecture it should be possible to switch from one SQL database to another SQL database simply by switching the component in the data access layer. This I have achieved, therefore my implementation is correct. If this does not conform to your interpretation of the rules I can only suggest that it is your interpretation that needs to be questioned.
This observation came from lastcraft:
You have a client/server app., not a three tier one.
This was followed by this comment:
3 tier is not about dividing up code. You could do that just by placing different source files into different folders on your hard drive and claim it was "3 tier". 3 tier is about severely restricting visibility across those boundaries. If you fail to do that then you don't have a 3 tier architecture. There is no room for opinion here, you simply don't understand the definition if you've not done this.
I think that it is your definition of '3 tier' that needs to be re-examined, not mine. Perhaps if you look hard enough you can find one that is not printed on toilet paper. A 3 Tier Architecture is one which has the following component layers:
Communication between these layers is limited to the following:
In other words the requests must always be in the direction front-to-middle-to-back while the responses must always be back-to-middle-to-front.
That is precisely what my framework achieves, so it most definitely is 3 tier. Any definition of 3 tier which excludes these basic principles - such as your "severely restricting visibility across those boundaries" - is completely nonsensical and unworthy of consideration by any competent person.
This wonderful piece of wisdom came from lastcraft:
The column names, and with it the schema, are bleeding upwards and destroying the layering.
What the f*** does 'bleeding upwards' mean? Where is this documented? This explanation was offered by Dr Livingston:
The concept of 'bleeding upwards' is not really a concept but a term to refer to one layer knowing about the layer above it.Any given layer (regardless of it's disposition or task) should only ever know of the layer(s) below it, and not never know what's above it
You do not understand what one layer knowing about another layer actually means. The presentation layer knows about the business layer because it is capable of calling a method (issuing a request) on an object in the business layer. The business layer does not know about the presentation layer for the simple reason that the business layer never issues a request to any object in the presentation layer. The object in the business layer returns a response to a request, but it never issues a request on the presentation layer.
This comment came from mjlivelyjr:
The reason why your example breaks layering is because it references the column name as a column name.
A similar one came from Brenden Vickery:
Your Presentation is tied to your database through column names, and form names. You couldn't change your database without changing your presentation. You cant change your presentation without changing your database. I find the way you have done this to be extremely difficult to use.
So according to your interpretation of the rules it is wrong to refer to data items by the same name in each of the software layers? What absolute rubbish! In all the 25+ years that I have been programming I have never encountered a system which used different data names in different parts of the system. It is illogical, counter-intuitive, and would require additional modules to translate the data names between one component and another. Imagine how much more difficult debugging would be if a data item changed its name each time it passed between modules! What I am doing is standard practice. What you are suggesting is nothing short of perverse.
Yet another one from Version0-00e:
Presentation layer shouldn't need to know of what fields to use from the database. Looking last night on Tony's site, I seen in XML he passes over the database field names (for whatever reason).This isn't real separation of concerns surely? An XSL stylesheet doesn't need to know this, all that it's interested in is getting the data from the XML and parsing it dependent on a given template, nothing more.
You are missing the point - as usual. Those data names are simply the data names which exist within the XML document. There is no reference as to where each item of data came from - it may or may have come from a database, it may have been plucked out of thin air, it may or may not have come from a data source with the same name. The only thing that matters is that the data exists within the XML document - where it came from is totally irrelevant.
Your comment that "this isn't real separation of concerns" indicates to me that you haven't a clue as to what "separation of concerns" really means. In the 3 Tier Architecture each component layer has a distinct set of responsibilities/concerns:
Note that logic means code, not data, so the fact that an item of data (which may even be meta-data) can flow through all 3 layers, and be referenced with the same name in each layer, does NOT violate the "separation of concerns" principle. If I were to access the database from within the presentation layer, or execute business rules within the data access layer, then that would be a violation, but sharing common data names across layers most definitely would not.
This little gem came from Brenden Vickery:
The problems here are that, the fact you are using a relational database is known, your database schema is known, ...
So what? Where does it say that it is wrong for an object to have knowledge of the underlying database schema? All the programming languages I have used in the past 25+ years have actually made it impossible for the code to be built around anything other than the physical database schema:
Any programmer who is experienced in writing database applications will tell you that all user input MUST be validated before it is written to the database. This validation is performed in the Business/Domain layer before the data is passed to the database layer. This means that the domain layer MUST have knowledge of all the columns in the database table with which it is communicating. As well as the column names it must know the datatype of each column so that it can verify that the value supplied for a column matches the specifications of that column. To do it any other way is inviting disaster.
So where does it say in any OOP manual that a business object must not be constructed around a data schema which is the same as the physical database schema? Just because someone has invented some object-relational metadata mapping patterns (refer to Metadata Mapping, Query Object and Repository) which deal with the situation when they are different does not mean that they must be different. It is impossible to write software which does not, somewhere in its bowels, have knowledge of the physical database schema. As a pragmatic programmer it seems utterly stupid to introduce an additional arbitrary structure which then requires an additional mapping layer to convert from one structure to the other. By making the object schema the same as the physical schema I avoid this extra layer of complexity. As a follower of the KISS principle and not the KICK principle I seek to avoid unnecessary complexity whenever and wherever possible, so this not-so-bright idea is a prime candidate for the rubbish bin.
Where does it say that when your software communicates with a relational database that it must not know that it is communicating with a relational database? Knowledge is data, not code. Knowledge is information, not logic. While my presentation and business layers may have variables which can be traced back to an SQL database, it is only within my data access layer that you will find logic (program code) which performs the actual communication with the database.
Decades ago when relational databases were first being introduced the number of people who knew SQL was pretty small, so it was common for software development to have two teams - one writing program code and another writing SQL. Those days are long gone, and nowadays it is expected that anyone who writes software which uses a relational database is capable of writing SQL queries, just as a programmer who writes software for the web is capable of writing HTML.
In a recent blog post someone made the following observation:
If you have one class per database table you are relegating each class to being no more than a simple transport mechanism for moving data between the database and the user interface. It is supposed to be more complicated than that.
What this person has failed to understand, probably due to a lack of experience, is that when writing a database application you are writing software which interacts with objects in a database, not objects in the "real world", and those objects are called "tables". The only operations which can be performed on a database table are Create, Read, Update and Delete (CRUD). Different combinations of these operations are performed on different combinations of tables by performing a collection of user transactions. The basic functionality of every user transaction always follows the same basic pattern - it performs one or more CRUD operations on one or more tables. It starts out as being nothing more than a "simple transport mechanism" as it entails the moving of data between the user interface, through the Business layer, to a Database layer and back again. It is the Business layer which is the heart of the application as this is where all the business rules are processed. In the RADICORE framework all standard functionality, up to and including all primary validation, is provided by components which are built into the framework. Any complex business rules can be added in later by the developer by inserting the relevant code into any of the numerous "hook" methods within any table subclass. In other words the framework provides all the simple processing while it is the developer's responsibility to add in any complexities.
In 2004 I came across this post which identified a study that broke down an application's code into several basic categories - business logic, glue code, user interface code and database code - and highlighted the fact that it is only business logic which has any real value to the company. It compared the productivity of two different teams and found that the team which spends less time writing glue code, user interface code and database code can spend more time writing the "value" code and therefore be more productive. Time spent on writing anything other than the "value" code has a negative effect on a team's productivity. In the RADICORE framework all the interface code, the database code and the glue code is automatically provided, so all the developer has to do is insert "value" code into "hook" methods in the individual table classes.
Some developers still employ a technique which involves starting with the business rules and then plugging in the boilerplate code. My technique is the reverse - the framework provides the boilerplate code in an abstract table class after which the developer plugs in the business rules in the relevant "hook" methods within each concrete table class. Additional boilerplate code for each user transaction is provided by the framework in the form of reusable page controllers.
I have been building database applications for several decades in several different languages, and in that time I have built thousands of programs. Every one of these, regardless of which business domain they are in, follows the same pattern in that they perform one or more CRUD operations on one or more database tables aided by a screen (which nowadays is HTML) on the client device. This part of the program's functionality, the moving of data between the client device and the database, is so similar that it can be provided using boilerplate code which can, in turn, be provided by the framework. Every complicated program starts off by being a simple program which can be expanded by adding business rules which cannot be covered by the framework. The standard code is provided by a series of Template Methods which are defined within an abstract table class. This then allows any business rules to be included in any table subclass simply by adding the necessary code into any of the predefined hook methods. The standard, basic functionality is provided by the framework while the complicated business rules are added by the programmer.
I am an old-timer at this game, and my experience tells me that the simplest approach is always the best approach. Before the name was changed to Information Technology (IT) this profession used to be known as Data Processing, and what we developed were called Data Processing Systems. The definition of a "system" is "something which transforms input into output", as shown in Figure 13:
Figure 13 - a system
")
Software is a system as data goes in, is processed, and data comes out. Sometimes the "processing" part of the system is nothing more than saving the data in a high-speed high-capacity storage mechanism (a database) so that it can be be quickly retrieved and displayed to the user in more or less the same format that it went in. In other cases the data may be transformed or manipulated in some way before it is stored, and/or transformed or manipulated in some way before it is output. This would give rise to the situation shown in Figure 14:
Figure 14 - a data processing system
")
Every database application I have ever worked on, in whatever programming language my employer used at the time, has always started off as nothing more than a "simple data transport mechanism" between the user interface and the database. In order to become a usable application the programmer then has to insert code to process all the business rules, either at the input stage or the output stage, and it is this coding of the business rules which adds complexity. In an ideal world a programmer should have to spend as little time as possible on the simple stuff so that he has more time to spend on the complex stuff. I have built three frameworks in three different languages which were aimed at delivering the "simple stuff" as quickly as possible, thereby giving the programmer more time for the "complex stuff". My employer in 1986 liked my framework so much he made it the company standard. My fellow developers liked it because they did not have to spend as much time coding the boring bits. Our customers liked it as we could build applications quicker and therefore cheaper than our rivals.
I have always built my database first, then structure my software to match the database structure. Using an OO language where I can have a separate class for each database table and where the common code can be inherited from an abstract class has given me a framework which is far more productive than any of its predecessors. Because I generate my classes from my database tables I don't have to waste my time with OOD, and because my class structure is always in sync with my database structure I don't have to waste my time with an ORM. My framework takes care of a huge amount of the simple stuff, thus leaving me more time for the complex stuff. I'm not going to throw all that away just because you say it is too simple. My approach is not too simple, it is your approach which is too complicated.
The aim of the RADICORE framework is to build the "simple data transport mechanism" for each database table as quickly as possible. All the developer has to do for each user transaction is to code the processing rules, either at the input or output stages. This task is made easy by virtue of the fact that each table class contains empty methods at both stages, so it is a simple matter of deciding which code to put into which method. If your framework does not make it as simple as that then I would suggest that it is your framework which is too complicated and is in serious need of refactoring.
My approach to OOP causes some consternation among OO zealots who constantly claim that my approach is impure, unclean and should be banned in case it corrupts the minds of those with less experience. According to some I should even be banned from contributing to popular forums altogether or even hung from the nearest tree. What is it that causes such animosity and hatred? What have I done to offend these people? It cannot be that my methods do not work, because I can clearly demonstrate that they do. It can only be that I have broken the rules which they consider to be sacred, and such sacrilege must not be allowed to go unpunished. They are like religious zealots who start foaming at the mouth if anyone dares to question their beliefs.
Their attitude seems to be:
Your methods are wrong because you have broken the rules.
Whereas as my attitude is quite simple:
My methods cannot be wrong for the simple reason that they actually work. Something that works cannot be wrong just as something that does not work cannot be right.
I have not broken the rules as there is no such thing as a single set of rules that everybody must follow. I have simply broken your interpretation of the rules. As there appears to be many different interpretations of many different rules floating around the ether, who is to say which interpretation is right and which interpretation is wrong?
If these rules are open to so much interpretation (and mis-interpretation) then is it not the author's fault for creating rules which are so vague? Or is it because these rules are supposed to be no more than an outline of the major objectives, with the fine details left entirely up to the individual programmer within his particular implementation?
The purpose of the software developer is to develop software which works, not to develop software according to an arbitrary set of rules. It is results that count, not rules. I achieve better results without your rules, therefore I see no reason to be restricted by them.
Like any religion which is gradually corrupted over a period of time the principles of object oriented programming have been gradually corrupted in exactly the same way. The original principles behind OOP were described simply as encapsulation, inheritance and polymorphism, but with the passing years different interpretations have been proposed, and these re-interpretations have in their turn been subject to even more re-interpretation. The end result is a hodge-podge of misinterpretation, misrepresentation and misunderstanding, and is so far removed from the original concepts that it is a wonder that they can be used to produce anything workable at all.
One of the most common criticisms I receive about my approach to OOP is that is is "too simplistic". I have news for you guys - that's what the KISS principle is all about! It seems that some people deliberately avoid the simplest approach in order to make themselves look more clever than they really are. They seem to think that unless a solution is complicated, convoluted and obfuscated it cannot be much of a solution. As for me, there is the simple solution, or there is the stupid solution. If the simple solution works, is easy to implement and easy to maintain, then anything else is just plain stupid.
Here are some examples of the basic misunderstandings which cause confusion among the OO zealots:
The idea of data hiding has always seemed strange to me. Surely in an application whose sole purpose is to move data between a GUI and a database then hiding that data defeats that purpose?
This is the method by which it is possible to take a simple sentence and, with a small change, completely reverse the logic. Take, for example, this common piece of pseudo-code:
if <condition> then <imperative statement>
Now, everybody knows that what this means is:
Yet why do some OO zealots seem to translate this as:
"Hang on," I hear you say, "Nobody can be that stupid!" Yet bear with me for a moment and follow this train of thought:
Does this sound familiar to anyone? This must be why I am told the following:
This principle may be familiar to others under the name Contraposition.
While surfing the web I occasionally come across articles containing statements with which I heartily disagree. I would like to share some of these with you.
In the article Why extends is evil the author makes the following statement:
The first problem is that explicit use of concrete class names locks you into specific implementations, making down-the-line changes unnecessarily difficult.
I have used concrete class names in my framework for many years and have never had any difficulty making down-the-line changes. In fact I have less difficulty now than I did previously with non-OO languages. Perhaps it is the way that I use inheritance which is more superior than yours?
Later on he states the following:
In an implementation-inheritance system that uses extends, the derived classes are very tightly coupled to the base classes, and this close connection is undesirable.
Undesirable? In what way? In my framework every concrete table class is derived from an abstract table class. The abstract class is quite huge while the concrete classes (and I have hundreds, by the way) are quite small. They are small because 100% of the boilerplate code is inherited from the abstract class. This is the way that OO programmers share code, how they make code reusable. If you are not getting the same results then you must be mis-using inheritance.
One of the people who commented on this article made the following statement:
OOP is not well suited to use in a Database application.
This statement shows the author's lack of understanding on two levels:
I do not suffer from any such lack of understanding. I was involved in writing database applications for 20 years in several different non-OO languages before I switched to PHP with its OO capabilities, and since I made that switch I have found it infinitely easier. Perhaps it is the artificial rules that you follow which make it difficult? I don't follow those rules, therefore I don't experience any difficulty.
If the OO zealots can get confused with relatively simple concepts, is it any wonder they lose the plot completely when things get more complicated? They are so tied up in their fancy rules that they have completely forgotten the purpose behind OOP in the first place - to be able to create software quicker and with fewer bugs. I have managed to achieve this, but in order to do so I have found it necessary to draw on my past 25+ years of experience and reject the ridiculous rules of the OO zealots. If I can produce workable (and some would even say superior) results by breaking their rules, then what does it say about the quality of their rules? I do not appear to be alone with this opinion - take a look at the following:
So before you tell me again that I'm breaking one of your precious rules just answer these simple questions:
All the while you OO zealots keep inventing these ridiculous rules I shall exercise my God-given right to break them. That is, after all, the only way I can create software which is acceptable to both myself and my customers.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles: