Figure 1 - A typical Family of Forms
")
I have been building database applications for businesses since the early 1980s, first in COBOL, then in UNIFACE in the 1990s and since 2002 in PHP. In that time I have used a variety of Hierarchical, Network and Relational databases. I spent the majority of the first 20 years working for software houses where we designed and built bespoke systems for different clients, but in 2007, after using my newly rebuilt RADICORE framework to build a bespoke application for another software house, I was asked to build a similar application as a package that could be used by multiple clients. While a package can be more expensive and complicated to build, by being able to sell copies to multiple clients each client only pays a fraction of the cost (which is good for them) but the more copies we can sell then the more profit we can make (which is good for us). I built the prototype in six months and it went live with the first client six months after that. This is documented in Building a customisable ERP package.
With all these applications, which covered a wide variety of business areas such as sales, purchases, inventory, shipments and invoicing, one thing was constant - we always designed the database before writing the first line of code. We could implement that design in the client's choice of DBMS, and then write the code in the language of our choice. One point of our designs was that, should the client be unhappy with our cost and timescale estimates, he was free to take our design and have it implemented by another company. It would only be after the client had awarded us the development contract that we would convert that logical design into a physical design and then begin the implementation.
After successfully managing the migration from various non-OO languages to one that had OO capabilities I began to receive criticism from a number of OO purists that my work was wrong simply because I was not following the same set of "best practices" as they were, not following the same set of "rules of OOP" as they were, and not implementing OOP in the "right way". My "crime" was that I built my database first, then created a separate concrete class for each table which inherited from a single abstract table class. This produced comments such as the following:
This is not how proper OO programmers are supposed to do it. Designing your software around the database is just plain wrong. Don't you know that you should leave the database till last as it is nothing more than an implementation detail?
I thought this statement was wrong then, and I still think it is wrong today, which is why I ignore it completely. I firmly believe that I am achieving the aims of OOP by producing high levels of reusable code, and I also believe that by following this bad idea my levels of productivity would disappear down the toilet. To me that proposition is completely unacceptable.
This bad idea has encouraged legions of OO programmers, when developing database applications, to ignore the database design until after they have designed the software in the form of interfaces, class hierarchies, aggregations, compositions, associations, polymorphism, design patterns, dependency injection containers and whatever else is the latest fad or fashion. They build their code using mock database objects and don't bother with a physical database until as late as possible. If they then employ a professional to design a properly normalised database this is where they hit that problem known as Object-Relational Impedence Mismatch where there is no direct one-to-one mapping between objects in their software and objects in the database. For them this problem can only be solved with the introduction of an intermediate piece of software known as an Object-Relational Mapper (ORM). To me this is an overly-complex solution for a simple situation, and as it violates the KISS Principle I refuse to entertain it. I prefer solutions which are simple and logical, and this "solution" fails on both counts.
I have often wondered about the origin of this questionable notion, and I think I have found it.
In Robert C. Martin's blog post called NO DB the final two paragraph contain the following statements:
If you get the database involved early, then it will warp your design. It'll fight to gain control of the center, and once there it will hold onto the center like a scruffy terrier. You have to work hard to keep the database out of the center of your systems. You have to continuously say "No" to the temptation to get the database working early.
We are heading into an interesting time. A time when the prohibition against different data storage mechanisms has been lifted, and we are free to experiment with many novel new approaches. But as we play with our CouchDBs and our Mongos and BigTables, remember this: The database is just a detail that you don't need to figure out right away.
His rant about relational databases began in the 1980s. He had been used to writing software which used flat files, and he could not see the need to change to using a big and expensive relational database.
Our data model was relatively simple, and we kept the data in flat files. It worked fine.
my view of a relational database was that it would be a big, stodgy, slow, expensive pain in the rear. We didn't have complex queries. We didn't need massive reporting capabilities. We certainly didn't need a process with a multi-megabyte footprint sitting in memory and burning cycles.
While I agree that it is foolish to utilise new technology just because it is shiny and new, especially in an environment that cannot take advantage of all the new and expensive features, the situation has changed somewhat in the 28 years which has elapsed since 1984 and the date on which this article was written. I think this aversion to relational databases just because they are "new" has gone past its sell-by date.
I watched the relational database market grow during the '90s. I watched as all other data storage technologies, like the object databases, and the B-tree databases dwindled and died; like the beer companies in the 20s. By the end of the '90s, only the giants were left.
During this time I watched in horror as team after team put the database at the center of their system. They had been convinced by the endless marketing hype that the data model was the most important aspect of the architecture, and that the database was the heart and soul of the design.
I have been designing and building enterprise applications since the early 1980s, and every one of these applications has required a database in order to store details of the daily activities as well as provide a wide range of management reports. I have used my fair share of flat files, hierarchical and network databases, but none has provided the power and flexibility of a relational database with its SQL interface. While other types of software may find some advantage with using a NoSQL database, I have yet to hear of any ERP application being deployed on anything other than a relational database. We are now in the 2020's, and when I am asked to build a new application, whether it be a bespoke application or a new subsystem to my ERP package, there are two things I know for certain - the front end will be centered around HTML forms and the back end will be centered around an SQL database. Everything else is just an implementation detail.
I watched as SQL slipped through every crack and crevice in the system. I ran screaming from systems in which SQL had leaked into the UI. I railed endlessly against the practice of moving all business rules into stored procedures. I quailed and quaked and ranted and raved as I read through entire mail-merge programs written in SQL.
Any modern programmer who tries to build an enterprise application without following Uncle Bob's Single Responsibility Principle (SRP), which is also known as the 3-Tier Architecture, will be facing an uphill battle and making life more difficult than it need be. Putting SQL into the GUI is a no-no. For me putting business rules into stored procedures is also a no-no. Business rules belong in just one place, the Business layer. My applications can be deployed on a variety of DBMS engines, so I maintain all business rules just once in the software and not in different sets of stored procedures for different DBMS engines.
And then, in the first decade of the 21st century, the prohibition was lifted, and the NOSQL movement was born. I considered it a kind of miracle, a light shining forth in the wilderness. Finally, someone realized that there might just be some systems in the world that did not require a big, fat, horky, slow, expensive, bodily effluent, memory hog of a relational database!
I watched in glee as I saw BigTable, Mongo, CouchDB, and all the other cute little data storage systems begin to spring up; like little micro-breweries in the '80s. The beer was back! And it was starting to taste good.
But then I noticed something. Some of the systems using these nice, simple, tasty, non-relational databases were being designed around those databases. The database, wrapped in shiny new frameworks, was still sitting at the center of the design! That poisonous old relational marketing hype was still echoing through the minds of the designers. They were still making the fatal mistake.
Finally we get to the crux of the matter:
The name of this article is "No DB". Perhaps after that rant you are getting an inkling of why I named it that.
The center of your application is not the database. Nor is it one or more of the frameworks you may be using. The center of your application are the use cases of your application.
This is where I believe his message gets fuzzy. When he states such this as The database is just a detail that you don't need to figure out right away
and The center of your application are the use cases, not the database
by "database" which of the following does he mean:
The first point is a no-brainer to me. Anyone in the 21st century who builds an enterprise application WITHOUT the use of a relational database would be, in my humble opinion, taking a big risk. They are now mature and proven, and as the price of hardware comes down and the speed goes up their use is almost transparent and a foregone conclusion. The question today would not be Why are you using a relational database?
but instead would be Why are you NOT using a relational database?
The second point above should be the one to consider today. Which takes priority, the database design or the software design? When Uncle Bob makes the statement the database is just a detail that you don't need to figure out right away
he is telling every developer that they should design their software first according to the rules of OOD, DDD, SOLID, OOP or whatever acronym is today's fashion, and leave the database design till last. Because the rules of database design and software design follow different paths they produce incompatible results which causes that problem known as Object-Relational Impedence Mismatch which can only be "cured" with that abomination known as an Object-Relational Mapper (ORM).
Asking the developer to choose between the uses cases and the database is asking the wrong question as they both appear in the project lifecycle at different points and provide totally different information:
When you look at it this way then surely it is obvious that it is the software which is the implementation detail.
In all these years of developing database applications the basic approach has always been the same:
Note that the first 3 steps - gather, analyse, discuss - would often be an iterative process as imprecise requirements would be made more precise, or missing requirements could magically appear. This could result in the draft database design and/or use cases being amended.
Note also that the logical design ALWAYS comes before the physical design. It is at the physical design stage that the actual DBMS and programming language are chosen. It is these which are the implementation details, not the database design.
The systems that we built were originally known a Data Processing (DP) systems, and organisations began to have their own DP Departments with their own DP Manager. This processing of data, regardless of what the data actually consisted of, always followed the same pattern - put data into the database, then get data out of the database. There ere electronic forms at the front end, a database at the back end, and software in the middle to handle the business rules and task-specific behaviour. The database was required so that the data could be stored electronically over a long period of time. It was quicker to retrieve data from an electronic database than it was from paper documents stored in a room full of filing cabinets.
It became obvious to us application developers that the heart of our application was always the database. It needed to be properly designed so that the data could be both input and then output as efficiently as possible as no organisation could survive with a system which took longer to record and report its business activities than it took to perform those activities. This is where the art of Data Normalisation became standard practice. Get it right and the system will run like a greyhound. Get it wrong and the system will run like a pig with a wooden leg.
Another important point which seems to be ignored by the majority of today's OO programmers is that when you are writing software for a particular problem domain then you must have a deep understanding of that domain before you can design a software solution for that domain. If you are writing software to control elevators in a tall building then you must know how elevators work. If you are writing avionics software for aircraft then you must know how aircraft work. Similarly if you are writing a database application then you must know how databases work so that you can work with the database instead of against it. It would not be a good idea to say I'll ignore the database as the ORM will deal with all that SQL nonsense
. Similarly if you are building a web application then you will need to know how the HTTP protocol works and how to construct HTML documents.
Use cases (user transactions or tasks) are vitally important as in stage 1 of the Project Lifecycle they identify the requirements of the application, or what needs to be done. Those requirements are not said to be satisfied until every use case has been implemented.
One thing I noticed in my pre-OO experience of developing database applications is that each task, no matter how complicated, always performs one or more operations on one or more database tables. That identifies the starting functionality, and the complicated processing can be added later on top of this foundation.
Every use case will consist of a Model, View (usually) and Controller, and will use a DAO to communicate with the database. Some do not have a View as they perform their function, such as updating the database or creating a disk file, without the need to display the results. When building the scripts for each use case I made the following decisions:
In order to carry out the different operations which are required to maintain the contents of a database table I create a family of forms as shown in Figure 1:
Figure 1 - A typical Family of Forms
Each of the boxes in the above diagram is a clickable link. Please note the following:
As the details for each use case (user transaction) are sketched out it is vitally important that the data requirements are added to the draft database design. You must ensure that every piece of data required for output can actually be pulled out of the database. The data must be properly normalised so that it can be both input and output as efficiently as possible.
Having analysed the use cases to identify the database requirements and the business rules you must then implement those requirements in your software so that working copies of those use cases can be delivered to the client. This is where the programmer's skills are put to the test. He must use Encapsulation, Inheritance and Polymorphism to create as much reusable code as possible.
As "programming with objects" requires the use of objects you must first define the classes which can be instantiated into objects. In order to create classes you must answer the following questions:
The biggest questions for someone who is new to OOP is What classes do I create for my application? What methods do I put in those classes?
One thing you NEVER do is create a single class called "application" with a single method called "run". What you are supposed to do is create a separate class for each entity that will be of interest to your application. However, what you are not supposed to do is overload each class with multiple responsibilities. Anybody building a database application would be well advised to follow Uncle Bob's Single Responsibility Principle (SRP) by implementing the 3-Tier Architecture with its Presentation layer, Business/Domain layer and Data Access layers. Anybody building a web application would be well advised to use a template engine to build HTML documents from reusable templates instead of writing each one from scratch. The use of a template engine has the effect of splitting the Presentation layer into two which effectively makes it an implementation of the Model-View-Controller design pattern, as shown in Figure 2:
Figure 2 - 3-Tier Architecture and Model-View-Controller combined
")
Each of these component types has the following responsibilities:
In theory with this degree of separation you should be able to change the implementation within one of these components without having to make corresponding changes to any of the others, but that will depend on how well you achieve high cohesion and loose coupling.
The next big question for the novice developer is Do I create a Model class for each entity in the real world, or each entity in the database?
This is where I had the advantage of NOT being taught all those wild OO theories and had nothing to go on except 20 years of experience, a pragmatic and logical attitude, lots of common sense and intuition. To me the answer was blindingly obvious:
When writing a database application you are not writing software which communicates with objects in the real world, you are writing software which communicates with objects in a database, and those objects are called tables. You are not manipulating real objects, you are manipulating information about those objects.
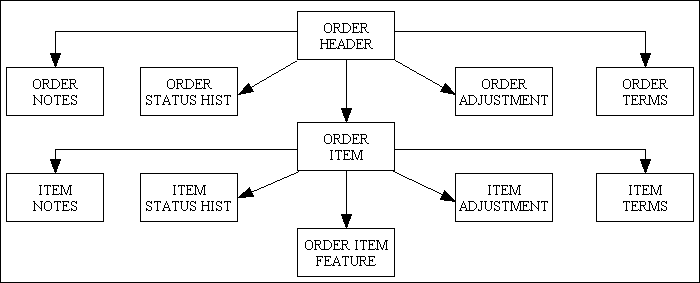
Some programmers take the idea of modelling the real world too literally when identifying entities which should be represented as classes. This becomes problematic when an entity has so much data that after the process of Data Normalisation it actually needs to be spread across multiple tables. An Order, for example, may be considered by some to be a single entity in the real world which therefore requires a single class in their software, but when represented in the database it requires the collection of tables as shown in Figure 3:
Because an ORDER-HEADER has multiple HAS-A relationships with other tables this then leads to object composition or object aggregation which results in a compound object which acts as the container for the entire group of tables. The novice developer then assumes that none of these tables can be accessed without going through the container class
I do not have any objects which act as containers for other objects for the simple reason that in a relational database you cannot define tables which act as containers for other tables. That is not how databases work, so you should not force this behaviour into your software. This is why I create a separate class for each database table, and if that table has any relationships with other tables then this is stored as metadata in either the $parent_relations or $child_relations arrays. After following this convention for the past 20 years I have found that having a one-to-one relationship between my software classes and my database tables has given me more opportunities for reusable code and avoids the problems I have seen when others try to do it differently:
The composition of objects shown in Figure 3 does not, in my universe, constitute a single entity which requires to be accessed through a single Model class with a single Controller. In this group there are 11 tables which are linked via 10 relationships. None of the child entries in any relationship can exist without a parent. Each of these tables will require its own family of forms as shown in Figure 1 which will result in a total of 66 separate tasks using various patterns as follows:
I was not taught that each use case (user transaction) should have its own method, so I followed a simple fact that I had observed in the previous 20 years of working with databases:
The only operations that can be performed on a database table are Create, Read, Update and Delete (CRUD)
This is why I have the same insertRecord(), getData(), updateRecord() and deleteRecord() methods duplicated in every table class. The alternative of having unique method names within each class where the entity name and operation are combined strikes me as being the worst idea possible. For example, suppose you have three tables such as Customer, Product and Invoice you would end up with method names such as the following:
You should notice here that each additional table would require its own set of method names. When you have hundreds of tables that would require of lot of different names. The alternative is much simpler:
insertRecord() method on the Customer, Product or Invoice object.getData() method on the Customer, Product or Invoice object.updateRecord() method on the Customer, Product or Invoice object.deleteRecord() method on the Customer, Product or Invoice object.Even though I was a novice at OOP I could see straight away that, unlike with procedural programming where each function name has to be unique, with OOP the same method name can be duplicated across any number of classes. This is how you provide Polymorphism which then opens the door to being able to produce and utilise more reusable code, such as via Dependency Injection. Because all these table classes are sharing the same method names any code which is being duplicated in each class can be moved to an abstract table class so that it can be shared by inheritance. The use of an abstract class then opens the door to using the Template Method Pattern which provides inversion of control which is what turns a library into a framework. Each concrete table class then contains nothing but "hook" methods to handle all the table-specific behaviour.
This use of an abstract class supports the style of programming known as programming-by-difference which was described by Ralph E. Johnson & Brian Foote in their 1988 paper Designing Reusable Classes. This is where you examine a group of classes looking for similarities as well as differences with the aim of trying to share the similarities. Functional Abstraction results in shared methods which are best stored in an abstract class while Data Abstraction results in shared properties which can be defined in the same abstract class with different values supplied in each concrete class. While there are structural differences between one table and another these differences can be stored in each class as metadata. This metadata can be obtained from the database's INFORMATION SCHEMA, stored in an intermediate table structure file, and then loaded into the table class when it is instantiated. For more precise details I direct you to the following:
While investigating how to use PHP to write database applications I made use of some online resources as well as buying some books. I saw in the sample code where everybody was defining each column in the database table as a separate property/attribute, and they encouraged the use of individual getter and setter methods for each property instead of accessing the property directly. I had also noticed that when an HTML form was submitted all the data was presented to the PHP script in the form of a single associative array called $_POST. I also noticed that when reading data from the database the SELECT query also returned the data for each row as an associative array. The more I read about PHP arrays the more I realised that they were much more powerful and flexible than what existed in my two previous languages. This prompted me to ask myself the following question:
If the data coming into an object from both the Presentation layer and Data Access layer initially starts off as an array, would it be easier to pass that data around in an array instead of deconstructing it into its component parts and dealing with each component separately?
The more I thought about this the more I realised that having a separate property for each column actually was actually a worse idea than using an array. The issues that came to mind were as follows:
Because of all these problems I decided that it would much better to pass the data around on every method call in a single array argument, which internally is known as $fieldarray, instead of having a separate argument for each column. In this way I could alter the contents of the array at any time without having to alter any method signatures.
<?php require_once 'classes/$table_id.class.inc'; // $table_id is provided by the previous script $dbobject = new $table_id; $fieldarray = $dbobject->insertRecord($_POST); if ($dbobject->errors) { // do error handling } ?>
This has the following differences when compared with the tight coupling example:
$table_id.When you couple the fact that every Model implements the same methods with having a single array argument for all table data this means that the code sample above, which exists in a Page Controller, can be used to insert data into any table in the database. Not just a particular table but any table you care to mention. Every one of my Controllers performs one or more operations on one or more tables, but the table names are NEVER hard-coded. This means that any Controller can be reused with any Model.
Because I have found nothing but advantages with this approach I am surprised that nobody else encourages it.
When you are documenting a principle or "best practice" for other people to follow it is extremely important that it is phrased correctly otherwise it can have unintended consequences. When it is aimed as novice programmers with the intent of helping them become proficient or even expert programmers then the choice of words is vital. If you use a word that has several different meanings then you must clearly identify which of those meanings is relevant otherwise the novice may pick the wrong meaning and travel down the wrong path. If what you write is ambiguous or open to interpretation then it is also open to misinterpretation, then Murphy's Law will come into play and the reader will choose the wrong interpretation.
When Uncle Bob's article includes such phrases as The center of your application is not the database, it is the use cases
and The database is just a detail that you don't need to figure out right away
this has been interpreted by hordes of clueless newbies to mean that the design of their software, which includes following the rules of OO Analysis and Design, Data Driven Design, Object Oriented Programming, Design Patterns, SOLID principles, et cetera, is more important than the design of the database and can therefore be left till last as it is nothing more then an implementation detail.
This to me is sending out the wrong message, pointing people in the wrong direction and leading them up the garden path. The question is NOT Which is more important - the use cases or the database?
as they are BOTH important but for different reasons. As I have shown in Typical project lifecycle these two items appear in different stages:
Note here that the database design is part of the logical design which is always completed before the first line of code is ever written, and sometimes before the programming language or DBMS engine are chosen. The logical design should also include a description of all the use cases that will be required to both put data in and get data out of the database. It is during this phase that the data required by each use case should be verified to exist in the database. Only when the two are matched should the project move from the design phase to the implementation phase, the first step of which is to build the database so that it is available before the first line of code is written. This clearly shows that it is the writing of the code which is the implementation detail, not the database design. The idea that when using an object oriented language you should follow the rules of Object Oriented Analysis and Design (OOAD) in order to influence the logical design is also wrong. The database is always designed before any code is written, and that code should be written to work with that database design, not against it. Eric S. Raymond, the author of The Cathedral and the Bazaar put it like this:
Smart data structures and dumb code works a lot better than the other way around.
This is the method which I successfully used in the 20 years before switching to an OO-capable language, and it it what I have continued to use in the 20 years since making the switch. Not only has it NOT caused any problems, it has enabled me to create larger volumes of reusable code than I have ever seen in any other implementation. As producing larger amounts of reusable code is supposed to be the objective of OOP then I would say that my method has been more successful than all the others.
As proof that my database-comes-first-code-comes-second approach actually works let me take you back to 2007 when I was asked to design and build an ERP application which could be sold as a package to multiple clients instead of building a bespoke application for individual clients. Having read a copy of Len Silverston's Data Model Resource Book I decided that these data models would be a good foundation for my application, so I built the databases for each of the following business areas:
As well as having its own database each of the above was implemented as a separate subsystem within RADICORE so that its files are maintained in a separate subdirectory. It was then a simple process to import the database structures into my Data Dictionary, create the class files, then build the individual tasks for each table. All I had to do was then modify the class files to add code into the various "hook" methods to handle the business rules for each task. The first prototype was ready for client testing after just six months, which meant that it took an average of just one man-month to build the code for each of those subsystems. Can any other framework compete with that? Could it have been done my building the code first and leaving the database till last? I think not.
Since that time I have added more and more of Len Silverston's data models to my ERP application and developed the code for each one at the same rapid pace. This is because in my world the database is king, and it is the software which has to mold itself around the database structure, not the other way round. I have also built a framework containing a large number of pre-built and reusable components which provide all the common boilerplate code, which means that I have little to do except add custom code to the various "hook" methods within each table's class.
As far as I am concerned it is not the database which is the implementation detail. The application design produces screen structures, report structures and database structures, it is the code which operates on these structures which is the implementation detail.
Here endeth the lesson. Don't applaud, just throw money.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles: