Figure 1 - One-to-Many relationship using arrowhead notation
It was not until many years after completing my framework that I was informed that I was not following "best practices" when it came to the use of object associations. When I searched for this term on the internet I found the following:
In object-oriented programming, association defines a relationship between classes of objects that allows one object instance to cause another to perform an action on its behalf. This relationship is structural, because it specifies that objects of one kind are connected to objects of another and does not represent behaviour.In generic terms, the causation is usually called "sending a message", "invoking a method" or "calling a member function" to the controlled object. Concrete implementation usually requires the requesting object to invoke a method or member function using a reference or pointer to the memory location of the controlled object.
- An association represents a semantic relationship between instances of the associated classes. The member-end of an association corresponds to a property of the associated class
- An aggregation is a kind of association that models a part/whole relationship between an aggregate (whole) and a group of related components (parts).
- A composition, also called a composite aggregation, is a kind of aggregation that models a part/whole relationship between a composite (whole) and a group of exclusively owned parts.
In database design, object-oriented programming and design, has-a (has_a or has a) is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership. In simple words, has-a relationship in an object is called a member field of an object. Multiple has-a relationships will combine to form a possessive hierarchy.
Object composition is about combining objects within compound objects, and at the same time, ensuring the encapsulation of each object by using their well-defined interface without visibility of their internals.Object composition may also be about a group of multiple related objects, such as a set or a sequence of objects.
Composition can be regarded as a relationship between types: an object of a composite type (e.g. car) "has" objects of other types (e.g. wheel).
This can be summarised as follows:
This is not how it works in the database applications that I write. If there is a parent-child relationship between two entities (tables) then my implementation works as follows:
The $parent_relations array can be used when constructing SELECT queries to insert SQL JOINS in order to retrieve one or more columns from a parent table.
The $child_relations array is used in any DELETE operations to carry out any referential integrity requirements.
Databases do not have "associations", they have relationships. A relationship is between 2 tables (relations) where one is regarded as the parent and the other is regarded as the child. The existence of a relationship does not require the parent table to store a references to particular rows in the child table, instead it requires the child table to store a reference to the parent in the form of a foreign key whose columns have a logical link to corresponding columns in the primary key in the parent table. This is also known as a "one-to-many" relationship because the parent can have many related rows on the child table, but the child can only link back to a single row on the parent table. In an Entity-Relationship Diagram (ERD) this is often depicted as shown in Figure 1:
Note that the column names used in the child's foreign key need not be the same as the names used in the parent's primary key, but the types and sizes of each column in the foreign key must be the same as the corresponding column in the primary key. Note also that a table can be related to any number of child tables and also to any number of parent tables.
Note also that it is not necessary to go through the parent table to access the child as they are regarded as independent objects. A table may have foreign keys to more than one parent table, so it is not possible to restrict access to a particular parent. It is also possible to access a table without going through any foreign key. While any column may be used as a foreign key, the identity of the parent table is not known unless a foreign key constraint has been defined.
There are certain phrases in those definitions provided in the Introduction which do not reflect the way in which parent-child relationships in a database actually work, so I ignore them as the implementations that they suggest would be incomplete and inadequate.
The phrase The member-end of an association corresponds to a property of the associated class
implies that the parent object must contain a property/variable which points to an instance of an entity on the child object. In other words it must point to a particular row, or rows, within the child table. This is not how it is done in the RADICORE framework. The parent object does not contain any objects which represent rows on a child table, nor does it hold the primary keys of any rows on the child table. All it does is provide the identities of any child tables as well as the identity of the foreign key field(s) which can be used to access the related rows in the child table. This information is held in the $child_relations array. There is also a corresponding entry in the $parent_relations array of the child entity which identifies all the parent relationships which may exist for that child entity.
The phrase allows one object instance to cause another to perform an action on its behalf
implies that in any parent-child relationship you must go through the parent object in order to access the child. This is often interpretted as meaning that you must have a method in the parent object which will allow you to access the child object. This is not the interpretation that is used in the RADICORE framework. It is possible to achieve the act of "going through" in two ways:
It would appear that most programmers are taught to do the former while I have learned the advantages of the latter. Before accessing a child table all that may be necessary is to convert the primary key of the parent into the foreign key of the child, and how and where this conversion is done is a matter for the individual programmer. I say "may" as it is possible to read from a table which has one or more parents without specifying any foreign key values. When writing to such a table it is not necessary to "go through" the parent object to provide the foreign key value as the only requirement is that a value for any non-optional foreign key column is provided. How that value is provided is a matter for the the developer and not the author of any programming principle, especially when that author has little or no knowledge of writing database applications. I do not use custom code inside a parent entity to access a child entity, instead I use generic code within a controller, such as that used in the LIST2 pattern, to access the two entities separately.
In the RADICORE framework none of my table classes contain properties which are set to instances of any child objects, which means that access to those child objects cannot be performed by calling methods on those parent instances. However, the existence of relationships with child tables is recorded in the $child_relations property and the existence of relationships with parent tables is recorded in the $parent_relations property. It is standard framework code that will use this metadata to instantiate and communicate with those related objects, not customised application code.
In the RADICORE framework the most common method of "going through" the parent in order to access the child is using a task which is built using the LIST2 pattern. In this pattern the Controller will first retrieve one or more rows from the parent object and display them one at a time with a scrolling area. It will extract the primary key of the current row, then it will call the getForeignKeyValues() function to convert that primary key to the foreign key of the child. It will then access the child object using the foreign key as a filter. If it is not possible to use this method to provide the value for a foreign key before the ADD screen is activated, such as when a table requires an additional foreign key, then another approach would be to use the Data Dictionary to set the Control value for that foreign key column to a POPUP button. When this is pressed at runtime it will activate a POPUP form which will allow the user to pick a row from the parent table, thus ensuring that a valid primary key is chosen.
Instead of "going through" the aggregate root I record its identity by creating a primary key on each child table which includes the primary key column of its parent table. This produces a compound or composite key.
The following types of relationship are possible:
| One-to-Many | This is where the child table (B) has a primary key and a separate foreign key. Each parent (A) in this type of relationship can have zero or more children, and the child can have no more than one parent. | 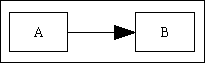 |
| One-to-One | This is where the foreign key on the child table (B) is exactly the same as its primary key. Each parent (A) in this type of relationship can have no more than one child, and the child can have no more than one parent. | |
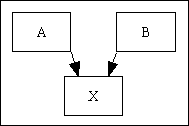
| Many-to-Many | This is often shown using the image to the right, meaning that "many of entity A can be related to many of entity B". This arrangement is not valid in a database. | 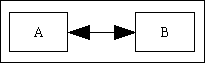 |
| Instead it has to be implemented as a pair of one-to-many relationships using an additional intersection table as shown as entity "X" in the image to the right. This intersection table then requires a separate foreign key for each of the parent tables, and a primary key which is comprised of both foreign keys in order to prevent the same combination of foreign keys from being added more than once.
Further thoughts on this type of relationship can be found at How to handle a Many-to-Many relationship - standard. |
 |
|
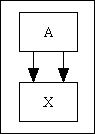
| Multiple | This is where a child table has more than one foreign key which pointing to the same parent table. It has two variations:
|
 |
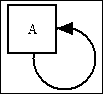
| Self-referencing | This is where a table is related to itself. In this case the name(s) of the column(s) in the foreign key must be different from the name(s) of the corresponding column(s) in the primary key. No row should be related to itself.
Further thoughts on this type of relationship can be found at How to handle a Many-to-Many relationship - Self-Referencing. |
 |
| Optional | This is where a row in the child table can exist without a reference to an entry in the parent table. This is done by designating each column in the foreign key as NULLable instead of NOT NULL. The relation_type on the DICT_RELATIONSHIP table should also be set to NULLABLE so that when an entry on the parent table is deleted the foreign key on all related child entries is set to NULL. |
Regardless of how each of these different types of relationship will be handled in the application, in the database they require nothing more than a link between a foreign key on the Many/Child table and the primary key on the One/Parent table. All the necessary processing is carried out by the framework by means of code in the Controller, the View and the abstract table class which is inherited by every Model (table subclass).
Note that it is possible for a foreign key to exist without a foreign key constraint, in which case all referential integrity must be carried out within the program code.
Prior to switching to PHP I had developed many applications and had dealt with hundreds of tables and relationships, so I knew what had to be done and how to do it. When I saw the code samples written by OO "experts" what immediately struck me was that their solutions were totally different, more convoluted and more complicated than mine. It became quite obvious to me that these people had no prior experience of database applications, had no experience of dealing with different kinds of relationships, but had come up with theories of how it could be done in a OO way without understanding how it had actually been done in non-OO languages. This lack of understanding led to a totally different approach:
In the RADICORE framework every relationship, regardless of its flavour, is defined in exactly the same way:
It is not necessary for a developer to insert custom code into a table class to access a related table as this is handled automatically by the framework, either in a controller script which handles related tables (such as the LIST2 pattern) or standard code within the abstract table class.
There are two ways in which the two tables in a parent-child relationship can be viewed, as shown in Figure 2 and Figure 3:
In this view, used by the LIST 2 pattern, the two tables have separate zones in the screen, and each zone is subject to its own set of method calls. A row from the Parent table is read first, and the primary key is extracted and converted into the equivalent foreign key for the Child table using the getForeignKeyValues() function which is called from within the Controller. This is then used as the $where string to read associated rows from the Child table. Note that with this pattern it is impossible to access entries on the Child table without first going through an entry on the Parent table.
In this view, which is common to all Transaction Patterns, there not a separate zone for the Parent table as the SELECT statement which is generated for the Child table will be customised to include one or more columns from the Parent table by means of an SQL JOIN. This can either be done manually by inserting code into the _cm_pre_getData() method, or you can get the framework to do this for you using the mechanism described in Using Parent Relations to construct sql JOINs. This means that all the data from both tables can be retrieved using a single call to the getData() method on the Child table.
It is precisely because I use a single $fieldarray variable to hold the table's data that I can include any number of columns from any number of tables. This avoids the restriction of only being able to display columns from a single table if I were to define each column as a separate variable with its own getter and setter.
There are some programmers who have been taught that every table should a technical or surrogate key called "ID" whose value comes from a numeric sequence. I was taught differently. If a table has a semantic or natural key which is guaranteed not to change over the lifetime of that record then it is not necessary to create an artificial key. It also avoids the overhead of creating two unique keys - one for the column called "ID" and another for the column containing the natural key.
Some programmers are also taught that a primary key should not be comprised of more than one column. I was taught differently. In a relational database a primary key can be comprised of any number of columns, but use your common sense and don't go overboard. For example, if I have a hierarchy of tables called Parent -> Child -> Grandchild I would probably use the following primary keys and foreign keys:
| Table | Primary key | Foreign key |
|---|---|---|
| Parent | parent_id | |
| Child | parent_id+child_id | parent_id (links to Parent) |
| Grandchild | parent_id+child_id+grandchild_id | parent_id+child_id (links to Child) |
An experienced SQL developer would know that in this example it would not be necessary to create an index for the foreign key as that is already covered by the leading columns in the index for the primary key.
In a real world example of Order -> Order_Item -> Order_Item_Feature
| Table | Primary key | Foreign key |
|---|---|---|
| Order | order_id | |
| Order_Item | order_id+order_item_seq_no | order_id (links to Order) |
| Order_Item_Feature | order_id+order_item_seq_no+feature_id | order_id+order_item_seq_no (links to Order_Item) |
| feature_id (links to Product_Feature) |
I am using a technical key called order_item_seq_no on the Order_Item table as it does not have a suitable natural key. While some inexperienced developer may think that product_id could be used that is not the case. It is possible for the same Order to have several Order_Item entries for the same product_id, but with a different combination of Product_Features
Whenever a user transaction (task) is executed it does not involve code in a single module, it uses several modules, namely a Model, View, Controller and DAO, which work together in harmony, like those shown in Figure 4:
Figure 4 - MVC plus 3 Tier Architecture
")
While the Model contains a number of different methods it is the Controller which controls which methods are called in which sequence and with what context. This means that some of the logic for a user transaction is contained within the Controller instead of being completely within the Model. It is only after having worked on thousands of user transactions that I have been able to notice patterns of behaviour that have been repeated for different database tables, and I have managed to abstract out these patterns into a set of reusable controllers which are contained within my library of Transaction Patterns.
In my previous language, called UNIFACE, there was no separate Controller and View as these were both combined into a single component in the Presentation layer which communicated with one or more components in the Business layer. There was a separate component in the Business layer for each entity (table) in the Application Model. While each of these entities identified the table structure and the business rules they did not contain any code to deal with relationships as this was handled exclusively in the Presentation layer. If two tables were linked in a parent-child relationship then those two tables were painted in the screen, one inside the other, so that at runtime the UNIFACE software would first read the outer entity, then use the relationship details in the Application Model to convert the outer's primary key into the inner's foreign key so that it could then read the associated rows from the inner entity. This behaviour was logical and simple, so I duplicated it in my PHP code by putting the necessary code in my Controllers where it could be shared with any number of related entities instead of having to insert specific code inside each entity.
In the RADICORE framework each table has its own class, but none of these classes contains either properties or methods to deal with any relationship. Instead the existence of each relationship is identified in either the $parent_relations property or the $child_relations property of the two tables which are involved in that relationship. This information is then used by different components within the framework to deal with that relationship in the appropriate manner. Typically this involves creating a user transaction from a Transaction Pattern which has been designed specifically for that flavour of relationship. While a large number of tables can be maintained using the family of transactions shown in Form Families, others may require a different set of patterns. For example, in those cases where a child table requires the existence of a row in a parent table, because it contains one or more foreign keys, there are two possible approaches:
This pattern will use two entities - the parent (or outer) at the top with the child (or inner) below it. This pattern operates by calling the getData() method on the parent/outer entity using whatever selection criteria which was passed down from the previous screen, which is usually a LIST1. It will display only one row at a time for the parent entity from which it will extract the primary key. It then calls the getForeignKeyValues() function to construct a WHERE string for the foreign key of the child/inner entity using this primary key. This will be used to call the getData() method on the child entity to retrieve as many rows which are available to fit into the screen, subject to the user-defined page size. To create a new entry on the child table the user presses the navigation button labelled 'NEW' which will activate a task which uses the ADD2 pattern. This will then use that WHERE string to populate the relevant foreign key field(s).
This is used when the value for the foreign key is not passed down from the previous screen, in which case the user must supply it manually. Instead of using a textbox control on the HTML form a popup button ![]() will be shown instead. The user presses this button in order to activate a separate POPUP form which will display a list of entries from the parent/foreign table and wait for the user to select one and press the CHOOSE button. This will cause the primary key of the selected entry to be passed back to the ADD2 screen where it will be used to populate the foreign key fields.
will be shown instead. The user presses this button in order to activate a separate POPUP form which will display a list of entries from the parent/foreign table and wait for the user to select one and press the CHOOSE button. This will cause the primary key of the selected entry to be passed back to the ADD2 screen where it will be used to populate the foreign key fields.
Note that there are several different patterns which may be used to deal with many-to-many relationships.
Referential integrity checks the validity of the link between the foreign key and the associated primary key in order to ensure that data integrity is maintained. In the RADICORE framework's Data Dictionary each relationship has a type column which specifies how the relationship is to be treated when deleting entries from the parent/senior table. This has the following options:
If a foreign key constraint has been defined within the DBMS then the framework will do nothing and allow the DBMS to take the necessary action.
While foreign key constraints are processed by the DBMS during insert, update and delete operations, they are totally ignored when performing a SELECT query. However, the RADICORE framework can utilise the contents of the $parent_relations array to automatically retrieve columns from a foreign/parent table during a getData() operation. This is described in Using Parent Relations to construct sql JOINs.
Martin Fowler defines an aggregate as follows:
Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line-items, these will be separate objects, but it's useful to treat the order (together with its line items) as a single aggregate.
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
Aggregates are the basic element of transfer of data storage - you request to load or save whole aggregates. Transactions should not cross aggregate boundaries.
While I agree that the components of an aggregate are separate objects, just like those shown in Figure 5 and Figure 6, I do not agree that the components of the aggregate should be accessed through an aggregate root. This concept does not exist in the database, and has never existed in any software which I have worked on in the last 40 years. No table in a database has any special operations to deal with related tables, so I do not see any reason to put any special methods in any table class to deal with those relationships. It is an alien and artificial concept which does not exist in my universe. I cannot see any advantages of going through an aggregate root, only disadvantages. When retrieving data from two tables there are only two options:
The way that I deal with relationships is through standard code which is built into components in my framework. OO theorists like to over-complicate matters with the following distinctions:
In relational theory it is much simpler than that. A relationship between two tables is signified by one table, the child, having a foreign key which points to the primary key of the other table, the parent. All accessing is performed using the standard CRUD operations. A composition is achieved by setting all the foreign key fields to NOT NULL, in which case the child row must always contain a reference to a row that exists on the parent table. By setting the type in Referential Integrity to CASCADE all the child records will be deleted when the parent is deleted. An aggregation is achieved by setting all the foreign key fields to NULLable, in which case the child row either contains a reference to a row on the parent table or it does not contain a reference at all. By setting the type in Referential Integrity to NULLIFY all the child records will be updated when the parent is deleted.
In my experience this thing called an object aggregation is nothing more than a collection of parent-child relationships which can be arranged into a hierarchy which could be several levels deep, such as parent-child-grandchild-greatgrandchild-whatever. Two types are supported in the RADICORE framework:
A Composition implies that the contained class cannot exist independently of the container. If the container is destroyed, the child is also destroyed. This is represented in a database by having a separate table for each child, and each row in the child table has a foreign key, which is set to NOT NULL, which relates it to a row in its parent table. Thus a child row cannot be created without providing a value for that foreign key.
Figure 5 - an aggregate ORDER object (a fixed hierarchy)
")
In this hierarchy none of the rows in a child table in any relationship can exist without a corresponding row in the parent table. If a parent is deleted then all of its children must be deleted. Each of the objects in the above diagram is a separate "entity" with separate structures and separate rules, therefore each will have its own class. Note that while each table class knows of the existence of any immediate parent or child tables, it has no knowledge of any other tables which may be related to those parent or child tables.
This collection of tables is joined together to form a fixed hierarchical structure. An inexperienced person would look at this collection and immediately think that it is so unique that it requires a special non-repeatable solution. However, a more experienced person, one who has been trained to look for repeating patterns which can be turned into reusable code, should to able to see something which is quite obvious - this collection contains ten pairs of tables which are joined in a one-to-many/parent-child relationship, and every such relationship will always be handled in exactly the same way. No row can exist in the child table unless it contains a foreign key which contains the primary key of a row in the parent table, and the RADICORE framework has a standard method for dealing with foreign keys. This means that I can deal with this collection of tables by creating 66 tasks which use the following Transaction Patterns:
It is the use of the ADD2 pattern which ensures that no child record can be created without a reference to its parent record.
The only time I would want to read all the data from all of these tables would be if I wanted to produce a printable copy of the entire order, in which case I would construct a task based on the OUTPUT3 pattern.
The idea that I should be forced to go through the aggregate root in order to access any component within the aggregation is also handled differently. Instead of creating a class to handle the responsibilities of the aggregate root I can achieve the same effect by only allowing the LIST1 task for the root table, which is this example is ORDER-HEADER, to be accessible from a menu button. All the LIST2 tasks for each child table are only accessible from a navigation button on the parent task. This means, for example, that you would have to go through both the ORDER-HEADER and ORDER-ITEM tasks before you can access any ORDER-ITEM-FEATURE entries.
Some OO afficionados might spot that this arrangement, where the ADD1 task for the ORDER_HEADER table is totally separate from the ADD2 task for the ORDER-ITEM table, allows me to create an ORDER_HEADER record without any corresponding ORDER_ITEM records, which would technically be invalid. My logic for doing it this way is that it would be far too cumbersome for the user to enter data for the entire order using multiple screens before pressing the SUBMIT button, so I separate the data into one screen at a time so that the order can be built up incrementally. When the ORDER-HEADER record is first created it has an order_status which is set to "Pending", and while it has this status the user can make whatever additions, deletions and corrections to any part of the order as is necessary. Once the user is satisfied that all the details have been entered correctly he can change the order_status to "Complete", but this will not be allowed if there aren't any entries on the ORDER-ITEM table. Once the order comes out of the "Pending" status no further amendments will be allowed to any part of the order except to advance the status to the next value.
Note that in this particular hierarchy the only child table in any relationship which is required is the ORDER_ITEM table. All others are entirely optional. If an entry on a Parent table is deleted then all related entries on the Child table will also be deleted.
What is not shown in Figure 4 is that the ORDER-HEADER table has an additional foreign key to the CUSTOMER table, and the ORDER-ITEM table has an additional foreign key to the PRODUCT table. These are handled using a POPUP button.
An Aggregation implies that the contained class can exist independently of the container. If the container is destroyed, the child is not destroyed as it can exist independently of the parent. Martin Fowler has this to say on the subject of aggregates:
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
This wikipedia page has this to add:
Objects outside the aggregate are allowed to hold references to the root but not to any other object of the aggregate. The aggregate root checks the consistency of changes in the aggregate.
This is not how databases work. There is no such thing as an aggregate root which controls access to every member of that aggregation. An aggregation is nothing more than a collection of one-to-many or parent-child relationships, and the only "requirement" when accessing a relationship is that you obtain the primary key of the parent so that you can convert it to the foreign key of the child.
An aggregation is represented in a database by having a single table for the entities, and a separate table to identify the relationship between one entity and another. The "entity" table does not have any foreign keys for its parents, but the "relationship" table has two foreign keys to the "entity" table, one for the parent and one for the child. This allows for a row in the "entity" table to have zero or more relationships, so at the same time it can have zero or more parents and zero or more children. It is possible to delete a row on the "relationship" table without affecting any row on the "entity" table, but a row on the "entity" table cannot be deleted without first deleting all associated rows on the "relationship" table.
Figure 6 - an aggregate BILL-OF-MATERIALS (BOM) object (an OO view)
")
While a novice may see this as a collection of one-to-many relationships a more experienced person will recognise that not only can a CAR contain an ENGINE but the same engine (by which I mean a similar engine with the same specifications, not the same physical engine with the same serial number) may be contained in several other CARS. This results in what is known as a many-to-many relationship which is implemented by introducing an intermediate intersection or link table which then produces a pair of one-to-many relationships. This means that in this particular structure each of those entities is a record on the same table (in this example it is the PRODUCT table) while the relationship between one of those records and another is a record on the intersection table (in this example it is the PRODUCT_COMPONENT table).
I have seen the structure shown above in Figure 6 in several books on the OO design process where it shows an example of an object which is composed of (or comprised of or acts as a container for) other objects to form a hierarchy which could be many levels deep. Each of these objects represents a separate class. This means that each of those classes would require built-in references to each of its immediate components. This also means that when the Car class is instantiated it also instantiates the Engine, Stereo and Door classes which, in turn, instantiates the Piston, Spark Plug, Radio, Cassette and Handle classes.
In a database application this is absolutely, emphatically, totally wrong. None of the different products has its own class, it has its own row in the same PRODUCT table, and each row in a table shares/inherits the same structure and behaviour as every other row in that table. There is nothing within the PRODUCT class which identifies a row as being either a container or being within a container - this would require the use of a separate PRODUCT_COMPONENT table to implement a many-to-many relationship, as shown in in Figure 7 below, which could then be viewed and maintained using separate tasks.
In the RADICORE framework there is no need for a developer to insert custom code into a table class to access a related table as this is handled automatically by standard code within the framework. It is only necessary to identify the existence of each relationship within the DATA DICTIONARY so that it appears in the $child_relations array of the parent and the $parent_relations array of the child.
Figure 7 - an aggregate BILL-OF-MATERIALS (BOM) object (a database view)
")
This is a pair of tables which form a many-to-many relationship where both foreign keys on the intersection (child) table refer back to the same parent table. This produces a recursive hierarchy which can extend to an unknown number of levels as each parent can have any number of children, and each of those children can also be a parent to its own collection of children, and so-on and so-on. This produces what is commonly known as a Bill Of Materials (BOM).
With this arrangement an entry on the PRODUCT table can exist without any entries on the PRODUCT_COMPONENT table, but the reverse is not true. You cannot insert an entry into the PRODUCT_COMPONENT table without specifying the identities of two different rows in the PRODUCT table. There is no logic in the PRODUCT class which deals with the contents of the PRODUCT_COMPONENT table, just two entries in the $child_relations array. Similarly there is no logic in the PRODUCT_COMPONENT class which deals with the contents of the PRODUCT table, just two entries in the $parent_relations array.
Note that in this particular hierarchy although the effect is to relate one PRODUCT to another there is no direct relationship between the PRODUCT table and itself, instead there is an indirect relationship through the PRODUCT_COMPONENT table which is known as an intersection/link table. An entry cannot exist on this Child table without corresponding entries on the Parent table. If an entry on this Child table is deleted it has no effect on the related entries in the Parent table.
In this example the PRODUCT table contains a primary key called product_id while the PRODUCT_COMPONENT table has the following structure:
| Field | Type | Description |
|---|---|---|
| product_id_snr | string | Identifies the parent (senior) product in this relationship. Links to an entry on the PRODUCT table. |
| product_id_jnr | string | Identifies the child (junior) product in this relationship. Links to an entry on the PRODUCT table. |
| quantity | number | Identifies how many of this product are required in the parent product. |
Note that product_id_snr and product_id_jnr are separate foreign keys which both link back to the same PRODUCT table. They are also combined in the primary key to ensure that the same combination is not used more than once. This forms a recursive hierarchy as it can contain more than the two levels which are indicated by the two tables.
Note also that products can be added or removed from the PRODUCT_COMPONENT table without affecting the contents of the PRODUCT table. While the PRODUCT table can be maintained with a forms family starting with a LIST1 pattern, the PRODUCT_COMPONENT table would be maintained by a forms family starting with the LIST2 pattern. This would show as its parent entity the product that was selected in the PRODUCT table's LIST1 screen, and below it would appear that product's immediate children. To see the entire hierarchy in a single screen you would create a task using the TREE2 pattern, or you could export it to a spreadsheet using the OUTPUT6 pattern.
This shows that the two tables can be handled independently of each other. The fact they they are related is built into the database structure which is then copied into the $child_relations and $parent_relations arrays of each table class. The rule that says that an entry on the PRODUCT table cannot be deleted if it has any entries on the PRODUCT_COMPONENT table is enforced by the framework using the settings in the $child_relations array. The rule that an entry cannot be added to the PRODUCT_COMPONENT table without supplying valid values for two entries from the PRODUCT table is enforced by the ADD2 task where the identity of product_id_snr is passed down from the parent entity in the LIST2 task and the identity of product_id_jnr is selected from a POPUP task.
I have been told more than once that my practice of creating a separate class for each database table is not good OO. I have been told that each entity in the real world has to have its own class, and if its data needs to be spread across multiple database tables then that is a problem with the database which can be ignored as it can be dealt with using a Object-Relational Mapper. They seem to think that objects such as ORDERS (see Figure 5) and PRODUCTS (see Figure 6) should be handled within a single class, and all associations must be handled by going through the aggregate root. As I had never been taught this nonsense I never acted upon it for the simple reason that databases do not have "associations" in the OO sense, they have relationships where the only requirement is that the child table has a foreign key which refers to the primary key of a row in the parent table. In a database I do not have to go through the parent table in order to access a child, so I never put code in the parent's class to access any of its children. If I want to show data from the parent table and a child table in the same screen then I create a task based on the LIST2 pattern which accesses those two table independently.
This means that I never read data from a table until I actually want to show it on a screen as to do otherwise would be a waste of time. I only ever read data from a table when the user actually requests a task which displays or processes data from that table. This seems sensible to me, but there are others out there who seem to think that when dealing with an aggregation every member is a property of the aggregate root and should be instantiated and loaded with data whenever that root object is created. I remember reading a newsgroup post several years ago from someone who had written an application for his school. In his database he had a group of related tables called SCHOOL, TEACHER, STUDENT, ROOM, SUBJECT and LESSON, but he was complaining that his application was taking too long to load. It turned out that when he instantiated the SCHOOL class he was also instantiating all the other classes and loading in all their data even though it wasn't actually required. No competent database programmer would ever do it this way. Nobody would ever load that much data into a single object as it would never be displayed to the user in a single screen. He needed to stop loading all his data into a single object and concentrate on building separate tasks to display the contents of each table when it was actually required, and then only reading from the database that data which can fit into a single screen. This is precisely what I had done in a similar application called a Prototype Classroom Scheduling Application which is available in the download of my RADICORE framework. You can also run it online as an option under the "PROTO" menu so you can for yourself how quick it is to display the contents of different tables.
Here is a (famous?) saying that I invented several years ago:
Some people know only what they have been taught while others know what they have learned.
I cannot see any indication that the people who devised all these principles regarding associations, compositions and aggregations have had any experience with writing real-world enterprise applications which deal with relational databases. Anyone without such experience is simply not qualified to give advice on this topic. Any advice they do give should be taken either with a pinch of salt or a bucket of disinfectant, rubber gloves and a wire brush.
I had 20 years of experience with writing code to deal with relationships before I switched to an OO language, so I knew what steps to take. All I did was translate those steps into PHP using code which, following the KISS Principle and Do The Simplest Thing That Could Possibly Work, was simple and direct. My solution is less complicated and therefore better than what is being taught by all these so-called OO "experts", so if other developers want to avoid writing code which is more complex and convoluted than it need be they first need to unlearn what they have been taught and try a different and therefore better approach.
Here endeth the lesson. Don't applaud, just throw money.
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
| 08 Mar 2026 | Amended the Introduction to include a statement saying this is not how it works. |
| 27 Jul 2024 | Added Choosing a primary key
Amended the descriptions in Object Composition and Object Aggregation to be more explicit. |