In my long career as a software engineer I have encountered many different sets of development standards. Each organisation tends to have its own set, although I have come across some which have been copied by more than one organisation. I have even worked in companies where different teams within the same company have had different standards. The quality of these standards has varied greatly, which, at the poorer end of the scale, I can only describe as being 'sub standard'.
The purpose of this document is to raise the following questions:
There are a surprising number of people who accept that there must be standards, but who don't really understand the reason why. It is these people who are likely to produce poor quality standards which are a hindrance to the development process rather than a help. In my opinion standards should fulfil the following criteria:
There may be several different ways of achieving an objective, but each different method will have its own set of advantages and disadvantages. The 'best' method is one than minimises the disadvantages while maximising the advantages. A particular method may look acceptable to a novice, but an experienced person will probably be able to say: 'This other method is better because....'
For example, a routine is called with some data which has to be processed differently according to a field called 'TYPE', which may have a value of either '1', '2' or '3'. A novice might think that the following code would suffice:
selectcase TYPE case 1 ..... case 2 .... elsecase .... endselectcase
The logic behind this is that if TYPE is not equal to '1' or '2' then it must be '3'. A more experienced programmer will immediately point out that if a different value for TYPE were to be encountered, either because of a legitimate change or because of a program bug, then it could result in a serious problem. If this piece of code were to be left untouched it would treat TYPE 'x' in the same way as TYPE '3', which might lead to confusing or even disastrous results. A programmer who has experienced this set of circumstances before would produce code similar to the following:
selectcase TYPE case 1 ..... case 2 .... case 3 .... elsecase message "Unexpected value for TYPE (%%type)" return(-1) endselectcase
The logic behind this is that each known value for TYPE is dealt with explicitly, with a trap at the end for any unknown value. This could either be because a new value had been introduced into the system and this program had been accidentally left out of the amendment process, or a bug in the calling program had set the value incorrectly. Either way it would be detected and reported immediately rather than passing through the system and going undetected for a period of time and possibly corrupting some data. Which of these two methods would you consider to be 'best practice'?
Good standards should therefore identify common mistakes that a novice can make and show a more robust solution that a veteran would use. These should always be accompanied by proper explanations so that the novice can understand why one solution is actually better than another. In this way the development standards can provide a significant contribution to the novice's training programme.
Nothing annoys a user more than to have similar programs working in dissimilar ways just because they were written by different programmers. A standard 'look and feel' should be agreed upon beforehand, and every program should conform to these standards. It should not be possible to recognise the identity of the programmer by the way a particular program appears or behaves.
For example, some programs may have both the <STORE> and <ACCEPT> triggers, but with different processing in each one - the <ACCEPT> trigger will update the database and exit, while the <STORE> trigger will update the database, clear the screen and wait for new input. There are three ways of firing UNIFACE triggers:
Novice users do not like option (1) on its own because they have difficulty remembering the control codes. After a while they will tire of option (2) because it requires at least 2 keystrokes to select an action. Option 3 is the favourite because it requires just a single click on an easily identifiable button, and the absence of a button in a particular screen shows immediately that the action is not available in that screen. If it has been agreed that 'action' buttons are to be employed then the following points should also be agreed:
This common 'look and feel' does not just apply to the user's view of a program (the 'external' view) - it can also be extended to the way in which the code is written (the 'internal' view). I have heard that in some organisations once you write a particular program it becomes your private domain until the day you leave, the assumption being that no-one else will be able to understand your design or your style of coding. This idea strikes me as being totally unprofessional as well as unproductive.
For many years I have encouraged what I call 'ego-less programming' in which all code is written to a common style. The aim of this common style should be quality workmanship. In case you don't know what 'quality' means, here are some headings to help you:
Table 1 - the definition of 'quality' code
| Reliability | Code should carry out its task reliably and consistently. A program that occasionally produces wrong results is not appreciated. |
| Efficiency | Code should complete its task in an acceptable amount of time. A program that takes a day and a half to complete a day's work is not appreciated. |
| Productivity | Code should be written and tested in an acceptable amount of time. In these days of Rapid Application Development (RAD) programs that take weeks to write instead of hours are not appreciated. |
| Reusability | Common code should not be duplicated, it should be defined once in a central object (a global proc, an include proc, a component or a component template) then referenced from that central object when required. Changes to that common code can then be made just once in the central object and instantly be available to the rest of the system. |
| Practicality | Code should perform its task in a logical and practical manner using recognised techniques. Code that does things in a weird or esoteric way just to prove the genius of the author is not appreciated. |
| Legibility | Code should be written so that another human can read it and quickly understand what it is doing and how it does it. Code that can only be read and understood by the author is not appreciated. |
| Maintainability | Code should be able to be maintained by any member of the development team, not just the author. Code that cannot easily be maintained is not appreciated. |
Any programmer should be able to pick up any program within their organisation and feel that they are in familiar territory rather than on another planet. The identity of any programmer who has worked on the program should be totally transparent, except when looking at the program's amendment history. If you write a program on the assumption that it will be amended by someone else, and your next task will be to amend someone else's program, then it might encourage you to do a professional job in the first place. If you produce crap code that somebody else has to deal with, then sooner or later the favour will be returned and you will have to deal with crap code that somebody else has produced. In other words you should write code that other people can understand to encourage them to write code that you can understand.
Novice programmers must learn that it is not sufficient to write as much code as possible as quickly as possible. It is not very productive to spend an hour writing some code only to spend the rest of the day trying to get it to work. In my book it is preferable to spend an extra hour when writing the code if it means that two hours less can be spent in testing and debugging.
Too many programmers, even some experienced ones, do not consider 'readability' to be an issue. 'Code is code, right? Anybody can read code, right? If it works then it cannot be considered to be badly written, right?'
Wrong! The issue here is maintainability. When someone needs to make a change to your program it is vitally important that they can understand the code so that they can make the necessary changes quickly and effectively. Among the techniques that make code readable are the following:
Table 2 - techniques to make code readable
| Indentation | IF, ELSE and ENDIF statements should start in the same column, but the conditional statements should be indented. This makes it easy to spot which block of code goes with which condition. I grew up with an editor in which we could set a tab stop for each level of indentation - this is far more efficient than hitting the space bar 3 or 4 times. |
| Comments | Where a group of lines deals with a particular task a comment should be included which describes that task. It is sometimes possible to spot bugs simply because the code does not match the comment. |
| Blank lines | Where a group of lines deals with a particular task they should be separated from other groups by blank lines. This makes it easier to pick out the different tasks (steps) within a module. |
| Alignment | Where several lines of code contain either '=' (assignments) or ';' comments it is more readable if the '=' and ';' signs are aligned in the same column. This does not necessarily mean that each of these signs must be in the same column in very program, but just within each group of lines. |
| Case | It is possible to write code using a mixture of upper and lower case - there are very few occasions where case is important. Lower case is preferred because UPPER CASE IS CONSIDERED TO BE THE SAME AS SHOUTING! There are some circumstances where using upper case can be useful, such as identifying where a module passes control to another module (using CALL or ACTIVATE). Some people insist that each field and entity name be in upper case, but to my mind this serves no useful purpose. I actually find it a hindrance when typing my code because I have to waste that extra split second to press the SHIFT key. |
If you do not believe that these little points are significant then try the following: find a program which is totally devoid of these techniques and see how easy it is to read and understand. If you are like me you will find yourself automatically separating each group of lines that perform different tasks with a blank line, then annotating each group with a comment which describes the particular task that they perform. This particular lesson was brought home to me many years ago when I had to amend a program which did not contain any comments. I had to spend a long time analysing the code so that I could identify what each group of lines did. From this I could identify what each module/section did, and from this I could identify how the program flowed between one section and another, and why it chose to down one path instead of another. Only by doing this could I understand the program enough to know with confidence where to make my change. The significant fact is that I myself had written this very program some 6 months earlier, so if I as the original author had a difficult time in getting to grips with the code then what chance would somebody else have? Ever since that day I have included comments in my code as I write it as it takes far less time to do it then than it will later on.
These are simple techniques that I used in COBOL 20 years ago, and they are just as valid in UNIFACE today. The main reason for having documentation included in the code was that it removed the problem of having separate documentation which programmers never got around to updating. In fact this idea of building documentation inside the actual code has been incorporated into the JAVA language - there is a tool called JavaDoc which has been specifically designed to extract comments from within the code in order to provide documentation.
In my book there are four stages to becoming a professional (competent) programmer:
If your development standards do not assist you in achieving all of these stages then I am afraid that they are not worth the paper they are printed on.
I have worked on some projects where the development standards were put together by a mixture of managers and users rather than developers. The end result was always the same - disastrous. It is a waste of time these people dreaming up what they would like to have if the development tools cannot provide it, either not at all or not without great difficulty. I have seen developers struggle for days and even weeks trying to make something work in the manner dictated by the users when a much easier solution was available.
Only a developer knows the capabilities of the development language; knows what can be done easily and what can be done with difficulty; knows which method is efficient and which is inefficient; knows what can be achieved in moments and what will take months; knows what is practical and what is impractical. In today's world of Rapid Application Development (RAD) it is a waste of time blaming the developer for poor productivity if the bottlenecks have been created by others in the form of a poor design or poor development standards. If you want an athlete to compete in a sprint then you equip him with proper running shoes, not hob-nailed boots with fancy go-faster stripes. Proper development standards are supposed to be a help to the developer, not a hindrance.
As a rule of thumb neither managers nor users should be allowed to decide what they want until the developers have told them what choices are actually available, and what the cost is of each of those choices. A trick I learned from Gane and Sarson years ago was to ask a simple question - 'If I can do it this way for £5, how much extra are you willing to pay to have it done your way?'
If the answer is "nothing" then "nothing" is what they deserve.
Sometimes users fail to accept the standard functionality of the development tool and want something different, regardless of the fact that it will take untold amounts of effort on the part of the developers. If a fix involves using the development tool in a way in which it was not designed to be used then the fix can sometimes become invalid in a later version of the development tool.
A prime example of this on an early COBOL project revolved around the way that numerical values were displayed on the screen. The screen handler expected each number to be right-justified, but the users insisted that their standard was to have them left-justified instead. This particular block-mode screen handler had three phases in its operation - an INIT phase, an EDIT phase, and a FINISH phase. The idea was that the EDIT phase was used to accept and validate user input, and only if there were no errors could the FINISH phase be called for final reformatting before the data was passed to the COBOL program for processing. The only way we could change the format of numbers from right-justified to left-justified was to call the FINISH phase before the EDIT phase instead of after.
Problem #1 was that we could no longer use the FINISH phase after the EDIT phase to right-justify each number again, so we had to include extra code in each COBOL program to deal with it. Problem #2 came when an update to the screen handler caused the FINISH phase to be ignored if it was called before the EDIT phase. We queried this with the manufacturer but were told quite bluntly that the system was designed to be used in the sequence INIT-EDIT-FINISH, so if we did not follow this sequence and hit a problem the problem was ours and not theirs.
We had to revert to the earlier version of the screen handler to get around this problem, but this was temporary because we had to install the new version sooner or later as part of a general upgrade to various other system components. This general upgrade included other fixes that were needed, so we had to change all the forms to remove the left-justification from the FINISH phase processing, then change all the COBOL programs to call the FINISH phase after the EDIT instead of before.
This was an enormous effort which could have been avoided if only the users had allowed the screen handler to be used in the way it was designed to be used instead of bending it to satisfy their whim.
Another example of this on one particular UNIFACE project was concerned with occurrence counting. Wherever multiple occurrences were possible we had to display the values 'N1 of N2', where 'N1' was the number of the current occurrence ($CUROCC) while 'N2' was the total number of occurrences ($HITS). After a great deal of persuasion we got the users to agree to use $CURHITS instead of $HITS because of the performance implications.
This is where Silly Idea #1 appeared. When the users were told that the value of $CURHITS would be negative if a stepped hitlist was in operation they said, 'Negative numbers are not intuitive. We want positive numbers instead.'
So instead of '1 of -10' they wanted to see '1 of +10'. When they saw the first screens that were written they immediately came up with Silly Idea #2. It is a 'feature' of UNIFACE that when no occurrences have been retrieved the first occurrence is still painted, but as an empty occurrence with the counters '1 of 0' being displayed. They did not like this idea. What they wanted was for an empty occurrence to be shown as '0 of 0', which would change to '1 of 1' as soon as the first field was changed. This meant putting code in the <start mod.> trigger of every field on that occurrence.
The end result was a mass of additional code whose only purpose was cosmetic, thus adding to the cost and complexity of each form without adding one ounce of functionality.
I have worked with a variety of 2nd, 3rd and 4th Generation Languages, so I know from experience that each language has its own unique set of capabilities. Things that you can do easily in one language may be more difficult or even impossible in another. Different languages achieve similar objectives in different ways, and you will never be proficient or productive in a particular language unless you learn what it can do and how it does it.
When the software house I was working in moved from COBOL to UNIFACE some of my colleagues struggled with the new language because they were still trying to design and code in the COBOL way. UNIFACE works with triggers, and if you don't put the right code in the right triggers it just will not work as you expect. On several occasions I was asked to help someone with their problem, and instead of attempting to debug individual lines of code I would ask the simple question 'What is it that you are trying to achieve?'
Upon hearing the answer I was able to say 'You are wasting your time trying to do it that way - move this code to that trigger; change this code to that; and dump this code entirely.'
When reviewing the results my colleague would sometimes say 'But I don't want to do it that way!'
to which I would reply 'If you want it to work in UNIFACE then you must do it the UNIFACE way - the COBOL way will only work in COBOL.'
It took a long time for the message to sink in that if you worked with the development tool instead of against it you would achieve results sooner instead of later.
On a later project with a different software house I encountered a different problem. The senior analysts had a background in C and C++ rather than UNIFACE, and their attitude was that the Objected Oriented (OO) methodology was the only way to go. Consequently they tried to bend UNIFACE so that it would work in an OO way. Unfortunately UNIFACE was not designed to be an OO tool, it was designed around the Component-Based Development (CBD) paradigm, therefore it does not contain some of the features of OO languages. It may come as no surprise to learn that if you try to make a language do what it was not designed to do, or work in a way in which it was not designed to work, then sooner or later you will hit a brick wall and come to a grinding halt. These people wanted to implement the N-tier architecture with a separate application model for the presentation layer, but as their design revolved around OO techniques that were not provided for within UNIFACE the end result was enormous amounts of complicated code. They ended up with 10 layers of components between the presentation layer and the database, and it took an enormous amount of time to make even a simple screen to work. So much time in fact that when the client was informed that this methodology would blow both his budget and his deadline in a very big way he immediately cancelled the whole project.
The moral of this story is that you should tailor your design and your development standards to fit the development tools, and not attempt to bend your development tools to fit your design or your standards. If you try to bend something too far it will eventually break, and all you end up with is a lot of time and effort being flushed down the toilet.
The leaders of this doomed project had a team of 6 developers working for 6 months building and testing their development infrastructure, but at the end of the day it proved to be totally worthless. When I left the client's site and returned to my head office I decided to build my own version of a 3-tier infrastructure with a separate model for the application layer. What those supposed 'experts' could not accomplish in 6 months I managed to complete on my own in 2 weeks. The results can be reviewed in 3 Tiers, 2 Models, and XML Streams. I have subsequently used these ideas to convert the 150+ forms in my demonstration system, which contains a Menu and Security system and a sample application, so that it is totally 3-tier. It just goes to show what you can achieve if your approach is sound to begin with.
Good standards should not simply say Do this...
or Don't do that...
they should say Do this because....
and Don't do that because...
. The reasoning behind each statement should be explained so that it can be verified as being 'best practice' and not simply a rule for the sake of having a rule. You may think that such explanations should be unnecessary, that developers should follow the rules without question, but I most certainly do not.
In the late '70s while working for a software house I finished with one development project and was moved onto another, and I noticed that the development standards between the two projects were totally different. Some things that had been encouraged in the previous project were forbidden in the new one, and vice versa. This became a problem when I was required to write a program that included several complex calculations. Those of you who know COBOL will recognise the usefulness of the COMPUTE verb. However, the project standards stated quite categorically 'Do not use the COMPUTE verb'. I asked the project leader why and was fobbed off with the reply 'Because it is inefficient'
. I was not happy with this answer as I had used this verb successfully in other programs on other projects, so I asked for a fuller explanation. Eventually this was the answer I received:
A=A+1 to increment a value, and when doing the same thing in COBOL would translate it into COMPUTE A=A+1. This use of the COMPUTE verb is not efficient - the statement ADD 1 TO A should be used instead.'While I agreed that the COMPUTE verb was indeed inefficient in those circumstances I knew from previous experience that there were other circumstances when it was the most efficient, so I could not understand why there was a blanket ban on its use. When I queried this point with the project leader I could see that he was rather upset at having his supposed expertise called into doubt, but I didn't let a little thing like that stop me. I began to question some of the other statements in the project standards and quickly realised that a lot of them were based on unsubstantiated or second hand opinions. Instead of being examples of programming excellence they merely reflected the limited experience and abilities of the author. Some of the rules appeared to have been the result of the toss of a coin rather than direct experience, or were included merely to pad out the empty spaces in the standards document.
The only way I could complete that program within the timescale that I was given was to ignore the standards completely and write it to the best of my ability without having to work down to the best of someone else's lesser ability. Several weeks later there was a project audit by a senior consultant and my program was one of those selected for a code review. I still vividly recall the words on his report:
In an audit against the project programming standards this program is not very good however, in the auditors opinion, this is one of the best written and documented programs of all those examined.
If project standards are supposed to identify 'best practice', yet I can totally ignore those standards and still produce programs that are visibly superior then what does that say about the quality of those standards?
Some people seem to think that once standards have been published they are set in concrete and cannot be changed. If a new situation arises which was not identified in the standards they expect you to bend your solution to fit the standards rather than adapt the standards to meet the new situation.
Many years ago I worked for a company where each program had a 4-character identifier. As each program could have various files associated with it each file was given a different prefix to denote its type. The file names were therefore in the format 'PPxxxx' where 'xxxx' was the program name and 'PP' was a prefix from the following list:
In those days the jobs were run in batch from a deck of 80-column cards which were fed into the system via a noisy card reader which had a habit of chewing up cards occasionally. Where the deck for a particular job never changed we would save time by storing the cards in a disk file with the prefix 'JS' so that we could initiate the job from the disk file rather than having to feed in the deck of cards. Where a program required different parameters each time we would punch the parameters onto cards, add them into the card deck, then feed the whole deck into the system to run the program.
Then one day I discovered that it would be possible to put these daily parameters into their own disk files and have them included in the jobstream at run time with the equivalent of an 'include from file' command. This meant that all the remaining card decks could be loaded into their own 'JS' files and the variable parameters would be retrieved from a different set of files. The only problem was what name would we give to these new files? After discussing it with the rest of the people in the operations department I came up with a new prefix of 'DT' for data files. Before we could implement this I decided to run the idea past our General Manager. This is roughly how the conversation went:
Me: I want to put all the variable parameters into separate data files with the prefix of 'DT'.
GM: You can't do that.
Me: Why not?
GM: It's against the standards.
Me: Then change the standards.
GM: Only the Standards Committee can change the standards.
Me: Then get the Committee to change the standards.
GM: We can't. The Standards Committee has been disbanded.
Me: What's your solution then.
GM: Stick with the prefix 'JS', but change the last letter of the program name to make it unique.
What our esteemed General Manager failed to realise was that his solution followed the wording of the standards but violated the spirit in a really big way. The spirit of the standards stated that each different type of file associated with a program used the same 4-character program name but with a different 2-character prefix. Therefore the name of a file would instantly tell you both the name of the program and the type of file. His opinion was 'The prefix DT is not mentioned in the standards therefore it cannot be used'
. Imagine the confusion it would cause if the file 'JSABCD' was not actually the jobstream for program 'ABCD' but actually the data file for program 'ABCC'?
So what did I do? I decided to go with my idea as it was more in keeping with the spirit of the standards. The others in the operations department were happy because it was a logical extension to the standards and made their life easier. I didn't bother telling the General Manager, so he was happily ignorant.
Some people do not like updating their development standards as they think it involves too much effort. They fail to realise that implementing a little improvement here, a little improvement there, will eventually add up to quite a sizable improvement.
One of the little foibles in the block-mode screen handler that we used with COBOL was that when we wanted to set an error flag on a field we had to use the VSETERROR command, and this required the sequence number of the field within that particular form, not its name. This number was given to a field when it was added to the form, and could only be changed if all the fields in the form were resequenced. This was sometimes necessary if you hit the maximum sequence number and you wished to reuse the numbers of fields which had been deleted from the form. This particular area was a problem for programmers and often resulted in the wrong field being flagged with an error.
The development standards on one particular project gave detailed instructions on how to construct arrays which could be used to provide a cross-reference between field names and field numbers. I took one look at this complicated code and went straight to the project leader and asked 'Why use all this code when you can use the
I could see from the vacant look in his eyes that he knew absolutely nothing about the VGETFIELDINFO command instead? You supply it with the field name and it returns you its sequence number. You can even resequence a form without having to change any code.'VGETFIELDINFO command and what it could do. I asked him if he thought that my idea was a better solution to the problem, but he was having nothing of it. Among his excuses he said:
I think that what he was really trying to say was: 'I don't like it because it's not my idea'
.
In my long years with one particular software house I created and maintained the development standards for COBOL and later for UNIFACE. My aim was always to assist the developer in producing high-quality software in as short a time as possible. By providing large amounts of pre-tested code in the form of re-usable components (subroutines, global procs, pre-compiler directives, component templates, and a standard menu and security system that could be used for any application) I have been able to keep these components up-to-date with new ideas or new functions with little or no impact on other developers. It did not matter where the idea came from - it may have been my own idea, it may have come from a colleague, or it may have been something that I read - if it was a good idea I would always look for a way to incorporate it into my standards. A constant flow of little improvements should be treated as investments that will eventually save a fortune.
For example, in the 1980's our hardware manufacturer moved from a Complex Instruction Set (CISC) to a Reduced Instruction Set (RISC), which meant changes to the COBOL compiler and the object linking mechanism. However, due to the nature of my development environment I was able to hide the changes in the standard libraries so that they were totally transparent to the developers. They would simply write their code in the same way, then either use one set of jobstreams to compile it with the CISC libraries or another set to compile it with the RISC libraries in order to produce the desired format for the customer. There was no messing about with two different versions of the application source code, just two different versions of the standard libraries. This was something that, to my knowledge, no other company achieved. They had to manually convert each program from CISC to RISC, which resulted in two different versions of the same code. This is not a very good idea if you are attempting to maintain a software package which some customers want in CISC format while others want it in RISC format.
Because I constructed my UNIFACE development standards in a similar fashion, when UNIFACE 7 was released in 1997 I was able to update my version 6 standards relatively easily. This enabled me to produce pure version 7 software within months of it being released. Compare this with some companies which, even though they are compiling in version 7 are still writing version 6 code some 4 or 5 years later. At least this is better than one company I know of which could not make the move from version 6 to version 7 - their standards were so out of date that some of their key components were just too large to compile in version 7. Unlike them I have been able to move from version 6 to version 7 quite easily. I have also been able to update my standards from 2-tier to 3-tier as an aid to producing client/server systems that can easily be web-enabled without a total re-write. This is all down to having an entire layer of business components that can be re-used by any number of different presentation layers.
You may not believe it, but it is possible to have rules in the development standards which make it difficult or even impossible to use some of the standard functionality within the development language, thus making the developer's job harder instead of easier.
One such area I frequently encounter is with naming conventions which make it difficult to use the list processing functions that UNIFACE provides. In case you are unaware of the features of UNIFACE lists here is a brief outline:
A list is a string item where entries are separated by '<GOLD>semicolon'. A list can be in one of two formats:
"value1;value2;...;valueN". Individual values can be referenced by their position or index number."name1=value1;name2=value2;...;nameN=valueN". Individual values can be referenced by their names.The contents of lists can be manipulated using various commands:
putlistitems - will put groups of items into a list.putitem - will put a single item into a list.getlistitems - will get groups of items from a list.getitem - will get a single item from a list.You can copy the entire contents of one occurrence of an entity into another using code such as this:
putlistitems/occ $List$, Entity1 ; copy contents of Entity1 into $List$ getlistitems/occ $List$, Entity2 ; copy contents of $List$ into Entity2
Here is how I get a parent form to pick up the primary key values for a selected occurrence so I can pass those values to a child form:
$$params = $keyfields("<entity>",1) ; create indexed list identifying primary key
putlistitems/id $$params ; insert representations (values)
activate $child_form$.EXEC($$params) ; pass selection to child form
Here is how I get the child form to retrieve the occurrence selected in its parent:
params string pi_params : IN endparams clear/e "<entity>" getlistitems/occ pi_params, "<entity>" ; use pi_params as retrieve profile retrieve/e "<entity>"
Note that the above two code samples do not care how many items make up the primary key, so this will cater for both single-item and multi-item (compound) keys.
Where items in the list have the same names as global or component variables I can copy the item values from the list to those variables using one of these commands:
getlistitems/id/global pi_params ; copy into global variables getlistitems/id/component pi_params ; copy into component variables
All the examples above show how you can move data into and out of lists quite easily, and even pass lists between one component and another. The beauty of the getlistitems and putlistitems commands is that they can transfer numerous items of data into and out of entities, into and out of global variables, or into and out of component variables without having to specify individual items names. Provided that items with the same names exist in both the source and target areas then the values will be copied. I have thus been able to build these commands into my component templates so that developers can build components from them and achieve the desired results without having to make any modifications to the standard code.
However, this functionality relies on the fact that where an item exists on more than one entity, or has been defined as a global or component variable, it has EXACTLY the same name. If the names are different IN ANY WAY then you will not be able to transfer groups of items using the getlistitems and putlistitems commands, instead you will have to do it one item at a time using the getitem and putitem commands to translate item names between the source and the destination.
'How can naming conventions affect this functionality?'
I hear you ask. Here are some of the examples that I have encountered in my long experience:
I discovered that item (a) was introduced so that field names could never occur on more than one entity, therefore could be coded simply as "fieldname" instead of "fieldname.entname", thus removing any possible ambiguity. When I examined their code I also found that different programmers had variously defined customer identity as AAA_CUSTOMER, AAB_CUST, AAC_CUSTNO and AAD_CUST_ID, so it was not just the prefix that had been changed to make each field name unique.
Item (d) was introduced in the days of UNIFACE 6, so when UNIFACE 7 came out and "local" variables were renamed as "component" variables to make way for the "new" local variables this caused some confusion. They then decided that the "new" local variables should have the prefix of "TV_" just to tidy things up.
Item (e) was introduced in the days of UNIFACE 6 when global variables were used in great numbers to pass values between one component and another. It caused problems when a field that was originally specified as being numeric had to be changed to a string when it came to user acceptance testing - it transpired that the user wanted to input non-numeric characters into the field.
I have always worked on the assumption that each item or object has its own name, and wherever that item appears it will have exactly the same name. It just seems like common sense to me. Thus the primary key of entity PERSON is PERSON_ID, not just ID on its own, and the primary key of entity PERS_TYPE is PERS_TYPE_ID, not just ID on its own. This means that if I relate PERS_TYPE to PERSON then the foreign key which points to PERS_TYPE has exactly the same name as the primary key of PERS_TYPE. If both primary keys were called ID then the foreign key would have to be changed because of the conflict, therefore would no longer have the same name as its primary key counterpart.
If every primary key were to be called ID then an associative list containing 'ID=123' would have no built-in context as it could be used to retrieve totally unrelated occurrences from different database tables. By using unique names for each primary key, and by using the same name where one is used for a foreign key, then a list containing 'PERS_TYPE_ID=123' can only be used to retrieve occurrences from those entities which contain the field PERS_TYPE_ID.
The only valid reason for altering an item name is in the situation where you need to hold two separate values within the same entity, in which case I would add a meaningful suffix. For example, if I need to record the transfer of something between one person and another I would use names such as PERSON_ID_FROM and PERSON_ID_TO. If I wanted to record relationships in a hierarchy I would use names such as PERSON_ID_SNR and PERSON_ID_JNR. By adding a meaningful suffix instead of changing the name entirely I am indicating that the item PERSON_ID_(FROM)(TO)(SNR)(JNR) is a variation of PERSON_ID.
'So what is the problem?'
I hear you ask. Depending on the naming conventions the developer may be able to achieve certain objectives the easy way, or he may be forced to do it the hard way. The hard way requires more coding effort - this means more time, more expense, and a greater potential for bugs.
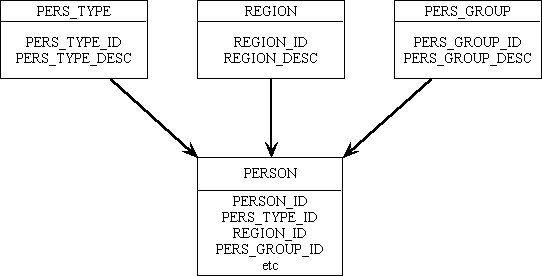
The entity structure shown in Figure 1 allows data to be put into and retrieved from lists by using standard code that can be inherited from component templates and used without any modification:
Figure 1 - friendly names
With the structure shown in Figure 1 there are 3 separate forms which view the contents of entities PERS_TYPE, REGION and PERS_GROUP respectively. Within each of these forms I can select an occurrence then press a button that will pass the primary key of that occurrence to a fourth form that will display those occurrences of PERSON which match that selection criteria. You will notice here that each primary key is in the format '<entity>_ID' so the same exact name can be used when that field is also used as a foreign key in the PERSON entity.
When the button is pressed in any of the first three forms this standard code can be performed to extract the primary key details and pass them to the child form. The passed parameter will contain something like 'PERS_TYPE_ID=123', 'REGION_ID=123' or 'PERS_GROUP_ID=123'.
When the child form is activated this standard code can be performed to retrieve those occurrences that match the passed profile. Notice that the contents of the passed parameter do not need any further processing before being used, therefore the identity of the form which created that parameter string is totally superfluous.
This simple approach is totally destroyed with the naming conventions shown in Figure 2:
Figure 2 - unfriendly names
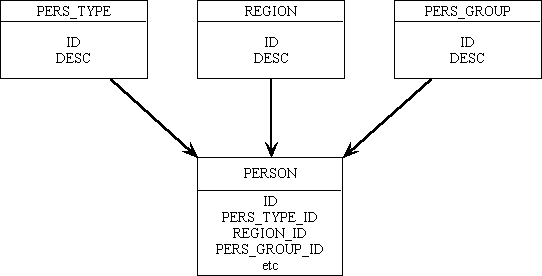
Here the primary key of every entity has the name ID. This may seem a good idea to some people as it means that the primary key of any entity can be extracted with the same piece of code:
putitem/id $$params, "ID", ID.<entity>
Of course this code will not be enough if the entity has a compound key.
The main problem is that where a field is used as the primary key of one entity it has to change its name before it can be used as a foreign key on any other entity. This means that the child form now has to process the passed parameter in some way before it can be used. If it receives the parameter 'ID=123' and uses this standard code it will simply retrieve the occurrence of PERSON where ID.PERSON = '123'. Code will have to be inserted into the child form that will convert the name ID into PERS_TYPE_ID, REGION_ID or PERS_GROUP_ID depending on the name of the parent form.
Here are some simple naming rules that I have followed for many years without causing any conflict with any development language that I have used:
Rule (1) means that if different objects both require a field with similar attributes then each occurrence of the field should have a name that ties it to one object. This is especially important if each occurrence of the field has a different set of values depending on its parent object. As an example the CUSTOMER and INVOICE objects both require a field to hold the object's status, therefore it would seem reasonable to give both fields the name of STATUS. After all, when qualified with the object name, such as STATUS.CUSTOMER and STATUS.INVOICE, the names are unique. I once fell into this trap with a development language that insisted on using fields with identical names when performing a join between an outer and an inner entity. As both the CUSTOMER and INVOICE entities had a field called STATUS, but which contained different values, this caused the join to fail. The problem could only be resolved by giving each instance of STATUS its own name, such as CUST_STATUS and INV_STATUS. The only exception to this rule is where data is required for internal purposes, such as CREATED_DATE, CREATED_BY, AMENDED_DATE, AMENDED_BY, etc. These could appear on any number of different database tables without causing confusion.
Rule (2) helps developers to identify the primary field simply by looking at an entity's field list. They do not have to go into the separate Key Field screen and waste valuable time. The use of the common name 'ID' for all primary key fields would violate Rule (1) and Rule (3).
Rule (3) means that a developer could be made aware of any relationship just from the item names contained within an entity. Anything named as '<thisentity>_ID' would obviously be the primary key of <thisentity>, whereas an item named '<someotherentity>_ID' would obviously be a foreign key which points to <someotherentity>. If all primary keys were called 'ID' then in a one-to-many relationship the foreign key field on the 'many' entity could not be called 'ID' as it would conflict with the primary key of that entity. By changing the name of the field when it becomes a foreign key you are introducing an unnecessary level of complexity and a possible source of confusion.
Rule (4) can be applied to global and component variables. You can define a database item called 'name', a global variable called 'name', and a component variable called 'name'. UNIFACE allows this to be done as they are each defined in their own separate domains within the repository. There is no conflict when you come to refer to them within code as the use of '$' signs is used to indicate the domain:
By not changing item names when they are used in global or component variables it means that the getlistitems and putlistitems statements with the /id/global and /id/component switches can be used to transfer values between lists and global/component variables without the need for any translation.
Rule (4) also applies to field interface, syntax and layout templates. Each of these is defined within its own unique area within the repository, and is also referenced in a unique area, therefore there is absolutely no conflict with other objects of the same name. For example, it is possible to create a field interface template, a field syntax template and a field layout template all with the same name. When each of these objects is referenced (see Figure 3) there is absolutely no possibility of confusion, therefore the use of 'FI_', 'FS_' and 'FL_' as a prefix is superfluous, redundant, and a total waste of time. It is also a waste of three characters in a name which is already restricted to 16 characters.
Figure 3 - Referencing Field Templates

Rule (5) can be applied to message file entries. It is good practice to retrieve text from the message file using some sort of identifier rather than having that text hard-coded within individual programs. This makes it easier to change the text at any time without having to change and recompile any programs. It also makes it easy to have different versions of the text available for different languages. You may wish to store different types of text in the message file which are related to the same object, but you cannot use just the object name as the identifier because each identifier must be unique and can therefore only be used once. The only solution is to add something to the identifier which indicates the text type with which you are dealing. For example, your system has a form called ABCDEF, and you want to store the form title, button text and hint text for that form in the message file. You cannot use the identifier of 'ABCDEF' for all three items, so you add a prefix for each text type. This results in various different identifiers such as the following:
You can instantly see that each of these entries is associated with object 'ABCDEF', and the type of association is given in the prefix.
Rule (6) covers parameter and local variable names. It is possible to have entries within the params...endparams or variables...endvariables blocks which coincide with names of database fields. If you refer to a field as 'name' rather than 'name.entity' this could cause problems as UNIFACE will assume that you are referring to the parameter or variable rather than the field. To avoid any possible confusion I use a different prefix for parameters and variables to indicate their domain. Some people use just 'p_' for parameters, but I prefer to use 'pi_' for parameters of type IN, 'po_' for parameters of type OUT, and 'pio_' for parameters of type INOUT. Some people use just 'v_' for local variables, but I use 'lv_'. An example of the difference this makes is shown below:
params string pi_TOM : IN string pio_DICK : INOUT string po_HARRY : OUT endparams variables string lv_tom numeric lv_dick, lv_harry endvariables lv_tom = pi_tom tom.entity = pi_tom retrieve/e "entity" if (pio_dick > dick) dick = pio_dick endif ...
Rule (7) can be applied to field templates. I have come across more than one organisation where they insist on having a separate interface, syntax and layout template for each field where the template name is exactly the same as the field name. This actually causes the following problems:
Figure 4 - Separate templates for each field
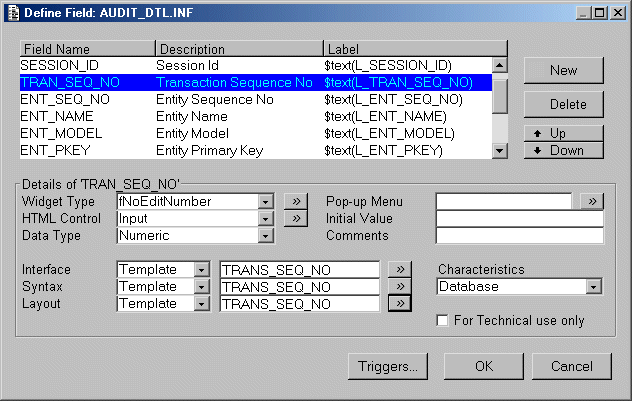
The problem with this approach is that in order to discover the contents of each template it means an extra 3 keystrokes to get into each template definition screen, plus even more time to locate the desired entry. Repeat this process for each of the 3 template types and you see how much time is wasted in finding imporant information.
If you produce entity listings from your repository these will contain the same information that is displayed on the screen. You will need separate listings to identify the contents of the various field templates - another time waster.
The reason I was once given for this ridiculous approach was that it made the process of changing the characteristics of an individual field an easy process - just go to the field's template definitions and change them. However, in my long experience I have found that it is just as quick to use Goto->Administration->Global Updates->Fields. This achieves the same result in almost the same amount of time, but means that you can see all a field's characteristics in a singe screen instead of being forced to visit multiple screens.
This usage of field templates accumulates the following list of black marks:
The overall effect of this is to waste time instead of saving it, to make the developer's job harder instead of easier.
My preferred approach is exactly the opposite:
An example of this is shown in Figure 5.
Figure 5 - Shared Templates
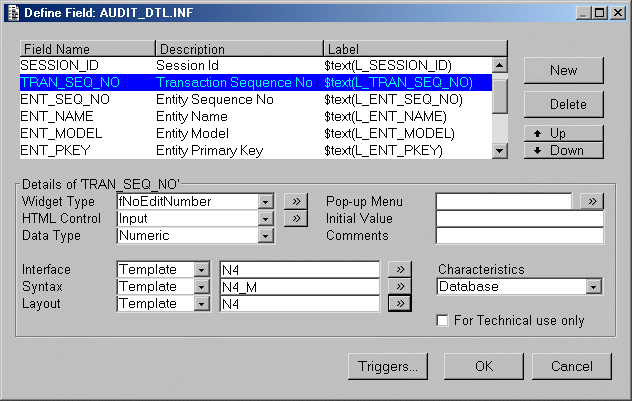
Here you can see that the template names and the field names are not related. By using sensible naming conventions for these templates they become easy to memorise. For example:
Which would you rather use - names with no meaning, as shown in Figure 4, or names full of meaning? The choice is yours. You know who to blame if you make the wrong one.
In the scientific world 'efficiency' can be expressed as 'the ratio of useful work performed to the total energy expended'. Another way of putting it is 'to achieve an objective with the minimum of effort'. Just as users of computer systems like to be able to achieve their objectives with the minimum of key strokes or mouse clicks, it should be the developer's wish to provide functionality with the minimum lines of code. Yet some standards are written in such a way as to force the generation of custom code, or which prevent the use of centralised routines.
I remember one UNIFACE project where the standards stated that the screen labels for database fields should be taken from the message file rather than be hard-coded within each form. A very laudable statement, but where it fell down was in the implementation. It was decided that the identity of each field label in the message file was to be in the format L_<formname>_nnn where 'nnn' was a 3-digit sequence number. This meant that each time a form was created the developer had to create a separate message file entry for each field on the form, then amend the properties of each label so that it contained the identity of the corresponding message file entry. Not only did this require quite a lot of effort on the part of the developer, it also meant that each field had a totally separate message file entry for each form in which it appeared. As well as increasing the size of the DOL (Dynamic Object Library) file it also increased the amount of effort needed to change a field's label as there was a separate label for each form.
I developed an approach that required considerably less effort. I decided that each field should have the same label regardless of how many forms it appeared on, which required only the following steps to implement:
L_<fieldname>.$text(L_<fieldname>).Both methods provide field labels from the message file, but one requires less developer effort to implement than the other, therefore is more efficient. If this is the case how can you possibly justify using a less efficient method?
On the same project it was decided that each form would have a series of command buttons down the right-hand side which would allow the user to navigate to another form. These were called navigation buttons. When a button was pressed it would pass the current context to the new form as the primary key of the current occurrence. The text for each button would be retrieved from the message file using an id of B_<formname>. This required the following steps to implement:
button_nn.navigation_bar = $text(B_<formname>).After using this method for some while I could see room for improvement, so I devised a method which totally eliminated steps 2 and 3. How is this possible? By automation. I decided to include the dummy NAVIGATION_BAR entity in the application model and include a separate button for each component that could be activated that way. The name of each button would be the same as the component to which it referred rather than a random sequential number. This simple change meant that I could now insert the correct text into each button by using a global proc instead of manually inserting a line of code. This proc (called NAV_BUTTONS) contains the following:
$entinfo function with the paintedfields option to obtain a list of fields within the NAVIGATION_BAR entity of the current component.$text(B_<button>).Not only did the developer not have to manually set the label for each button, he did not even have to remember to call the NAV_BUTTONS proc as this was automatically included from the component template.
I also eliminated the need to manually change the code in each button's <DETAIL> trigger. I created a field template that would automatically set all the properties for these navigation buttons, and which also contained the following standard trigger code:
$$component = $fieldname $$instance = "" $$properties = "" $$operation = "" call LP_PRIMARY_KEY call ACTIVATE_PROC
The name of the component to be activated is taken from $fieldname, so no intervention is required from the developer. The local proc LP_PRIMARY_KEY is responsible for extracting the primary key from the current occurrence, and as this is inherited from the component template no intervention is required from the developer. All the code to activate the component is held in global proc ACTIVATE_PROC, so again there is no intervention required from the developer.
The ability to perform common functions by using central procedures instead of manually-inserted code is a productivity device that I have been actively employing for over 20 years. Not only does it save valuable developer time when initially building components, it also makes it much easier to implement enhancements across the entire system at a later date.
For example, with one of my customers not all of his users had access to all of the components available within the system, so if a user did not have access to a component indicated on a navigation button he wanted that button flagged in some way so the user would know not to waste time selecting it. Because of my approach I was able to implement this change by modifying a single global proc instead of multiple forms. I simply included the necessary code in the NAV_BUTTONS proc to check the user's access for each button against the contents of the security database, and if access was denied I used the field_syntax command to dim the button. Not only did this present a visual clue to the user that the component behind the button was not available to someone of his/her security level, it also disabled the button's <detail> trigger, thus preventing anything from happening even if the button were to be pressed. Could you make such a change as easily in your system?
I have come across instances where statements which may have merit in certain circumstances are subsequently built into development standards as if they should be employed under all circumstances. As someone once said to me 'This idea got me out of a particular problem once, so if I use it all the time I will never have that problem again'.
Unfortunately this attitude can sometimes lead to unforeseen problems in other areas.
Everybody knows that each database table needs a primary key, but there are some questions that need to be asked before the best key fields can be identified:
A semantic key is one where the possible values have an obvious meaning to the user or the data. For example, a semantic primary key for a COUNTRY entity might contain the value 'USA' for the occurrence describing the United States of America. Country codes are commonly used as abbreviations for a country's full name.
A technical key (also known as a surrogate key) is where the possible values have no obvious meaning to the user or the data. Technical keys are used in circumstances when the data values cannot be guaranteed to be unique, or where when there is the possibility that the values may change over a period of time. In these circumstances an extra field is added as the primary key, then filled with a value that can be guaranteed to be unique and unchangeable. For example, when a new customer is added to the system the primary key CUSTOMER_ID is used rather than any part of the customer name. The value for CUSTOMER_ID is taken from a range of centrally-held sequence numbers which is then incremented, so each number can only be used once. So if a customer has a CUSTOMER_ID of '1234' the value '1234' has nothing to do with any data supplied by the customer - it just happened to be the next available number at the time the customer's details were input.
In the circumstances where the value of a potential primary key cannot be guaranteed to be stable, or where the number of fields needed to obtain a unique value is excessively large, the solution is to add an extra field to the table as a technical primary key. Unique values for this technical key are then generated by the system rather than input by the user. Some database designers think that this solution is so good that it can be used on every database table they design, but they fail to realise the impact that it can have further down the line.
Take the example I encountered recently in a sales order processing system. In this system there were CUSTOMERS who made ORDERS. Each ORDER was comprised of one or more UNITS, and to each UNIT there could be a number of ACCESSORIES. The database design that was used is shown in table 3:
Table 3 - their data model
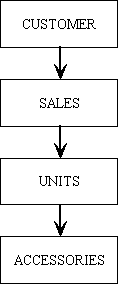 |
PK = CUSTOMER_ID |
| PK = SALES_ID FK = CUSTOMER_ID |
|
| PK = UNIT_ID FK = SALES_ID |
|
| PK = ACCESSORY_ID FK = UNIT_ID FK = SALES_ID |
In all these tables the primary key (PK) values were obtained from database sequences, and were supplied with the command: SQL "SELECT <seq_name>.NEXTVAL FROM DUAL","DEF". Each of the foreign keys (indicated by 'FK' above) required a separate index.
The system was originally designed for customers who mostly bought single units at a time but who would sometimes buy two or three. The number of accessories and options was also quite small. As time went by the volume of business grew and the number of possible accessories and options expanded to a much larger number. When the corporate customers who wanted to purchase up to 500 units at time arrived, this is when the design began to have an impact on response times.
Take for example the scenario where 500 units are bought with an average of 4 accessories and options per unit. Just how many times is that SQL statement called? The answer is 2501 times (1 sale + 500 units + (500 x 4 accessories)). When you consider that in today's world most of the bottlenecks occur with the amount of traffic sent over the network you should instantly see the problem caused by issuing that SQL statement 2501 times.
By adopting a different approach with the primary keys this problem can be reduced enormously. Take the revised data model shown in table 4:
Table 4 - my data model
|
PK = CUSTOMER_ID |
| PK = SALES_ID FK = CUSTOMER_ID |
|
| PK = SALES_ID + UNIT_ID FK = SALES_ID |
|
| PK = SALES_ID + UNIT_ID + ACCESSORY_ID FK = SALES_ID + UNIT_ID |
In this design only SALES_ID is obtained from a database sequence number. Values for UNIT_ID are obtained from a LAST_UNIT_ID field on the SALES entity. The primary key of the UNITS table is a combination of SALES_ID and UNIT_ID. In order to obtain the value for UNIT_ID the following code will be used:
last_unit_id.sales = last_unit_id.sales + 1 unit_id.units = last_unit_id.sales
Values for ACCESSORY_ID are obtained from a LAST_ACCESSORY_ID field on the UNITS entity in a similar fashion. This 'minor' change has the result of reducing the number of SQL statements that are issued from 2501 to just 1. It has an added bonus in that the foreign keys on the UNITS and ACCESSORIES tables do not need to be indexed separately as this functionality is provided by the compound primary keys. As well as saving the space taken up by these indices you are also saving the processor time that would otherwise be needed to maintain them.
More of my thoughts on the use of technical primary keys can be found in Technical Keys - Their Uses and Abuses.
Sometimes I am amazed at how a supposedly intelligent person can take a relatively simple rule and apply an interpretation which is nowhere near what the author intended and end up with disastrous results.
Those of you who design databases should be aware of the rules of data normalisation (1st Normal Form, 2nd Normal Form, et cetera). One of these rules is that you should not hold a value in a record which can be derived from other values in the same record. For example, in a sales system you can have NUMBER-OF-UNITS, UNIT-PRICE and EXTENDED-PRICE where EXTENDED-PRICE is the product of the other two. It is quite clear that it is not necessary to hold all three as one of them can be recalculated, but which one is it safe to drop? Considering that you start with UNIT-PRICE and NUMBER-OF-UNITS and calculate EXTENDED-PRICE it should be obvious that you drop EXTENDED-PRICE and recalculate it whenever necessary.
I once had a project leader who reckoned that it was more efficient to keep EXTENDED-PRICE and calculate UNIT-PRICE instead as EXTENDED-PRICE was referenced more frequently. This did not matter too much in this instance as both values had the same number of decimal places, but his logic came to grief on the next project which was a multi-currency accounting system. In this case there was HOME-CURRENCY-AMOUNT and FOREIGN-CURRENCY-AMOUNT both with 2 decimal places and an EXCHANGE-RATE with 9 decimal places. Which value can be dropped from the database and recalculated to the correct degree of accuracy? He did not realise his mistake until he came across the requirement to take the exchange rate when the invoice was raised and calculate the profit or loss using the exchange rate when the invoice was paid. He tried to explain it away as simple rounding errors, but the accountants knew better.
Believe it or not the same project leader made a different mistake with exactly the same rule on exactly the same project. Everybody knows that this rule only applies at the record level, but he was convinced that it should also apply at the table level. He decided that it was not necessary to hold the account balance on the account header record as it could be derived by adding up all the debits and credits posted to that account. When there was only a small number of records in the test database the overhead of calculating the account balance each time was barely noticeable, but when the system went live and the number of transactions grew day by day the client did not take long to notice that his system was running slower and slower.
Rules or guidelines should not be incorporated into the development standards on a whim. They should only be included after being evaluated with questions such as these:
If it can be shown that a rule does not meet its objective, does not solve the stated problem, or is not the best of the possible solutions, then it should be discarded in favour of one that does.
You have to bear in mind that some rules, when looked at in isolation, may not appear to be the most efficient solution to the stated problem. This is probably because they are there to help in another area, either to solve a problem in that other area, or to provide extra facilities in that other area. A typical example is error reporting. If a program fails it is not very helpful if the error message does not contain enough information to help the developer identify and fix the fault as quickly as possible. The type of information that would be useful would include the following:
When a program works all the coding which provides this information is unused and therefore may appear to be redundant. But if the program fails for some reason then all this information is worth its weight in gold!
As well as scrutinizing each statement when it is originally inserted into the development standards, you should be prepared to re-evaluate each statement following the release of updated versions of the development tools. What may have been satisfactory in UNIFACE 6 may be totally out of date in UNIFACE 7. What may have worked in UNIFACE 7.1.01 may have been improved or even superseded in version 7.2.06.
I was once told by someone 'You can't use that technique because it's inefficient'
. When I asked him to provide some sort of proof to justify that statement he could not. His only response was 'I read it somewhere'
. After a lot of digging I discovered that the statement was written about an earlier version of the development tool running on much slower hardware, but when tested on the current versions the difference had disappeared. That statement had passed its sell-by date and was no longer relevant, yet that particular developer was still sticking to it, which meant that his method was now the least efficient.
I was once asked by someone to help them out with a coding problem. After proposing various solutions, only to have the scope of the problem enlarged each time, I was calmly told that it was not possible to change the code in the <read> trigger from that which had been defined in the application model. When I asked why I was simply told 'Because our development standards say so'
. He was unable to give me any justification for this restrictive rule, so I declined to give further assistance. I have been programming in UNIFACE since 1993, and as far as I am aware the application model is used for defining the default or most common settings - it may be necessary to change from the defaults within individual forms because the circumstances warrant it. If a restrictive rule such as this cannot be justified to my satisfaction then I have no qualms in ignoring it completely. If the author of such a rule complains then get him to solve the problem himself.
I have come across more than one set of standards which insist on dictating what case to use when coding, such as:
If the language itself is case insensitive and does not care which is used, then just what is the justification for such a pointless rule? Among the explanations I have been given are:
Personally I think the real reasons are more like any of the following:
In my long years of experience I have noticed that when standards are filled with trivia such as this they are also devoid of those items which are actually important to the developer, those items which promote high quality code and high rates of productivity. Pointless rules, especially those which contradict a developer's previous experience, actually have a negative effect as they introduce frustration and slow down the rate of productivity.
I have worked with several companies which, after many years with one development tool, decided to replace it with a more modern alternative. The reasons may be any one of:
The IT departments concerned have run for years using a set of standards, and it is tempting to try and carry forward as much as possible for use with the new language. This is usually out of pure laziness - they don't have the time to create new standards, and they don't want to spend time in retraining their existing staff as it may confuse the poor dears.
Although the old standards may appear to work with the new tool be warned that they may reduce its effectiveness. Allow me to demonstrate with an analogy. A man decides to replace his old vehicle with a new one. He is impressed with the adverts for one particular vehicle which claim that it can cruise all day at 120mph. He buys it, but several weeks later he takes it back to the showroom complaining that he is unable to achieve a speed which is anywhere near 120mph. Upon investigation the salesman discovers that there is no fault with the vehicle at all - it is the owners driving habits which are to blame. These consisted of:
The conversation between the salesman and the owner went something like this:
So, what may work with one vehicle (or programming language) may be totally inappropriate for another. They each may be designed for different markets, or to achieve different results, so new techniques may have to be learned. It you do not learn how to use the tool properly then is it right to blame the tool if it does not perform to your expectations?
I once had a manager who told me 'There is no such thing as 'bad' standards. There is only a problem when somebody doesn't follows the standards'
. My experience says that he is totally wrong. I have encountered some standards that have actually taught me how to write better programs, while others have positively prevented me from writing programs of an acceptable quality and within acceptable timescales. Standards that do not identify and encourage 'best practice' should have no place in today's fast-moving world.
Years later I had a manager who resisted any change to his standards. 'We've always done it this way and it has never been a problem'
. That attitude always reminds me of the dinosaur. The reason that he didn't know that it was a problem was that he had never taken the time to investigate new or different methods, so he had nothing to compare against. It is only by comparison with an internal combustion engine that you realise that your steam-based technology is slow, inefficient and messy.
I have spent most of my development career in software houses where the ability to write high quality software in a short space of time was necessary to compete against rival companies. Winning a contract is just the start - you still have to complete the project on time and within budget otherwise you run the risk of going out of business. The only way to combine quality and speed is with development standards that are designed specifically with quality and speed in mind. As the Team/Project Leader on a succession of projects I was able to take the lessons learned on one project and carry them forward into the next one. I never let the grass grow under my feet and was always looking for improvements, and if a really good idea came along I was not afraid to take the time to retro-fit it into existing programs. I always saw this as an investment that would pay dividends later on, and it very often turned out to be the case. This attitude has resulted in a set of standards that enable developers to be highly productive, much more so that with any other standards I have seen.
There are some people who say that standards that are too comprehensive can place too many restrictions upon the developer. It is my contention that, provided that the standards are based on sound principles, common sense and logic, and are flexible and open to improvement instead of being rigid and closed to new ideas, then they should provide a solid foundation on which the individual can build rather than a ceiling above which the individual cannot progress. Proper development standards should be an inspiration, not a limitation. They should promote quality, not mediocrity.
Tony Marston
1st August 2002
mailto:tony@tonymarston.net
mailto:TonyMarston@hotmail.com
http://www.tonymarston.net
| 22nd Jan 2005 | Added section 2.11 Don't reuse standards from previous tools. |
| 20th Sept 2003 | Added section 2.9 Don't misinterpret the rules. |
| 14th Aug 2002 | Added section 2.7 Be efficient, not deficient. |